









目录
- 1 opencv环境安装
- 1.1 报错Could NOT find CUDNN (missing: CUDNN_LIBRARY CUDNN_INCLUDE_DIR) (Required is at least version "7.5")
- 1.2 使用camke+vs编译opencv4.8.0,4.6.0
- 1.3 报错'operator !=":重载函数具有类似的转换(编译源文件 H:\opencv-4.8.0\opencv-4.8.0kmodules\dnn\src\layers\normalize bbox layer.cpp)
- 1.4 opencv4.5.5报错texture is not a template
- 1.5 编译成功
- 1.6 opencv4.6.0编译成功
- 2 搭建界面
- 3 按钮初始逻辑编写
- 4 加载YOLOv5
- 线程优化没啥用,不用看了
- 5 使用msvc编译qt程序,编译opencv—cuda加速
github连接,提交记录与章节对应方便代码查看
视频效果
Cpu 运行Qt5.15.2 opencv4.5.2
GPU运行环境 QT5.15.2 msvc2019 opencv4.6.0-cuda vs2019 cuda11.3 cmake3.29(成功)
1 opencv环境安装
直接查看QT人脸考勤那一章编译opencv,将头文件和lib文件导入
win32
{
INCLUDEPATH += E:\Environment\opencv452\include\
E:\Environment\opencv452\include\opencv2
LIBS += E:\Environment\opencv452\x64\mingw\lib\libopencv*
}
有gpu(深度学习环境自己配置过cuda的)需要修改其中的几个操作,开启cuda选项,点击执行cmake
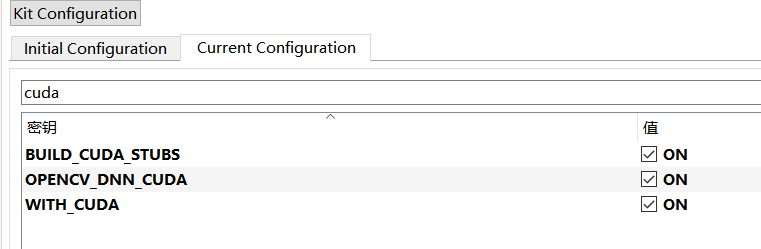
发现cmake报错,查询发现是cuda11.7版本和opencv4.5.2版本不匹配,4.5.2支持cuda11.2,尝试换成opencv4.8.0还是报错不知道怎么解决,放弃了就用cpu吧

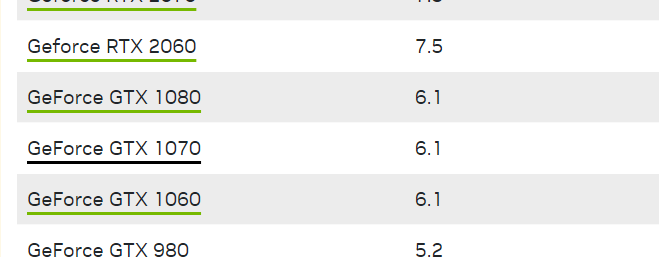
执行完后会出现新的选项,查看显卡算力查看算力,修改CUDA_ARCH_BIN我是6.1
1.1 报错Could NOT find CUDNN (missing: CUDNN_LIBRARY CUDNN_INCLUDE_DIR) (Required is at least version “7.5”)
(做了这么一大堆操作发现都没啥用,qt把构建版本改为MSVC就行,MinGW死活找不到,但是又出现了别的报错)发现cmake报错, Could NOT find CUDNN (missing: CUDNN_LIBRARY CUDNN_INCLUDE_DIR) (Required is at least version “7.5”),
缺少cudnn的环境变量,还发现自己的cuda版本和tookit不匹配,cuda12.2,tookit11.7,索性重装了(在cmake里可以找到,但是在qtcreater里找不到,绝了)

把原来的11.7 卸载,下载12.2链接安装,查看系统变量里是否有,没有手动添加

去下载cudnn官网下载我下载了8.8.1,cuda12.2
解压完成后将三个文件夹复制到你的cuda路径
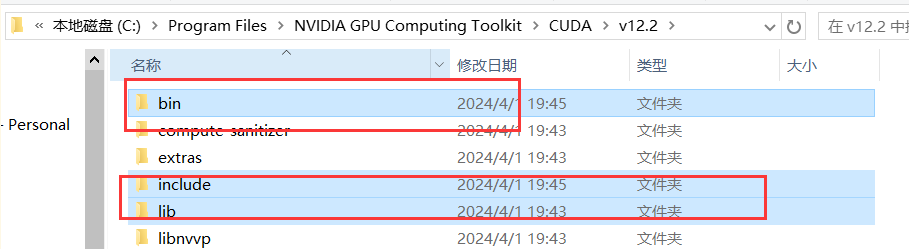
打开系统变量path,添加上这些路径,删除之前版本的路径,重启电脑,重构项目

进入终端运行以下指令,路径自己更改,最后显示pass,则说明安装上了
cd C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.2\extras\demo_suite
deviceQuery.exe
bandwidthTest.exe

1.2 使用camke+vs编译opencv4.8.0,4.6.0
选择路径,点击config
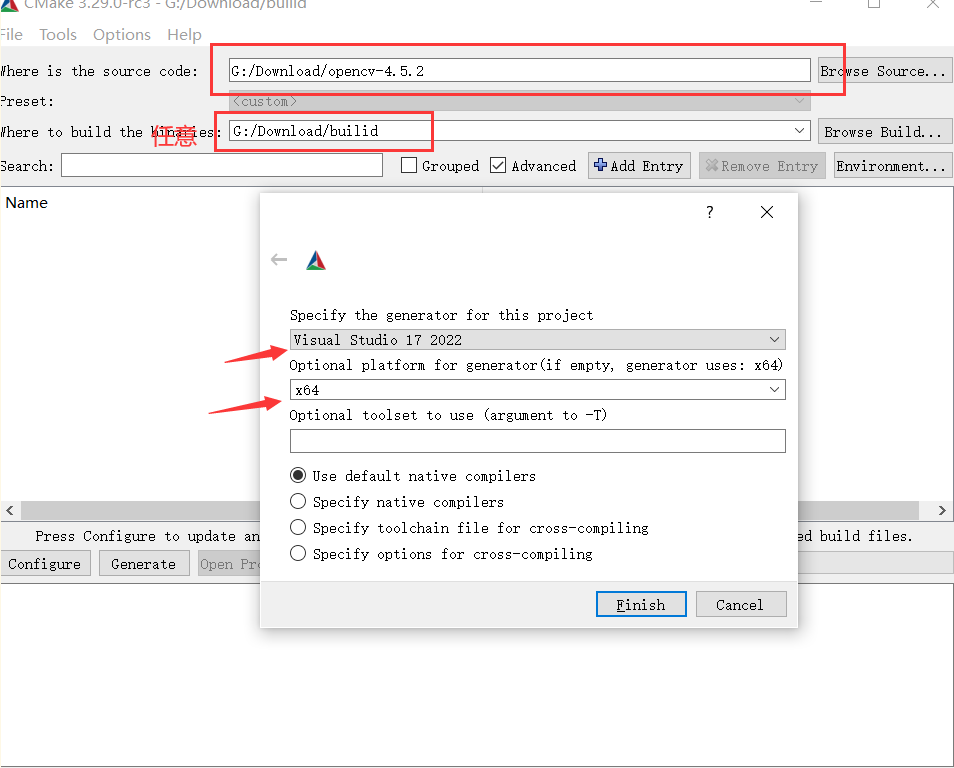
依旧是选择这些点击configigure,


