










项目展示:
项目结构:
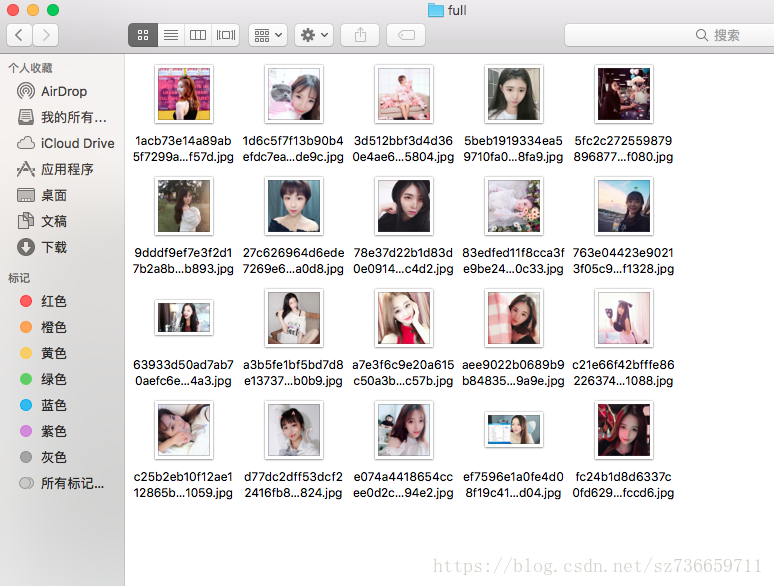
成果:
1.新建项目
- 确保安装了所用到的库 scrapy image Pillow
pip install scrapy
pip install image
pip install Pillow
######################注释###########################(不要粘贴)
pip工具下载
最好在(virtualvenv)里进行安装,便于包的管理,需要了解的可以去百度一下- 创建一个scrapy目录
scrapy startproject douyu
######################注释###########################(不要粘贴)
这是scrapy提供的一个便捷目录框架
'douyu' 可以自定义 这里我用的是'douyu' 你也可以用其他的
cd到你指定的目录下 键入这个命令 便会多出一个'douyu'文件夹- 了解一些爬虫的命令
scrapy list
scrapy crawl douyu
######################注释###########################(不要粘贴)
scrapy list 可以展示出目前可执行的蜘蛛
scrapy crawl douyu 'douyu'是我们蜘蛛的名字,蜘蛛的名字并不是文件的名字那么在哪里取呢?我们在后面可以看到2.项目内容
- 我会列出项目我改变的文件和备注上注释
- 首先在文件夹的items.py中我们新定义一个属于自己的item
import scrapy
class DouyuItem(scrapy.Item):
# 存放图片的url
image_urls = scrapy.Field()
# 存放图片的路径结果
images = scrapy.Field()- 在settings.py中配置我们的蜘蛛(比如说存放路径啊,图片的URL来源,和管道之类)
# 添加以下内容在settings.py
ITEM_PIPELINES = {
# 这句话直接复制,设置我们图片管道的优先级
'scrapy.pipelines.images.ImagesPipeline': 300
}
# 存放图片的路径,要修改成自己电脑下的路径
IMAGES_STORE = '/Users/admin/Desktop/images'
# 图片URL的来源,和我们之前Item的属性统一,个人理解为获取到每个item里面的属性作为url 蜘蛛开始自动请求
IMAGES_URLS_FIELD = 'image_urls'
# 图片的存放路径结果,在url下载成功后保存的位置,也和我们的Item的属性统一
IMAGES_RESULT_FIELD = 'images'
# 保存图片的延迟天数/避免重复下载
IMAGES_EXPIRES = 30- 在我们新建的文件夹里面的spider文件(自带了__init__.py),我们新建一个douyu.py
# 用来解析我们请求成功返回的json格式文件
import json
import scrapy
# 我们的Item(存放自己需要的类似一个字典)
from douyu.items import DouyuItem
class DouyuSpider(scrapy.Spider):
# 这个就是蜘蛛的名字了,也就是我们scrapy list 和 scraply crwal douyu的来由
name = 'douyu'
# 允许的范围
allowed_domains = ['douyucdn.cn', ]
# 偏移量
offset = 0
# 手机端获取信息的json的URL,里面可以返回limit=20(20条数据),从第offset= 开始
base_url = 'http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset='
# 拼接我们的url
start_urls = [base_url + str(offset), ]
# 回调函数 解析数据
def parse(self, response):
content = response.text
data = json.loads(content)['data']
for i in data:
# json格式字段里面的key对应的值
image_url = i['vertical_src']
# 我们先前定义的Item
item = DouyuItem()
# 该字段必须是可迭代对象
item['image_urls'] = [image_url]
yield item
# 这里是可以设置想要获取的多少条,230可改,代表获取230张图片,可以自行设置
# if self.offset < 230:
# self.offset += 20
# yield scrapy.Request(url=self.base_url + str(self.offset), callback=self.parse)
3.执行项目
- 进入到我们的爬虫目录,也就是开始startproject 甚至的目录,我这里是douyu
- 结果如下图
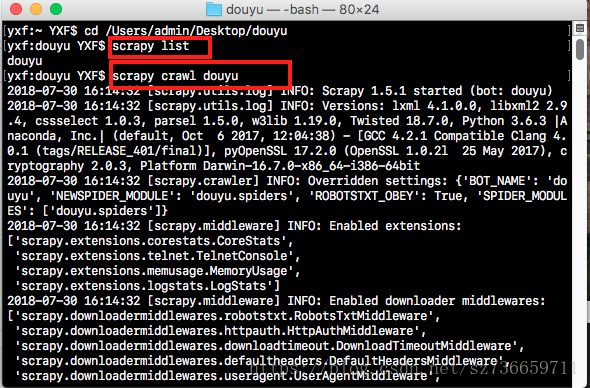
附上源码连接GitHub源码链接
有疑问的可以评论或者联系我














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









