









错误类型:CUDA_ERROE_OUT_OF_MEMORY
GPU的全部memory资源不能全部都申请,可以通过修改参数来解决:
在session定义前增加
config = tf.ConfigProto(allow_soft_placement=True)
#最多占gpu资源的70%
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.7)
#开始不会给tensorflow全部gpu资源 而是按需增加
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
当Host有多个GPU时,如何控制有多少个GPU在工作?
通过配置环境CUDA_VISIBLE_DEVICES来实现
在代码中:
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
os.environ["CUDA_VISIBLE_DEVICES"] = 2
在命令行中:
CUDA_VISIBLE_DEVICES=0 python train.py 注意=号两边不能有空格
GPU训练一段时间之后,温度接近100度,然后罢工,提示GPU从总线上消失。
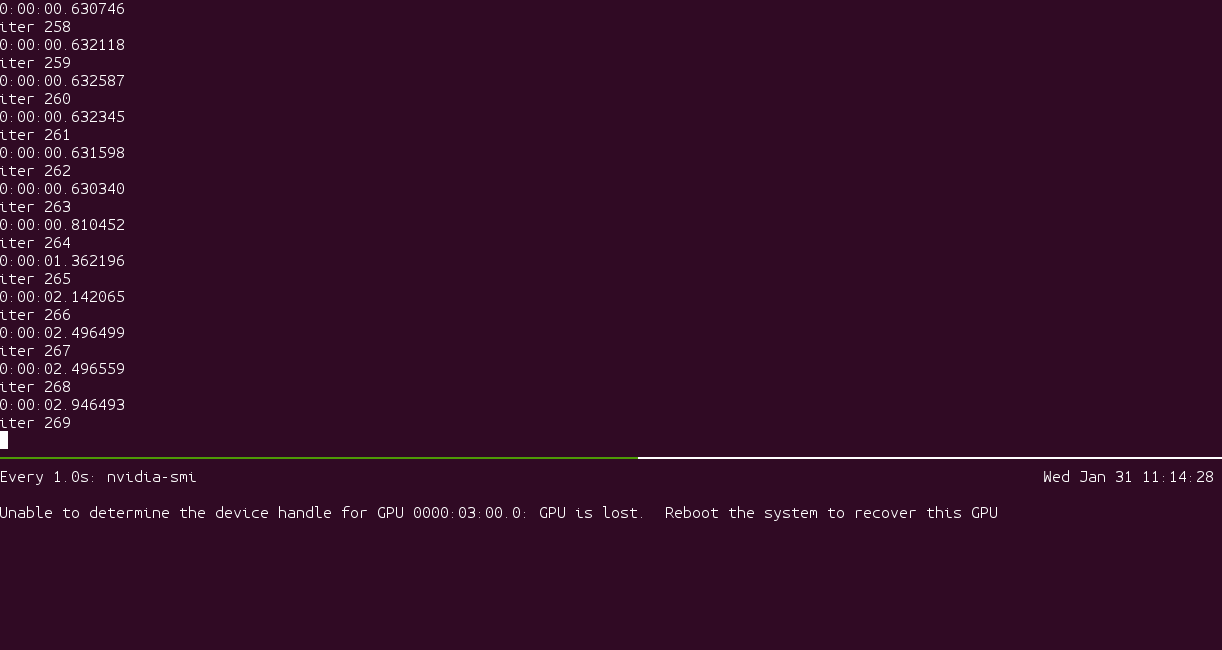
知道目前为止,也没有找到好的办法。















 2281
2281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