取消勾选这三个test,var,cvv取消java,pyhton的所有勾选
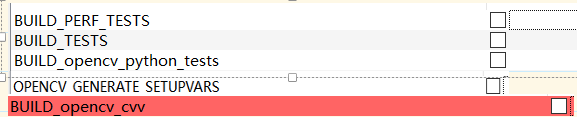
选上这些FAST,OPENGL,在把算力改为自己显卡的算力,再次点击config

选择你的qt路径,再次config

configure完成后在点击generate,点击openProject会打开VS
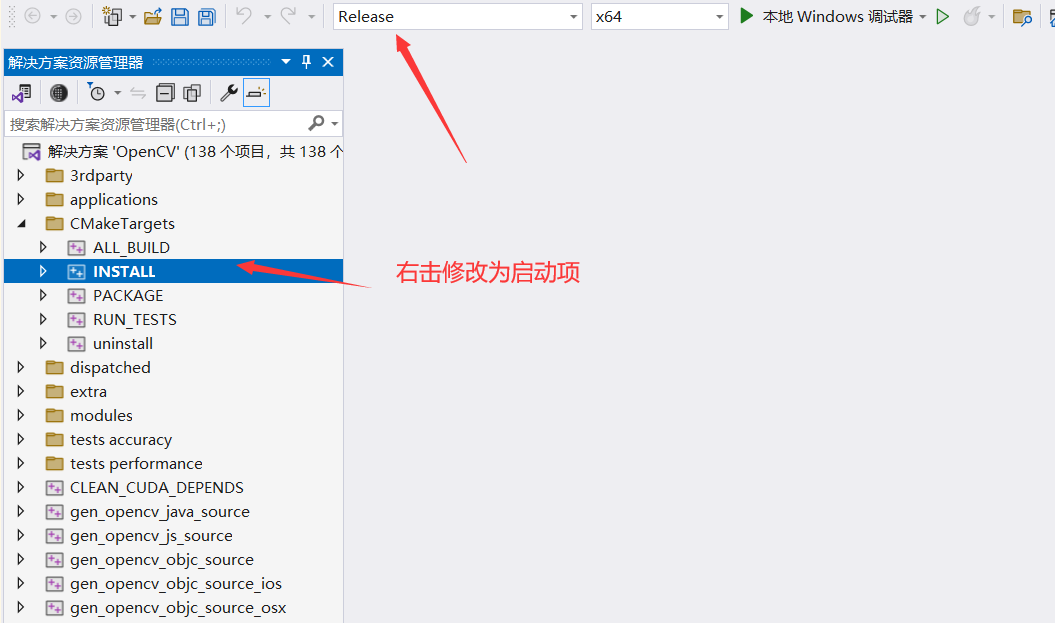
修改为release,将install修改为启动项,右击生成

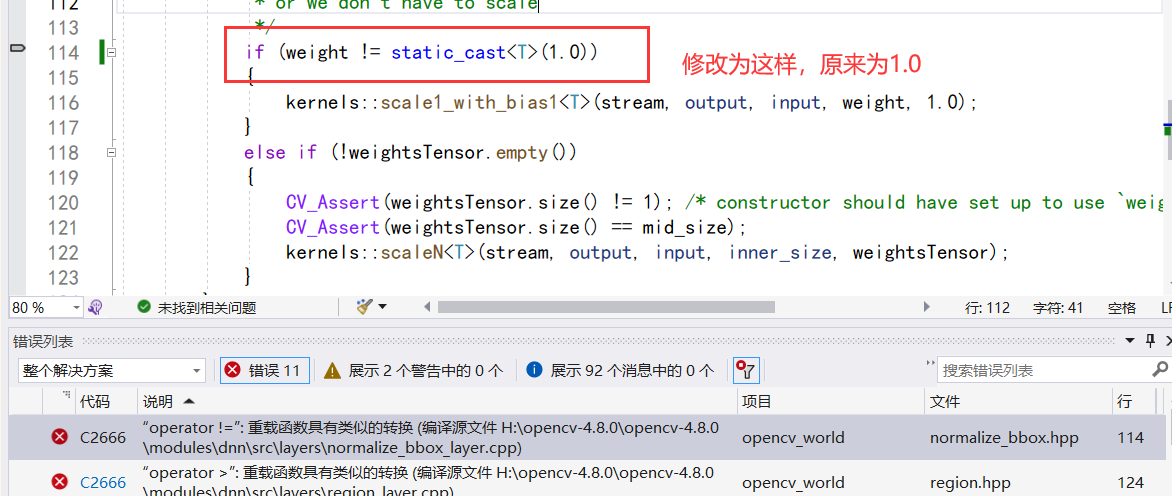
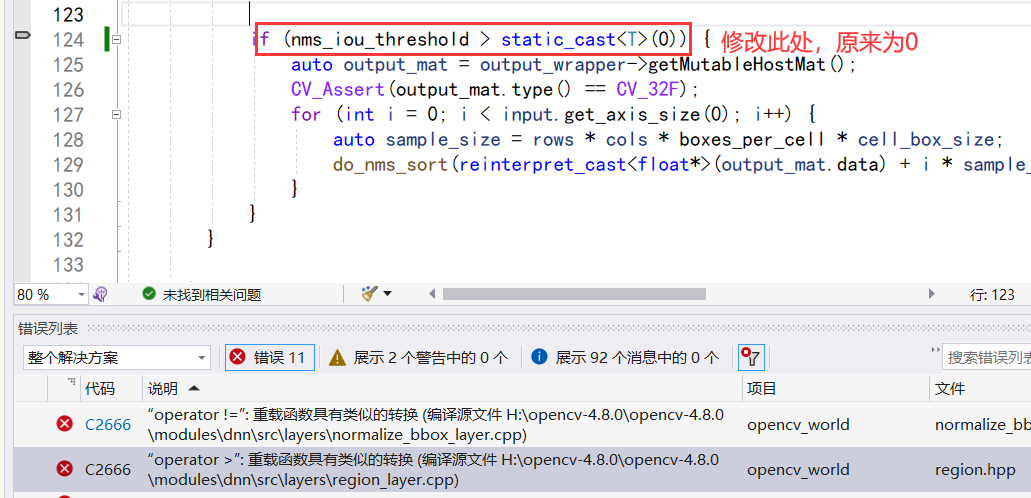
1.3 报错’operator !=":重载函数具有类似的转换(编译源文件 H:\opencv-4.8.0\opencv-4.8.0kmodules\dnn\src\layers\normalize bbox layer.cpp)
双击报错,修改源码,添加上static_cast<T>
历经两个小时编译成功
将有.dll文件的路径添加到系统变量path里

