






“啤酒和尿布的荣誉”
概念
- 项 item:单个的事物个体 ,I={i1,i2…im}是所有项的集合,|I|=m是项的总数
- 项集(item set)/模式(pattern):项的集合,包含k个项的项集称为k-项集
- 数据集(data set)/数据库(data base):D={T1,T2,…Tn}是与任务相关的数据库事务/记录/交易的集合,每个事务有一个标识符,称作TID。|D|=n为数据集中包含的事务总数。
- 支持度support :项集的出现频率(0~1)/比例(绝对数)
- 置信度/可信度(confidence):在D中的那些包含A的事务中,B也同时出现的条件概率P(B|A)=P(AB)/P(A)
- 频繁项集(frequent itemset)/模式(pattern):项集的支持度>=最小支持度(min support)
- 关联规则(association rules):关联规则是形如A=>B的蕴含式,具有支持度s=support(A ∪ \cup ∪B),c=confidence(A=>B)=P(B|A)=support(A ∪ \cup ∪B)/support(A)
- 强规则:同时满足最小支持度和最小置信度的规则称作强规则。关联规则发掘分为两步:
- 找出所有频繁项集
- 产生强规则
例子
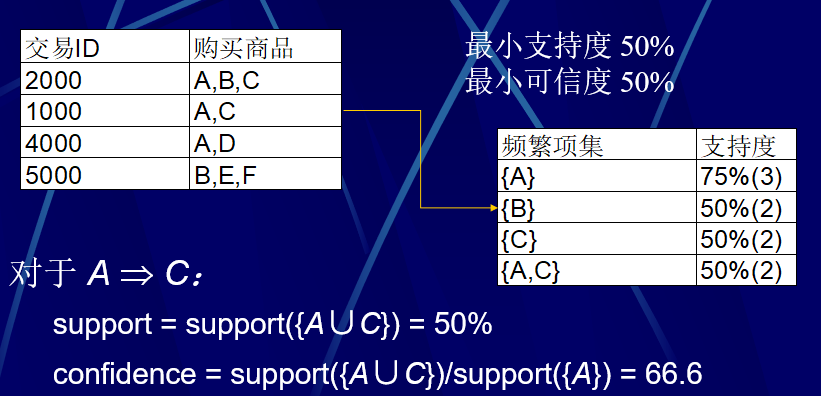
结论与注意事项
1.非频繁项集的超集都是非频繁的
support(y)<=support(x)<min_sup
y=x
∪
\cup
∪其他
2.频繁项集的子集是频繁的
1.强规则不一定有价值
2.相关分析:corr(A,B)=P(A
∪
\cup
∪B)/P(A)P(B)
正相关>1,负相关<1,独立=1
问题分类
根据规则中所处理的值的类型分类:
- 布尔关联规则(boolean association rule):规则考虑的关联是项的在与不在
- 量化关联规则(quantitative association rule):规则描述的是量化的项或属性之间的关联
根据规则中所涉及的数据维数分类:
- 单维关联规则(single-dimensional association rule) :规则中的项或属性每个只涉及一个维
- 多维关联规则(multi-dimensional association rule):规则涉及多维度
根据规则中所涉及的抽象层分类:
- 单层关联规则(single-level association rule):规则不考虑项的分层
- 多层关联规则(multi-level association rule):考虑项的分层 buys(X,milk)=>buys(X,food)
频繁模式挖掘的分类:
- 频繁模式挖掘
- 交互挖掘
- 增量挖掘
- 效用频繁模式挖掘
- 最大频繁模式挖掘
- 频繁闭合模式挖掘
- 并行/分布式挖掘
经典算法
基于候选项生成与测试(candidate generation and test)
非频繁项集的超集都是非频繁的
代表作:apriori(1994)
基于分治的模式增长(pattern growth)
采用分而治之的方法:频繁项集的子集是频繁的
代表作:FP-growth(2000)
Apriori
非频繁项集的超集都是非频繁的
伪代码
C_k=Candidate itemset of size k
L_k=frequent itemset of size k
L_1={frequent items};
for (k=1;L_k!=空;k++)do begin
C_{k+1}=candidates generated from L_k;
for each transaction t in database do
increment the count of all candidates in C_{k+1} that are contained in t
L_{k+1}=candidates in C_{k+1} with min_support
end
return U L_k;
例子图解:
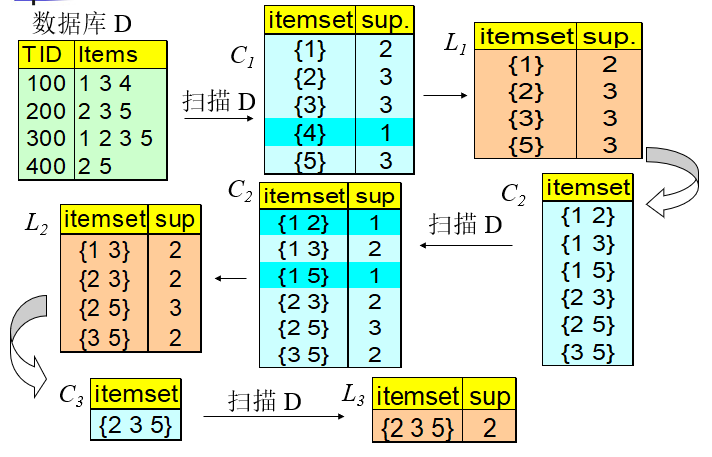
难点:如何生成候选集:
连接: 用 Lk-1自连接得到Ck
修剪: 一个k-项集,如果它的一个k-1项集(它的子集 )不是频繁的,那它本身也不可能是频繁的。
假定 Lk-1 中的项按顺序排列
第一步: 自连接 Lk-1
insert into Ck
select p.item1, p.item2, …, p.itemk-1, q.itemk-1
from Lk-1 p, Lk-1 q
where p.item1=q.item1, …, p.itemk-1 < q.itemk-1
第二步: 修剪
for all itemsets c in Ck do
forall (k-1)-subsets s of c do
if (s is not in Lk-1) then delete c from Ck
例子:

Apriori 的瓶颈: 候选集生成及模式匹配
- 巨大的候选集及模式匹配操作:
1 0 4 10^4 104个频繁1-项集要生成 1 0 7 10^7 107 个候选 2-项集
要找尺寸为100的频繁模式,如 {a1, a2, …, a100}, 你必须先产生 2 100 ≈ 1 0 30 2^{100}\approx 10^{30} 2100≈1030 个候选集,且所有模式都要进行模式匹配操作 - 多次扫描数据库:
如果最长的模式是n的话,则需要(n)或者 (n +1) 次数据库扫描
代码思路:
扫描数据库得到频繁一项集,用dictionary存储项集(key是元组,value是cnt)
用k项集生成k+1项集(自连接),判断k子集是否全为频繁k-项集(剪枝)
对k+1项集扫描数据库,计数,得到频繁k+1-项集
直到n-项集为空
FP-growth
用Frequent-Pattern tree(FP-tree)结构压缩数据库,特点是:
高度浓缩&分而治之
能够有效解决密集数据的问题
《Mining Frequent Patterns without Candidate Generation》Jiawei Han
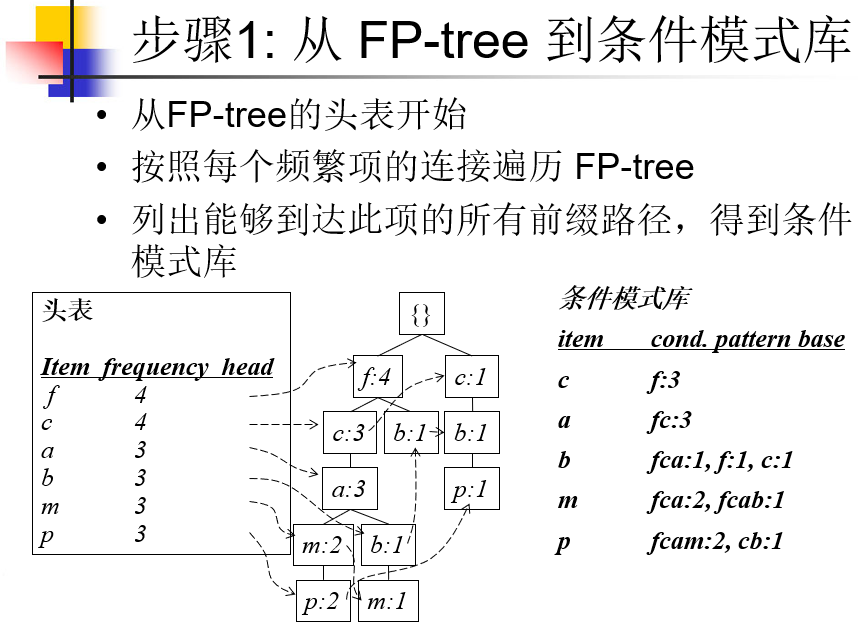
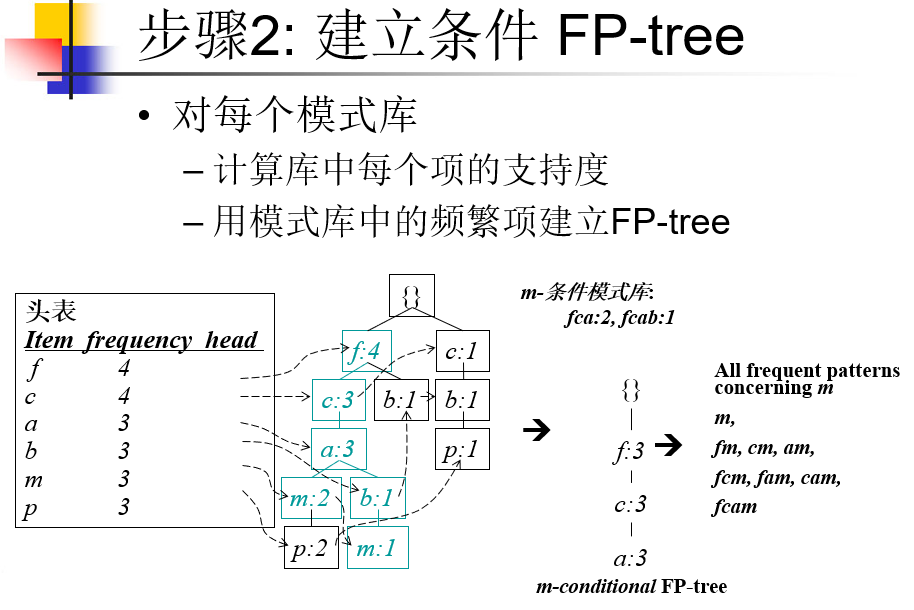
步骤:
扫描数据库一次,得到频繁1-项集,把项按支持度递减排序,再扫描一次数据库,建立FP-tree



