








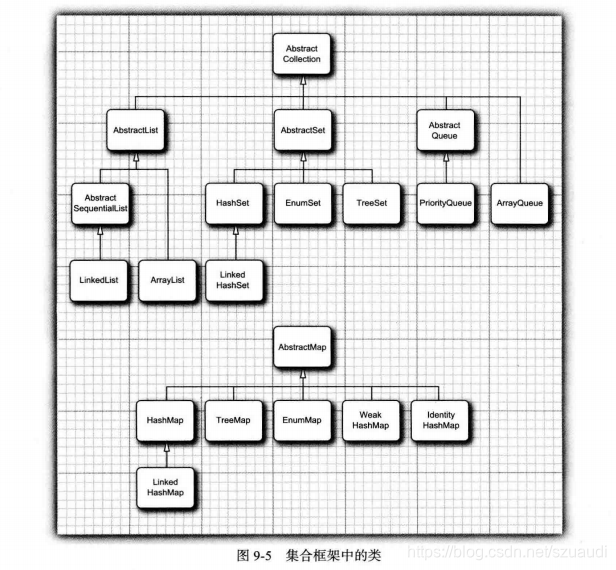
在上表中,以Map结尾的类实现了Map接口,除此外,其他类都实现了Collection接口。
链表
在Java语言中,所有链表都是双向连接的(doubly linked)。

public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
public LinkedList() {
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null); // 尾插,尾节点next为null
last = newNode;
if (l == null) // 没有头节点,头节点就是数据节点,prev为null
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
// ...
}
链表是一个有序集合(ordered collection)。LinkedList.add方法将对象添加到链表尾部。
// java.util.LinkedList#add(E)
public boolean add(E e) {
linkLast(e);
return true;
}
依赖于位置的add方法将由迭代器负责(将元素添加到链表中间)。
// java.util.LinkedList#add(int, E)
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
// java.util.LinkedList#checkPositionIndex
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
// java.util.LinkedList#isPositionIndex
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
// java.util.LinkedList#node
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) { // index小于表长一半,从头查
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else { // index大于表长一半,从尾查
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
只有对自然有序的集合使用迭代器添加元素才有实际意义。像集(set)类型,其中的元素完全无序。因此,在Iterator接口中就没有add方法。
// java.util.Iterator
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
相反,集合类库提供了子接口ListIterator中包含add方法:
public interface ListIterator<E> extends Iterator<E> {
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int nextIndex();
void remove();
void set(E e);
void add(E e);
}
与Collection.add不同,这个方法不返回boolean类型的值,它假定操作总会改变链表。
ListIterator接口有两个用来反向遍历链表的方法:
E previous()
boolean hasPrevious()
LinkedList类的listIterator方法返回一个实现ListIterator接口的迭代器对象。
ListIterator<String> iter = staff.listIterator();
// java.util.AbstractList#listIterator()
public ListIterator<E> listIterator() {
return listIterator(0);
}
// java.util.LinkedList#listIterator
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
// java.util.LinkedList.ListItr#ListItr
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index);
nextIndex = index;
}
在调用next之后,remove方法与BACKSPACE键一样删除了迭代器左侧的元素。
// java.util.LinkedList.ListItr#next
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
但是,如果调用preview就会将右侧的元素删除掉,
// java.util.LinkedList.ListItr#previous
public E previous() {
checkForComodification();
if (!hasPrevious())
throw new NoSuchElementException();
lastReturned = next = (next == null) ? last : next.prev;
nextIndex--;
return lastReturned.item;
}
且不能连续调用两次remove。
// java.util.LinkedList.ListItr#remove