1.4 opencv4.5.5报错texture is not a template
Cuda12.1要求opencv版本大于4.7.0?
1.5 编译成功
历经两个小时编译成功
将有.dll文件的路径添加到系统变量path里

cmd里边运行这个,如果成功显示opencv版本,那就是成功了(打不开也行)
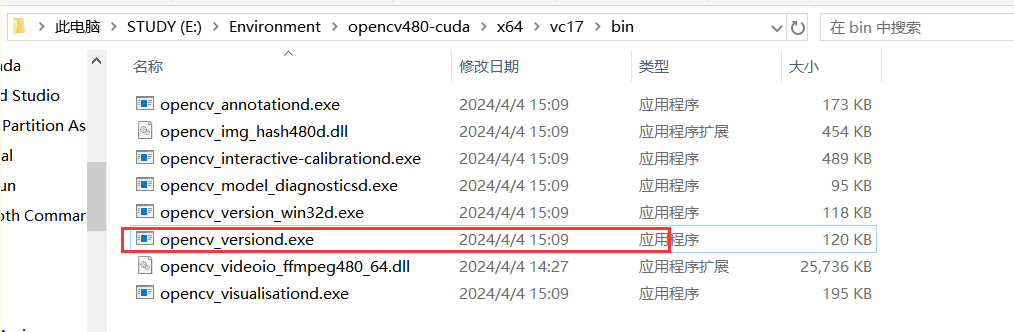
1.6 opencv4.6.0编译成功
GPU运行环境 QT5.15.2 msvc2019 opencv4.6.0-cuda vs2019 cuda11.3