FP-growth的瓶颈: 绝对的分而治之
- 生成大量临时子条件模式树:算法将为每个频繁模式生成一棵条件模式树,直到FP-tree出现唯一的路径为止
- 重复地遍历FP-tree:
各个子数据库是有重叠的,但此类算法均没有考虑如何处理计算工作的保存和维护
伪代码1:建立FP-tree

伪代码2:有FP-tree后获得频繁项集
Input: FP-tree constructed based on Algorithm 1,using DB and a minimum support threshold s.
Output: The complete set of frequent patterns.
Method: Call FP-growth (FP-tree ; null).
Procedure FP-growth (Tree; a)
{
(1) if Tree contains a single path P
(2) then for each combination (denoted as b)of the nodes in the path P do
(3) generate pattern bUa with support = minimum support of nodes in b;
(4) else for each ai in the header of Tree do {
(5) generate pattern b = aiUa with support = ai*support;
(6) construct b's conditional pattern base and then b's conditional FP-tree Treeb ;
(7) if Treeb!=0
(8) then call FP-growth(Treeb,b)}
}
代码思路:
需要用到数据结构【链表】、【树】,以及算法【递归】
递归函数Fp-tree construction(数据库,最小支持度(绝对数),之前项集):
- 扫描一遍数据库,得到频繁1-项集,按cnt降序排列,记为L表(实际上是dic,key是频繁1-项集,value是(cnt,指针)元组)
- 建立树的根节点
- 将每条记录按照L的顺序排列(去掉非频繁项集)
- 再扫描一遍数据库,开始建树,如果树的结点有它就+1,没有就新建一个结点,并且要和前面的指针连上
- 如果树不为空 且 不是单一分支,则:
- 从L的最后往前,对于每个频繁1-项集,通过指针、找父节点,得到它的条件模式库
- 对这条件模式库递归Fp-tree construction(条件模式库,最小支持度,之前项集U该频繁1-项集)
- 如果树为空 或 是单一分支,则:
- 将这条单一分支的项取下来,排列组合,连上传入的(之前项集)参数,作为频繁项集存储
第一次调用函数时,传入(数据库,最小支持度,空集)
















 6728
6728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