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next; // 移除的是上一次遍历的节点
unlink(lastReturned); // 释放节点指针,并保持链表连接
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null; // 不能连续调用两次remove
expectedModCount++;
}
// java.util.LinkedList#unlink
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
set方法用一个新元素取代调用next或preview方法返回的上一个元素。
// java.util.LinkedList.ListItr#set
public void set(E e) {
if (lastReturned == null)
throw new IllegalStateException();
checkForComodification();
lastReturned.item = e;
}
链表迭代器发现它的集合被另一个迭代器修改了,或是被该集合自身的方法修改了,就会抛出一个ConcurrentModificationException异常。
// java.util.LinkedList.ListItr#checkForComodification
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
例如:
List<String> list = ...;
ListIterator<String> iter1 = list.listIterator();
ListIterator<String> iter2 = list.listIterator();
iter1.next();
iter1.remove();
iter2.next(); // throws ConcurrentModificationException
为了避免发生并发修改的异常,请遵循规则:可以根据需要给容器附加许多的迭代器,但这些迭代器只能读取列表。另外,再单独附加一个既能读又能写的迭代器。
有一种简单的方法可以检测到并发修改的问题。集合可以跟踪改写操作的次数。每个迭代器都维护一个独立的计数值。在每个迭代器方法的开始处检查自己改写操作的计数值是否与集合的改写操作计数值一致。如果不一致,抛出一个ConcurrentModificationException异常。
对并发修改列表的检测,链表只负责跟踪对列表的结构性修改,如:添加元素、删除元素。set方法进行的修改元素不被视为结构性修改。
// java.util.LinkedList#set
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
// java.util.LinkedList#set
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
LinkedList类提供了get方法,但效率不高,
// java.util.LinkedList#get
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
不过,如果索引大于size()/2就从列表尾端开始搜索元素。
// java.util.LinkedList#node
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
列表迭代器接口还提供了获取当前位置的方法。nextIndex方法返回下一次调用next方法时返回元素的整数索引;previousIndex方法返回下一次调用previous方法时返回元素的整数索引。这个索引只比nextIndex返回的索引值小1。
private class ListItr implements ListIterator<E> {
private Node<E> lastReturned;
private Node<E> next;
private int nextIndex;
private int expectedModCount = modCount;
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index);
nextIndex = index;
}
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
public boolean hasPrevious() {
return nextIndex > 0;
}
public E previous() {
checkForComodification();
if (!hasPrevious())
throw new NoSuchElementException();
lastReturned = next = (next == null) ? last : next.prev;
nextIndex--;
return lastReturned.item;
}
public int nextIndex() {
return nextIndex;
}
public int previousIndex() {
return nextIndex - 1;
}
}
如果指定listIterator方法的参数n,将返回一个指向索引为n的元素前面位置的迭代器。
// java.util.LinkedList#listIterator
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}