2 搭建界面
按照下图搭建界面
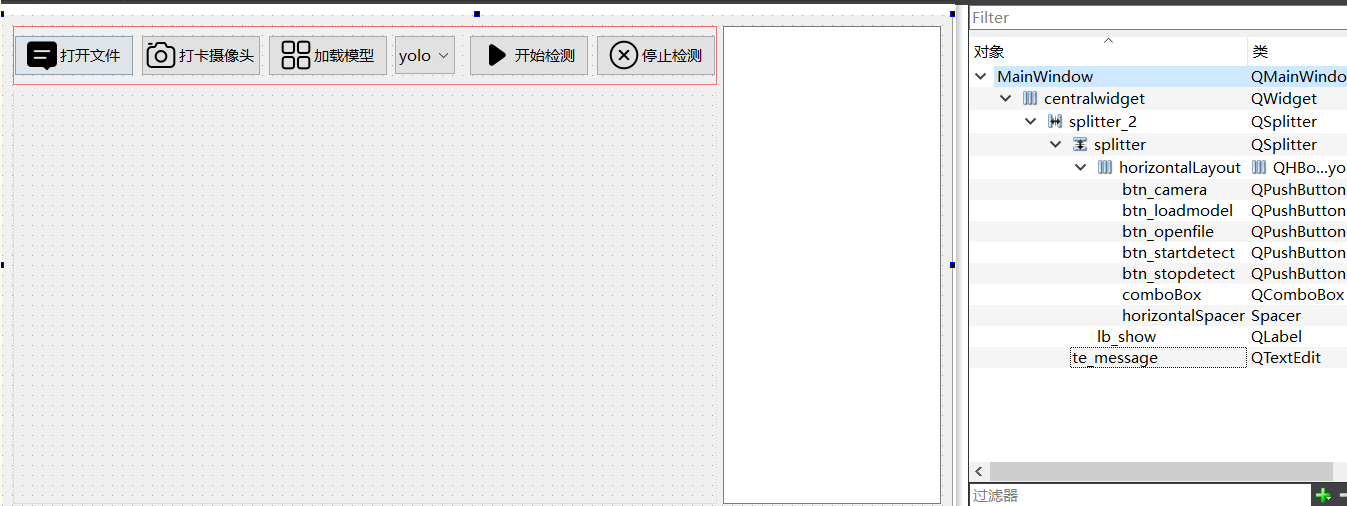
3 按钮初始逻辑编写
3.1 打开文件
点击按钮打开文件对话框,选择文件后通过filename保存文件路径,并且把视频和图片显示到lb_show上
void MainWindow::on_btn_openfile_clicked()
{
QString filename = QFileDialog::getOpenFileName(this,QStringLiteral("打开文件"),".","*.mp4 *.avi *.png *.jpe *.jpeg *.bmp");
if(!QFile::exists(filename))
{
return;
}
ui->te_message->setText(filename);
}
使用QMimeDatabase和QMimeType来确定文件的MIME类型,以判断是图片文件还是视频文件,方便我们使用opencv进行操作
QMimeDatabase db;
QMimeType mime = db.mimeTypeForFile(filename);
qDebug()<<mime.name();
3.1.1 打开显示图片
对于不同通道的图片需要使用opencv进行转换
// 如果文件是图片类型
if(mime.name().startsWith("image/"))
{
// 使用OpenCV读取图片
cv::Mat src = cv::imread(filename.toStdString());
// 检查图片是否正确读取,即图片数据是否非空
if(src.empty())
{
ui->lb_show->setText("图像不存在"); // 如果图片不存在,显示错误消息
return;
}
cv::Mat temp; // 创建一个临时Mat对象用于存放转换后的图片数据
// 根据图片的通道数进行相应的颜色空间转换
if(src.channels() == 4)
{
// 如果图片是4通道的(如带透明度的PNG),则转换为RGB
cv::cvtColor(src, temp, cv::COLOR_BGRA2RGB);
}
else if(src.channels() == 3)
{
// 如果图片是3通道的(如JPG),则转换为RGB
cv::cvtColor(src, temp, cv::COLOR_BGR2RGB);
}
else
{
// 如果图片是2通道的或其他情况,这里的注释应该为处理单通道灰度图,将其转换为RGB
cv::cvtColor(src, temp, cv::COLOR_GRAY2RGB);
}
// 将OpenCV的Mat数据转换为QImage对象
QImage img = QImage(temp.data, temp.cols, temp.rows, temp.step, QImage::Format_RGB888);
// 将QImage对象转换为QPixmap对象,并根据标签的高度调整图片大小
QPixmap mmp = QPixmap::fromImage(img);
mmp = mmp.scaledToHeight(ui->lb_show->height());
// 将调整后的图片显示在标签上
ui->lb_show->setPixmap(mmp);
}
3.1.2 打开视频
使用open打开视频,但是一打开时评程序就崩溃了,发现是指针为分配对象,没有初始化只有cv::VideoCapture *capture;,但是没有capture = new cv::VideoCapture;,这个指针一开始指向任意地址。这样做可以确保指针指向一个有效的内存地址,且该地址上存放的是一个cv::VideoCapture对象。
// 设置文件类型为视频
filetype = "video";
// 使用OpenCV打开视频文件
capture->open(filename.toStdString());
// 如果无法打开视频文件,则在文本编辑区显示错误消息并返回
if(!capture->isOpened())
{
ui->te_message->append("mp4文件打开失败!");
return;
}
// 获取视频的总帧数,宽度,高度,显示信息
long totalFrame = capture->get(cv::CAP_PROP_FRAME_COUNT);
int width = capture->get(cv::CAP_PROP_FRAME_WIDTH);
int height = capture->get(cv::CAP_PROP_FRAME_HEIGHT);
ui->te_message->append(QString("整个视频共 %1 帧, 宽=%2 高=%3 ").arg(totalFrame).arg(width).arg(height));
// 设置要从视频的开始帧读取
long frameToStart = 0;
capture->set(cv::CAP_PROP_POS_FRAMES, frameToStart);
ui->te_message->append(QString("从第 %1 帧开始读").arg(frameToStart));
// 获取视频的帧率
double frameRate = capture->get(cv::CAP_PROP_FPS);
ui->te_message->append(QString("帧率为: %1 ").arg(frameRate));
// 读取视频的第一帧
cv::Mat frame;
capture->read(frame);
// 将帧的颜色空间从BGR转换为RGB
cv::cvtColor(frame, frame, cv::COLOR_BGR2RGB);
// 将OpenCV的Mat对象转换为QImage对象
QImage videoimg = QImage(frame.data, frame.cols, frame.rows, frame.step, QImage::Format_RGB888);
// 将QImage对象转换为QPixmap对象
QPixmap mmp = QPixmap::fromImage(videoimg);
// 将QPixmap对象按照标签的高度进行缩放
mmp = mmp.scaledToHeight(ui->lb_show->height());
// 在标签上显示这个QPixmap对象
ui->lb_show->setPixmap(mmp);
对于播放视频我们需要定时器和槽函数,将更新帧的槽函数和定时器建立连接,定时器开始时,播放视频
void MainWindow::updateFrame()
{
cv::Mat frame;
if(capture->read(frame))
{
//读取帧成功
cv::cvtColor(frame,frame,cv::COLOR_BGR2RGB);
QImage videoimg = QImage(frame.data, frame.cols, frame.rows, frame.step, QImage::Format_RGB888);
QPixmap mmp = QPixmap::fromImage(videoimg);
mmp = mmp.scaledToHeight(ui->lb_show->height());
ui->lb_show->setPixmap(mmp);
}
}
void MainWindow::on_btn_startdetect_clicked()
{
if(filetype == "pic")
{
//对图像进行识别
}
else if(filetype == "video")
{
//对视频进行识别
double frameRate = capture->get(cv::CAP_PROP_FPS);
timer->start(1000/frameRate); // 根据帧率开始播放
}
else
{
//对摄像头进行识别
}
}
3.2 打开摄像头
