







1、多GPU简单运行
不用修改其他代码,添加几行
#指定你要用的gpu
device_ids = [0, 1,2,3,4,5]
model = torch.nn.DataParallel(model, device_ids=device_ids) # 指定要用到的设备
model = model.cuda(device=device_ids[0]) # 模型加载到设备02、多gpu训练模型,单gpu测试
直接加载模型报错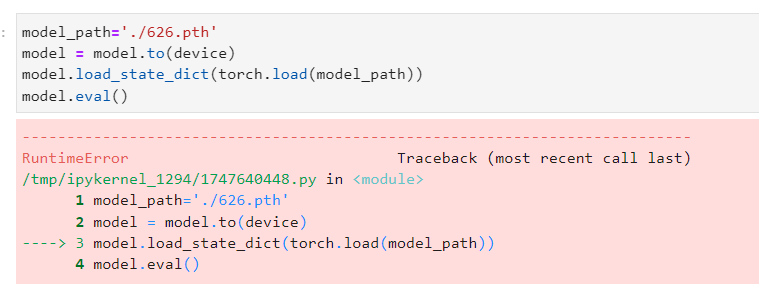
在load_state_dict后加入,strict=False成功运行,但是结果错的离谱,参考这个吧
关于Pytorch加载模型参数的避坑指南_墨晓白的博客-CSDN博客_pytorch load_state_dict的注意点
model_path='./626.pth'
model = model.to(device)
model.load_state_dict(torch.load(model_path),strict=False)
model.eval()解决方法:
查询后发现是模型里多了字符model,我们需要将它删除,左图为多卡训练的模型,右图为单卡训练的模型,可以看到多卡训练的模型直接用torch.save(model.state_dict(),model_path),多了前边的model参数
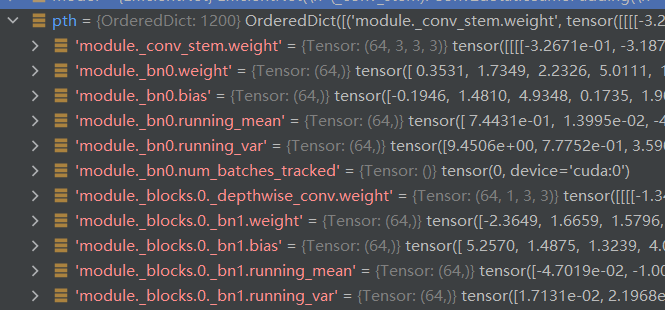
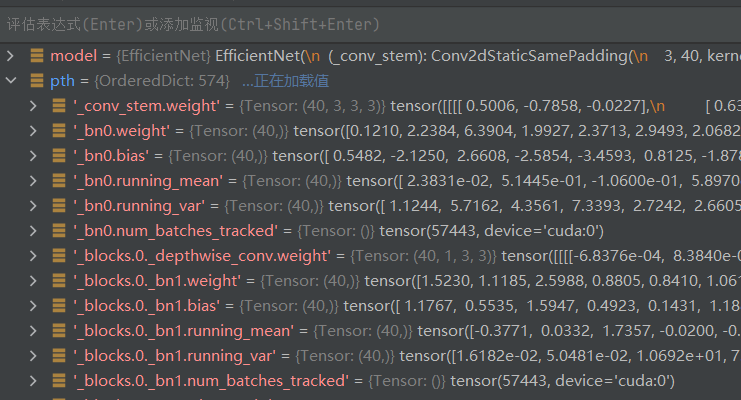
方法一:
# save model
if num_gpu == 1:
torch.save(model.module.state_dict(), 'net.pth')
else:
torch.save(model.state_dict(), 'net.pth')方法二:把训练好的模型里的model字符删除
pth = torch.load('./626.pth')
from collections import OrderedDict
new_state_dict = OrderedDict()
for k, v in pth.items():
name = k[7:] # remove 'module'
new_state_dict[name]=v
model.load_state_dict(new_state_dict)
model.eval()3、多gpu模型,多GPU加载
我这是保存了所有参数方便断点训练,cfg为我的配置文件,more_gpu代表是否为多GPU训练,模型如果是state保存的就直接加载,如果是module保存的,加载时也得用module.load_state加载。
checkpoint = {
'epoch':epoch,
'model':model.state_dict() if not cfg.more_gpu else model.module.state_dict(),
'optimizer':optimizer.state_dict(),
'lr_schedule':scheduler.state_dict(),
'best_acc':best_acc}
torch.save(checkpoint,cfg.checkpoint_path)模型加载
if cfg.resume:
path_checkpoint = cfg.checkpoint_path
checkpoint = torch.load(path_checkpoint)
start_epoch = checkpoint['epoch']
####在这加个判断是不是多gpu
model.load_state_dict(checkpoint['model']) if not cfg.more_gpu else model.module.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
scheduler.load_state_dict(checkpoint['lr_schedule'])
best_acc = checkpoint['best_acc']| [](http://www.relxdingyilang.cn/) | [点击访问博客查看更多内容](http://www.relxdingyilang.cn/) |
|------------------------------------------|-- |

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