数组列表
集合类库提供了一种大家熟悉的 ArrayList 类, 这个类也实现了 List 接口。ArrayList 封
装了一个动态再分配的对象数组。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
private static final int DEFAULT_CAPACITY = 10; // 默认容量
private static final Object[] EMPTY_ELEMENTDATA = {};
// 共享空数组,避免申请新内存指针
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData; // non-private to simplify nested class access
private int size;
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index); // navicat方法数组拷贝
elementData[index] = element;
size++;
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // 扩容原来的1.5倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
}
ArrayList取代Vector原因:Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象。但是,如果由一个线程访问Vector,代码要在不同操作上耗费大量的时间。
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
protected Object[] elementData;
protected int elementCount;
protected int capacityIncrement;
private static final long serialVersionUID = -2767605614048989439L;
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
public Vector() {
this(10);
}
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity); // 默认扩容2倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
而ArrayList方法不是同步的。建议在不需要同步时使用ArrayList,而不要使用Vector。
散列集
散列表可以快速查找所需要的的对象。散列表为每个对象计算一个整数,称为散列码(hash code)。散列码由对象的实例域产生一个整数。具有不同数据域的对象将产生不同的散列码。
// java.lang.String#hashCode
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
如果自定义类,就要负责实现这个类的hashCode方法。自己实现的hashCode方法应该与equals方法兼容,即如果a.equals(b)为true,a与b必须具有相同的散列码。
在Java中,散列表用链表数组实现。每个列表被称为桶(bucket)。要想查找表中对象的位置,就要先计算它的散列码,然后与桶的总数取余(HashMap使用&取余,参见添加链接描述),所得结果就是保存这个元素的桶的索引。或许会很幸运,这个桶中没有其他元素,此时将元素直接插入到桶中就可以了。如果遇到桶被占满的情况,这种现象被称为散列冲突(hash collision)。这时,需要用新对象与桶中的所有对象进行比较,查看这个对象是否已经存在。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true); // 1.计算散列码
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 2.取余.3.1.没有其他元素
tab[i] = newNode(hash, key, value, null); // 没冲突,直接赋值,i = (n - 1) & hash
else { // 3.2.散列冲突,与桶中所有元素比较
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) // 3.2.1.key是第一个节点
e = p;
else if (p instanceof TreeNode) // 3.2.2.拉链是树结构
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) { // 3.2.3.循环找到插入位置
if ((e = p.next) == null) { // 找到空。创建新节点
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash); // 链长超过TREEIFY_THRESHOLD,链变为树
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) // 找到key
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount; // 新节点,旧值是null,节点数增加,resize
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
如果散列码是合理且随机分布的,桶的数目也足够大,需要比较的次数就会很少。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
transient Node<K,V>[] table;
transient Set<Map.Entry<K,V>> entrySet;
transient int size;
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 没冲突,直接赋值,i = (n - 1) & hash
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) // key是第一个节点
e = p;
else if (p instanceof TreeNode) // 拉链是树结构
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) { // 循环找到插入位置
if ((e = p.next) == null) { // 找到空。创建新节点
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) // 找到key
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount; // 新节点,旧值是null,节点数增加,resize
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
final Node<K,V>[] resize() { // 重设置表长
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) { // 1.如果已达到最大表长,退出
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY) // 2.如果小于最大表长,且(大于)等于初始化表长,表扩容2倍
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
在Java SE 8 中,桶满时会从链表变为平衡二叉树。
如果想更多地控制散列表的运行性能,就要指定一个初始的桶数。桶数是指用于收集具有相同散列值的桶的数目。
/**
* The default initial capacity - MUST be a power of two.
* 默认初始容量-必须是2的指数
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
* 最大容量
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
* 树化桶大小阈值。达到阈值后,执行树化桶操作。
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
* 去树化阈值
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
* 树化时最小表长。达到后,桶由链表变为树,否则resize。
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
如果散列表太满,就需要再散列。如果要再散列,就需要创建一个桶数更多的表,并将所有元素插入到这个表中,然后丢弃原来的表。装填因子(load factor)决定何时对散列表进行再散列。例如,如果装填因子为0.75(默认值),而表中超过75%的位置已经填入元素,这个表就会用双倍的桶数自动进行再散列。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
对于大多数应用程序来说, 装填因子为0.75 是比较合理的。
/**
* The load factor used when none specified in constructor.
* 负载因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
Java集合类库提供了一个HashSet类,它实现了基于散列表的集。
可以用 add 方法添加元素。
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
。contains方法已经被重新定义,用来快速地查看是否某个元素已经出现在集中。它只
在某个桶中査找元素,而不必查看集合中的所有元素。
// java.util.HashSet#contains
public boolean contains(Object o) {
return map.containsKey(o);
}
// containsKey
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
散列集迭代器依次访问所有的桶。由于散列将元素分散在表的各个位置上,所以访问它们的顺序几乎是随机的。
public Iterator<E> iterator() {
return map.keySet().iterator();
}