点击打开摄像头,按钮变为关闭摄像头,同时启动定时器,启动更新帧的槽函数(使用ifelse来判断是视频还是相机)
void MainWindow::on_btn_camera_clicked()
{
filetype = "camera";
if(ui->btn_camera->text() == "打开摄像头")
{
ui->btn_camera->setText("关闭摄像头");
capture->open(0);
timer->start(100);
}
else
{
ui->btn_camera->setText("打开摄像头");
capture->release();
timer->stop();
ui->lb_show->clear();
}
}
使用同一个updateFrame函数来处理更新视频帧和更新摄像头的数据,使用filetype来判断,将摄像头读取的每帧数据进行处理展示
else if(filetype == "camera")
{
cv::Mat src;
if(capture->isOpened())
{
//将摄像头数据放入src
*capture >> src;
if(src.data == nullptr) return; // 如果图像数据为空,则返回
}
//将图像转换为qt能够处理的格式
cv::Mat frame;
cv::cvtColor(src,frame,cv::COLOR_BGR2RGB);
cv::flip(frame,frame,1);
QImage videoimg = QImage(frame.data, frame.cols, frame.rows, frame.step, QImage::Format_RGB888);
QPixmap mmp = QPixmap::fromImage(videoimg);
mmp = mmp.scaledToHeight(ui->lb_show->height()); //设置图像的缩放比例
ui->lb_show->setPixmap(mmp);
}
3.3 加载模型按钮
就弹出一个文件对话框选择模型就行
void MainWindow::on_btn_loadmodel_clicked()
{
// 使用文件系统弹出对话框获得用户选择的文件路径
QString filename = QFileDialog::getOpenFileName(this, QStringLiteral("打开文件"), ".", "*.onnx");
// 检查文件是否存在
if(!QFile::exists(filename))
{
return; // 如果文件不存在,则直接返回
}
// 在文本编辑框中显示选中的文件路径
ui->te_message->setText(filename);
}
4 加载YOLOv5
没有找到好的教程只能抄了,边抄便理解。
4.1 初始化yolov5
confThreshold(类别置信度阈值):用于过滤那些分类置信度低于此阈值的检测结果。
nmsThreshold(非最大抑制阈值):在执行非最大抑制(一种去除重叠检测框的方法)时使用的阈值。
objThreshold(目标置信度阈值):用于过滤那些目标置信度(即,对象存在的置信度)低于此阈值的检测结果。
netname(网络名称):指定使用的网络模型的名称。
struct NetConfig
{
float confThreshold; // 类别置信度阈值
float nmsThreshold; // 非最大抑制(NMS)阈值
float objThreshold; // 目标置信度阈值
std::string netname; // 网络名称
};
新建一些私有变量来初始化模型
float confThreshold; // 类别置信度阈值
float nmsThreshold; // 非最大抑制(NMS)阈值
float objThreshold; // 目标置信度阈值
// 定义锚点尺寸,每个尺寸组对应不同尺度的特征图
const float anchors[3][6] = {
{10.0, 13.0, 16.0, 30.0, 33.0, 23.0},
{30.0, 61.0, 62.0, 45.0, 59.0, 119.0},
{116.0, 90.0, 156.0, 198.0, 373.0, 326.0}
};
// 定义特征图的步长
const float stride[3] = {8.0, 16.0, 32.0};
// 定义可能检测到的类别
std::string classes[80] = {
"person", "bicycle", "car", "motorbike", "aeroplane", "bus",
"train", "truck", "boat", "traffic light", "fire hydrant",
"stop sign", "parking meter", "bench", "bird", "cat", "dog",
"horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe",
"backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
"skis", "snowboard", "sports ball", "kite", "baseball bat",
"baseball glove", "skateboard", "surfboard", "tennis racket",
"bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl",
"banana", "apple", "sandwich", "orange", "broccoli", "carrot",
"hot dog", "pizza", "donut", "cake", "chair", "sofa", "pottedplant",
"bed", "diningtable", "toilet", "tvmonitor", "laptop", "mouse",
"remote", "keyboard", "cell phone", "microwave", "oven", "toaster",
"sink", "refrigerator", "book", "clock", "vase", "scissors",
"teddy bear", "hair drier", "toothbrush"
};
// 输入图像的宽和高
const int inpWidth = 640;
const int inpHeight = 640;
// 用于存储网络输出的向量
std::vector<cv::Mat> outs;
// 检测到的类别ID
std::vector<int> classIds;
// 检测到的类别的置信度
std::vector<float> confidences;
// 检测到的对象的边界框
std::vector<cv::Rect> boxes;
// 用于非最大抑制后保留的检测框的索引
std::vector<int> indices;
// 神经网络
cv::dnn::Net net;
// YOLOv5对象的初始化函数
void YOLOv5::Init(NetConfig config)
{
// 设置类别置信度阈值
this->confThreshold = config.confThreshold;
// 设置非最大抑制阈值
this->nmsThreshold = config.nmsThreshold;
// 设置目标置信度阈值
this->objThreshold = config.objThreshold;
// 预分配内存以优化性能,以下是基于经验的估计值
classIds.reserve(20); // 预留空间用于存储检测到的类别ID
confidences.reserve(20); // 预留空间用于存储检测到的类别的置信度
boxes.reserve(20); // 预留空间用于存储检测到的边界框
outs.reserve(3); // 预留空间用于存储网络的输出
indices.reserve(20); // 预留空间用于存储非最大抑制后保留的检测框的索引
}
4.2 加载onnx模型
新建函数loadmodel,加载onnx模型,如果有gpu就是用gpu没有就使用cpu
// 加载ONNX模型文件
bool YOLOv5::loadModel(QString onnxfile)
{
try
{
// 使用OpenCV从ONNX文件读取网络模型
this->net = cv::dnn::readNetFromONNX(onnxfile.toStdString());
// 检查是否有可用的CUDA设备(即检查是否可以使用GPU进行加速)
int deviceID = cv::cuda::getCudaEnabledDeviceCount();
if(deviceID == 1)
{
// 如果有可用的CUDA设备,将网络的推理后端设置为CUDA以使用GPU
this->net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
this->net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
}
else
{
// 如果没有检测到CUDA设备,则弹出消息框提示用户当前使用CPU进行推理
QMessageBox::information(NULL, "warning", QStringLiteral("正在使用CPU推理!\n"), QMessageBox::Yes, QMessageBox::Yes);
}
return true; // 模型加载成功,返回true
}
catch(std::exception& e)
{
// 如果在加载模型过程中发生异常,弹出消息框提示错误信息,并返回false
QMessageBox::critical(NULL, "Error", QStringLiteral("模型加载出错,请检查重试!\n %1").arg(e.what()), QMessageBox::Yes, QMessageBox::Yes);
return false;
}
}
测试一下加载模型,成功加载cpu模型
if(!yolov5->loadModel(onnxfile))
{
ui->te_message->append("加载模型失败!");
return;
}
else
{
ui->te_message->append("加载模型成功!");
}
4.3 图片模型推理
推理代码直接抄了
// YOLOv5目标检测函数
void YOLOv5::detect(cv::Mat &frame)
{
// 将输入图像转换为神经网络的blob格式,并进行归一化和大小调整
cv::dnn::blobFromImage(frame, blob, 1 / 255.0, cv::Size(this->inpWidth, this->inpHeight), cv::Scalar(0, 0, 0), true);
// 将blob设置为网络的输入
this->net.setInput(blob);
// 运行前向传播,得到网络输出
this->net.forward(outs, this->net.getUnconnectedOutLayersNames());
// 清除之前的检测结果
classIds.clear();
confidences.clear();
boxes.clear();
// 计算从模型输入尺寸到原始图像尺寸的缩放比例
float ratioh = (float)frame.rows / this->inpHeight, ratiow = (float)frame.cols / this->inpWidth;
int n = 0, q = 0, i = 0, j = 0, nout = 8 + 5, c = 0;
for (n = 0; n < 3; n++) ///尺度
{
// 计算特征图的网格数量
int num_grid_x = (int)(this->inpWidth / this->stride[n]);
int num_grid_y = (int)(this->inpHeight / this->stride[n]);
int area = num_grid_x * num_grid_y; // 网格总数
// 对网络输出进行sigmoid处理
this->sigmoid(&outs[n], 3 * nout * area);
for (q = 0; q < 3; q++) ///anchor数
{
// 获取当前尺度下的锚框宽度和高度
const float anchor_w = this->anchors[n][q * 2];
const float anchor_h = this->anchors[n][q * 2 + 1];
float* pdata = (float*)outs[n].data + q * nout * area; // 当前锚框的网络输出
for (i = 0; i < num_grid_y; i++) // 遍历网格y方向
{
for (j = 0; j < num_grid_x; j++) // 遍历网格x方向
{
// 获取当前格子的置信度
float box_score = pdata[4 * area + i * num_grid_x + j];
if (box_score > this->objThreshold) // 如果置信度大于阈值
{
float max_class_socre = 0, class_socre = 0;
int max_class_id = 0;
for (c = 0; c < 80; c++) get max socre
{
// 获取类别置信度
class_socre = pdata[(c + 5) * area + i * num_grid_x + j];
if (class_socre > max_class_socre)
{
max_class_socre = class_socre;
max_class_id = c; // 记录最大类别置信度及其索引
}
}
if (max_class_socre > this->confThreshold) // 如果类别置信度大于阈值
{
// 计算检测框的中心坐标、宽度和高度
float cx = (pdata[i * num_grid_x + j] * 2.f - 0.5f + j) * this->stride[n]; ///cx
float cy = (pdata[area + i * num_grid_x + j] * 2.f - 0.5f + i) * this->stride[n]; ///cy
float w = powf(pdata[2 * area + i * num_grid_x + j] * 2.f, 2.f) * anchor_w; ///w
float h = powf(pdata[3 * area + i * num_grid_x + j] * 2.f, 2.f) * anchor_h; ///h
// 将检测框的坐标还原到原图上
int left = (cx - 0.5*w)*ratiow;
int top = (cy - 0.5*h)*ratioh; ///坐标还原到原图上
// 将检测结果保存到相应的容器中
classIds.push_back(max_class_id);
confidences.push_back(max_class_socre);
boxes.push_back(Rect(left, top, (int)(w*ratiow), (int)(h*ratioh)));
}
}
}
}
}
}
indices.clear();
cv::dnn::NMSBoxes(boxes, confidences, this->confThreshold, this->nmsThreshold, indices);