树集
树集是一个有序集合(sorted collection)。可以以任意顺序将元素插入到集合中。在对集合进行遍历时,每个值将自动地按照排序后的顺序呈现。排序是用树结构完成的(当前实现使用的是红黑树)。每次将一个元素添加到树中时,都被放置在正确的排序位置上。因此,迭代器总是以排好序的顺序访问每个元素。
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
private void fixAfterInsertion(Entry<K,V> x) { ... }
要使用树集,必须能够比较元素。这些元素必须实现Comparable接口,或者构造集时必须提供一个Comparator。
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
/**
* Constructs a set backed by the specified navigable map.
*/
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
}
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
}
应该使用数据还是散列集取决于索要收集的数据。对于某些数据来说,对其排序要比散列函数更加困难。散列函数只是将对象适当地打乱存放, 而比较却要精确地判别每个对象。

队列与双端队列
在Java SE 6中引入了Deque接口,并由ArrayDeque和LinkedList类实现。两个类都提供了双端队列,且在必要时可以增加队列的长度。
public class ArrayDeque<E> extends AbstractCollection<E>
implements Deque<E>, Cloneable, Serializable
{
transient Object[] elements; // non-private to simplify nested class access
transient int head;
transient int tail;
private static final int MIN_INITIAL_CAPACITY = 8;
public ArrayDeque() {
elements = new Object[16];
}
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
public ArrayDeque(Collection<? extends E> c) {
allocateElements(c.size());
addAll(c);
}
private void allocateElements(int numElements) {
elements = new Object[calculateSize(numElements)];
}
private static int calculateSize(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// Find the best power of two to hold elements.
// Tests "<=" because arrays aren't kept full.
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
}
return initialCapacity;
}
}

public class ArrayDeque<E> extends AbstractCollection<E>
implements Deque<E>, Cloneable, Serializable
{
public boolean add(E e) {
addLast(e);
return true;
}
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // number of elements to the right of p
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
System.arraycopy(elements, p, a, 0, r);
System.arraycopy(elements, 0, a, r, p);
elements = a;
head = 0;
tail = n;
}
public boolean offer(E e) {
return offerLast(e);
}
public boolean offerLast(E e) {
addLast(e);
return true;
}
public E remove() {
return removeFirst();
}
public E removeFirst() {
E x = pollFirst();
if (x == null)
throw new NoSuchElementException();
return x;
}
public E pollFirst() {
int h = head;
@SuppressWarnings("unchecked")
E result = (E) elements[h];
// Element is null if deque empty
if (result == null)
return null;
elements[h] = null; // Must null out slot
head = (h + 1) & (elements.length - 1);
return result;
}
public E poll() {
return pollFirst();
}
public E element() {
return getFirst();
}
public E getFirst() {
@SuppressWarnings("unchecked")
E result = (E) elements[head];
if (result == null)
throw new NoSuchElementException();
return result;
}
public E peek() {
return peekFirst();
}
@SuppressWarnings("unchecked")
public E peekFirst() {
// elements[head] is null if deque empty
return (E) elements[head];
}
}

public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
public E removeLast() {
E x = pollLast();
if (x == null)
throw new NoSuchElementException();
return x;
}
public E pollLast() {
int t = (tail - 1) & (elements.length - 1);
@SuppressWarnings("unchecked")
E result = (E) elements[t];
if (result == null)
return null;
elements[t] = null;
tail = t;
return result;
}

优先级队列
优先级队列(priority queue)中的元素可以按照任意的顺序插入,却总是按照排序的顺序进行检索。
public boolean add(E e) {
return offer(e);
}
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
@SuppressWarnings("unchecked")
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
@SuppressWarnings("unchecked")
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
无论何时调用remove方法,总会获得当前优先级队列中最小的元素。
public boolean remove(Object o) {
int i = indexOf(o);
if (i == -1)
return false;
else {
removeAt(i);
return true;
}
}
@SuppressWarnings("unchecked")
private E removeAt(int i) {
// assert i >= 0 && i < size;
modCount++;
int s = --size;
if (s == i) // removed last element
queue[i] = null;
else {
E moved = (E) queue[s];
queue[s] = null;
siftDown(i, moved);
if (queue[i] == moved) {
siftUp(i, moved);
if (queue[i] != moved)
return moved;
}
}
return null;
}
优先级队列使用了堆。
与TreeSet一样,一个优先级队列可以保存实现了Comparable接口的类对象,也可以保存在构造器中提供的Comparator对象。

public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
private static final int DEFAULT_INITIAL_CAPACITY = 11;
transient Object[] queue; // non-private to simplify nested class access
private int size = 0;
private final Comparator<? super E> comparator;
transient int modCount = 0; // non-private to simplify nested class access
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
public PriorityQueue(int initialCapacity) {
this(initialCapacity, null);
}
public PriorityQueue(Comparator<? super E> comparator) {
this(DEFAULT_INITIAL_CAPACITY, comparator);
}
}















 1817
1817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