for (size_t i = 0; i < indices.size(); ++i)
{
int idx = indices[i];
Rect box = boxes[idx];
// 绘制预测框及其类别和置信度
this->drawPred(classIds[idx], confidences[idx], box.x, box.y,
box.x + box.width, box.y + box.height, frame);
}
}
void YOLOv5::drawPred(int classId, float conf, int left, int top, int right, int bottom, cv::Mat &frame)
{
// 绘制检测框
rectangle(frame, Point(left, top), Point(right, bottom), Scalar(0, 0, 255), 3);
// 构建标签,包含类别名称和置信度
string label = format("%.2f", conf);
label = this->classes[classId] + ":" + label;
int baseLine;
// 获取标签尺寸
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
top = max(top, labelSize.height);
// 绘制标签
putText(frame, label, Point(left, top), FONT_HERSHEY_SIMPLEX, 0.75, Scalar(0, 255, 0), 1);
}
void YOLOv5::sigmoid(cv::Mat *out, int length)
{
float* pdata = (float*)(out->data);
int i = 0;
// 对网络输出进行sigmoid处理
for (i = 0; i < length; i++)
{
pdata[i] = 1.0 / (1 + expf(-pdata[i]));
}
}
在读取图片后装换位RBG后进行检测yolov5->detect(temp),人太大了好像就不检测了。
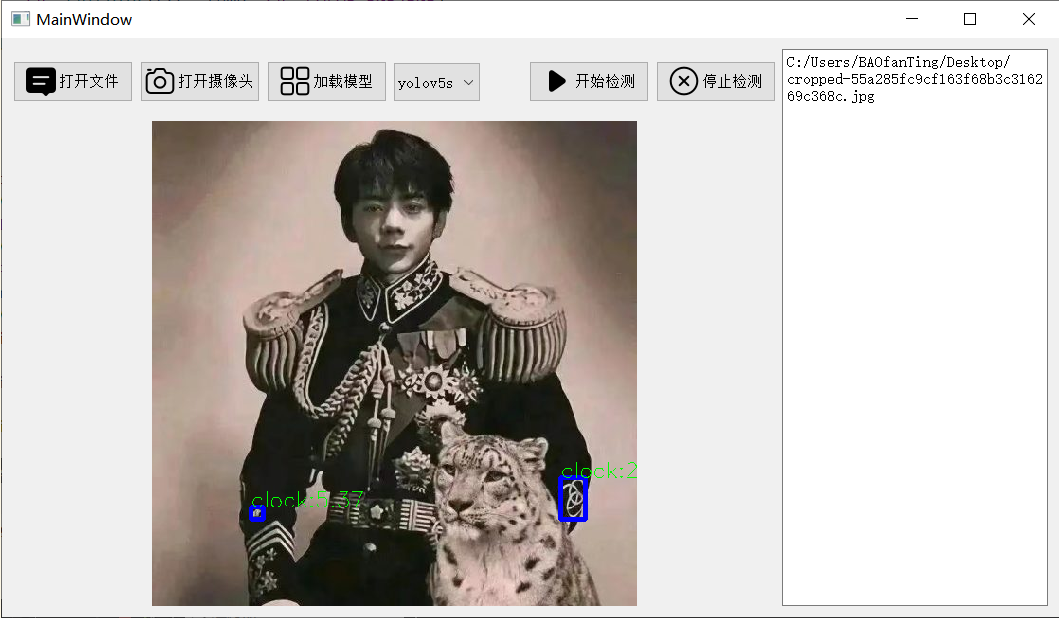
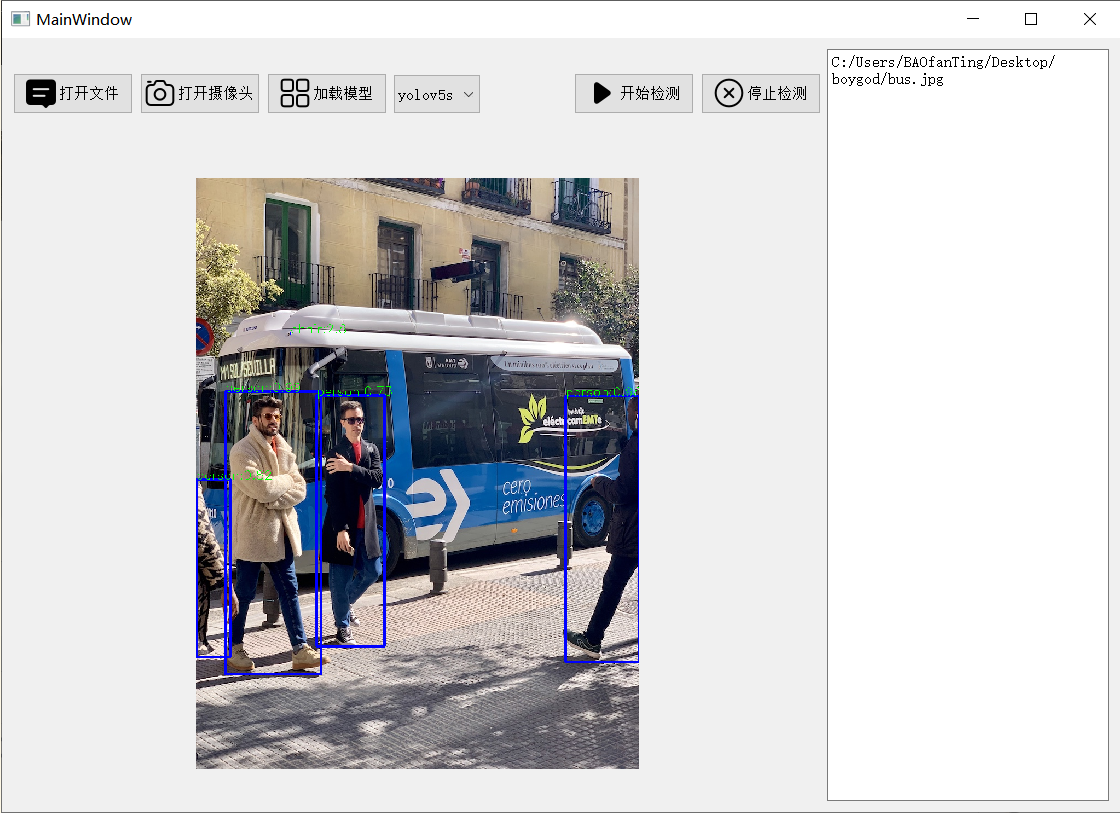
4.4 视频推理和摄像头推理
视频推理需要用到启动推理的按钮,同样也是在读取的帧转换为RBG后启动推理,并且使用canDetect来判断是否开启检测,一直判断好像确实比较消耗资源
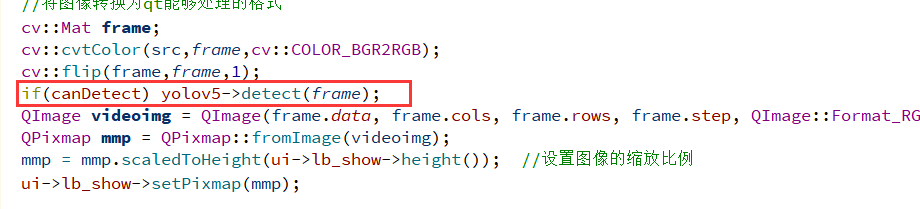
在点击开始检测时把canDetect设置为true,同时把其他按钮屏蔽。
void MainWindow::on_btn_startdetect_clicked()
{
//开始检测时封锁其他按钮
ui->btn_startdetect->setEnabled(false);
ui->btn_stopdetect->setEnabled(true);
ui->btn_openfile->setEnabled(false);
ui->btn_loadmodel->setEnabled(false);
ui->btn_camera->setEnabled(false);
ui->comboBox->setEnabled(false);
ui->te_message->append(QStringLiteral("=======================\n"
" 开始检测\n"
"=======================\n"));
if(filetype == "pic")
{
//对图像进行识别
}
else if(filetype == "video")
{
//对视频进行识别
canDetect = true;
double frameRate = capture->get(cv::CAP_PROP_FPS);
timer->start(1000/frameRate); // 根据帧率开始播放
}
else
{
canDetect = true;
//对摄像头进行识别
}
}
效果很卡,还需要优化,1秒多才能处理一帧
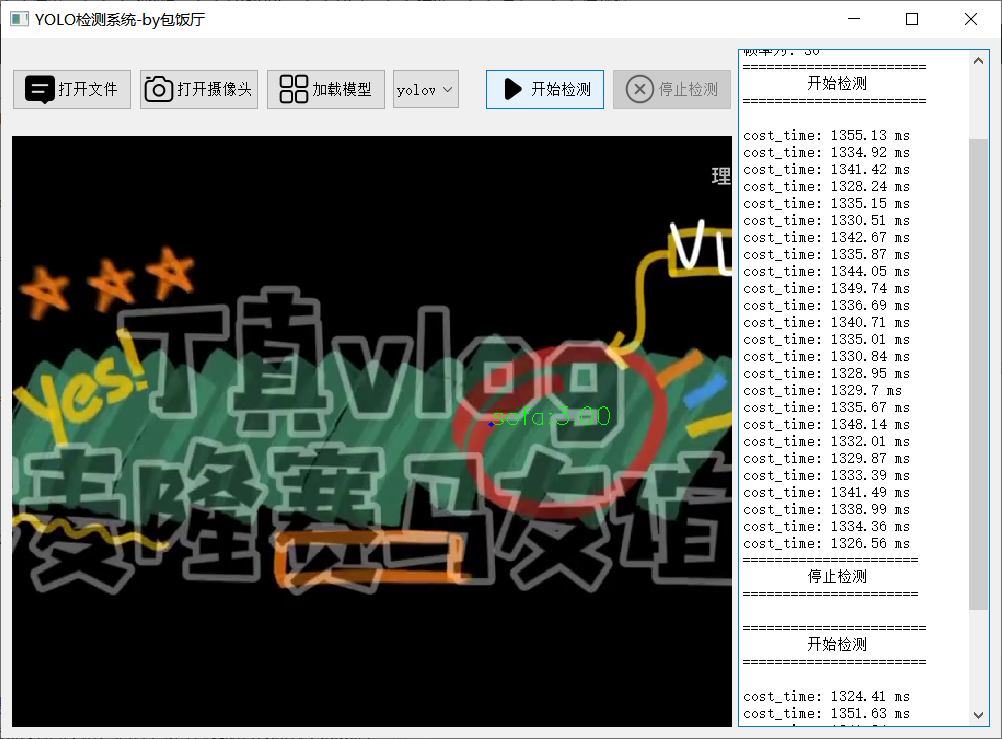
4.5 停止检测按钮
停止按钮很简单,把其他按钮功能打开,停止计时器
void MainWindow::on_btn_stopdetect_clicked()
{
//开始检测时封锁其他按钮
ui->btn_startdetect->setEnabled(true);
ui->btn_stopdetect->setEnabled(false);
ui->btn_openfile->setEnabled(true);
ui->btn_loadmodel->setEnabled(true);
ui->btn_camera->setEnabled(true);
ui->comboBox->setEnabled(true);
timer->stop();
ui->te_message->append(QString( "======================\n"
" 停止检测\n"
"======================\n"));
canDetect = false;
}
4.6 必须先加载模型防止崩溃
如果不加载模型直接开始检测,程序会崩溃,所以需要在设置一个变量is_loadedmodel,加载模型时,在其他按钮的开始都添加判断是否加载模型的代码
if(!is_loadedmodel)
{
QMessageBox::information(nullptr,"错误","请先加载模型!");
return;
}
4.7 信息框显示最新数据
要确保te_message控件始终显示最新的数据,你可以使用QTextEdit的moveCursor方法,使得每次向te_message添加新内容后,视图自动滚动到底部。在输出消息后,调用这个方法:
ui->te_message->moveCursor(QTextCursor::End);
4.8 使用线程优化
首先让yolov5成为Qobject的对象才能使用线程,修改头文件和构造函数
class YOLOv5 : public QObject {
Q_OBJECT // 使得类支持Qt信号和槽机制
public:
explicit YOLOv5(QObject *parent = nullptr);
YOLOv5::YOLOv5(QObject *parent)
: QObject{parent}
{}
现在捋一下逻辑,我们在构造函数里创建线程,把yolov5的对象放入线程,但是在线程中不能直接调用对象的函数,需要用信号来触发,所以在需要检测的时候我们把信号和检测的图片同时发送出去,在mainwindow的头文件里定义,同时将yolov5->detect都替换成这个信号发送
signals:
void sendFrame(cv::Mat &frame);
//发送检测信号
emit sendFrame(temp);
把yolov5的detect函数定义为槽函数
public slots:
void detect(cv::Mat& frame);
在到mainwindow的构造函数里添加上线程和信号连接,这样在发送帧后就会自动调用检测函数
//使用线程优化
QThread *thread = new QThread();
//把yolov5放入线程
yolov5->moveToThread(thread);
thread->start();
connect(this,&MainWindow::sendFrame,yolov5,&YOLOv5::detect);
运行后报错了,数据类型没有被识别,在main函数里添加上这一句qRegisterMetaType<cv::Mat>("cv::Mat&");

再次运行,发现没有有检测框,但是两个函数都调用了,且id也能检测出来,那就是两个函数都运行了,但是绘制的图像不是原图,应该是没有传地址过去,同一个数据处理应该在同一个线程上,可能还需要将绘制函数也作为信号和槽函数。

添加信号,槽函数,在mainwindow的构造函数里在添加一个连接
signals:
void senddraw(int classId, float conf, int left, int top, int right, int bottom, cv::Mat& frame);
public slots:
void detect(cv::Mat& frame);
void drawPred(int classId, float conf, int left, int top, int right, int bottom, cv::Mat& frame);
//发送绘制信号
connect(yolov5,&YOLOv5::senddraw,yolov5,&YOLOv5::drawPred);
发现还是不行,信号只管发送,不会等待返回,所以得当检测绘制执行完毕,发送信号,绘制到界面上。先设置绘制框完成的信号

把绘制图片的代码封装一下,绑定一下
connect(yolov5,&YOLOv5::drawEnd,this,&MainWindow::drawRectPic);
void MainWindow::drawRectPic(cv::Mat &frame)
{
auto end = std::chrono::steady_clock::now();
std::chrono::duration<double, std::milli> elapsed = end - start;
ui->te_message->append(QString("cost_time: %1 ms").arg(elapsed.count()));
ui->te_message->moveCursor(QTextCursor::End); //确保显示最新信息
//显示图片
QImage img = QImage(frame.data, frame.cols, frame.rows, frame.step, QImage::Format_RGB888);
QPixmap mmp = QPixmap::fromImage(img);
mmp = mmp.scaledToHeight(ui->lb_show->height()); //设置图像的缩放比例
ui->lb_show->setPixmap(mmp);
}
又发现了新的问题,只会显示识别的帧,这是还需要一个信号,indices里边代码检测框的数量,0的时候就是没有检测到,此时发出信号,绘制没有检测到框的图片。发现优化和没优化一个速度,逻辑还是有点问题,没有异步起来,只有上一个动作执行完才能进行下一个。
if(indices.size() == 0)
{
emit detectEnd(frame);
}
尝试让画框的程序在mainwindow里实现,YOLO只做检测,更改一些槽函数和信号。
线程优化没啥用,不用看了
5 使用msvc编译qt程序,编译opencv—cuda加速
opencvcuda使用VS变编译的所以得在msvc的环境下才能加载,构建release版本
切换为msvc时一堆报错都是常量中有换行符,但是我自己看看也没错,是编译的问题,需要在.pro文件中添加上一下代码
msvc {
QMAKE_CFLAGS += /utf-8
QMAKE_CXXFLAGS += /utf-8
}

我是编译了opencv_world所以只需要引入这个lib就行
#ifdef QT_NO_DEBUG
#pragma comment(lib,"E:/Environment/opencv480-cuda/x64/vc17/lib/opencv_world480.lib")
#endif
再次加载模型使用上GPU了终于,但是进行检测就闪退了也没有报错
5.1 使用opencv4.6.0
排查发现在这一句net.forward(outs, this->net.getUnconnectedOutLayersNames())运行前向传播是出错。也不知道咋解决。所以换个opencv版本。
编译完成后将bin文件夹添加进系统变量path里,重启电脑,修改路径,修改为msvc,release版 运行
终于成功了。可以看到检测速度大幅度提升,从1300变到了10
//.pro文件
INCLUDEPATH += E:\Environment\opencv460-cuda\include\
E:\Environment\opencv460-cuda\include\opencv2
// 其他头文件
#ifdef QT_NO_DEBUG
#pragma comment(lib,"E:/Environment/opencv460-cuda/x64/vc16/lib/opencv_world460.lib")
#pragma comment(lib,"E:/Environment/opencv460-cuda/x64/vc16/lib/opencv_img_hash460.lib")
#endif

 | 点击访问博客查看更多内容 |
|---|















 3020
3020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









