






最近在利用python跟着指导书进行机器学习的实践,在实践中使用到了Pipeline类方法和GridSearchCV类方法,并且使用过程中发现了一些问题,所以本文主要想记录并分享一下个人对于这两种类方法的思考,如果有误,请见谅,欢迎大家一起前来探讨。当然,如果这篇文章还能入得了各位“看官”的法眼,麻烦点赞、关注、收藏,支持一下!
本文主要想重点记录一下Pipeline类方法和GridSearchCV类方法在使用过程中的一些不易察觉的注意事项,花不多说,进入正文
一、Pipeline类方法使用过程中的注意事项
Pipeline类方法有一个关键参数:steps
1、steps的格式:由多个二维元组组成的多维列表,且列表中的最后一个元组代表估计器
2、steps中的元组格式为:(命名,转换器/估计器),命名我们可以随便设置,但是一定要是字符串
3、steps中的元组不能仅含一个元素,即不可以写成:(命名,)
4、可以通过“passthrough”或者“None”来删除转换器/估计器,即:(命名,'passtrhough')、(命名,'None')
二、GridSearchCV类方法使用过程中的注意事项
GridSearchCV类方法有三个关键参数:estimator、param_grid、cv
1、estimator:带有score方法的估计器,如果估计器没有score方法,必须通过GridSearchCV类方法的参数“scoring”来指定评分策略
2、param_grid:参数字典,该字典是键为字符串形式,值为数组形式
3、cv:交叉验证策略,当cv的值为一个整数或者None时,如果估计器是分类器,则采用的是分层交叉验证,即StratifiedKFold,对于其它情况适用的是k折交叉验证,即KFold
三、结合Pipeline和GridSearchCV进行模型选择的注意事项
1、传递给GridSearchCV的Pipeline实例化对象,必须含有完整的steps列表
正确形式:
pipe=Pipeline([('scaler',StandardScaler()),('reg',MLPRegressor())])
grid=GridSearchCV(pipe,param_grid=params,cv=3)错误形式:
pipe=Pipeline([('scaler',),('reg',)])
grid=GridSearchCV(pipe,param_grid=params,cv=3)2、结合Pipeline和GridSearchCV进行模型选择时,Pipeline实例化对象的转换器和估计器,在GridSearchCV中不会被调用,举例说明:
#定义参数字典
params=[{'reg':[MLPRegressor(random_state=38,max_iter=1600)],'scaler':[StandardScaler(),None]},
{'reg':[RandomForestRegressor(random_state=38)],'scaler':[None]}]
pipe=Pipeline([('scaler',MinMaxScaler()),('reg',SVC)])
#对管道模型进行网格搜索
grid=GridSearchCV(pipe,param_grid=params,cv=3,verbose=20)运行上述代码,结果为:
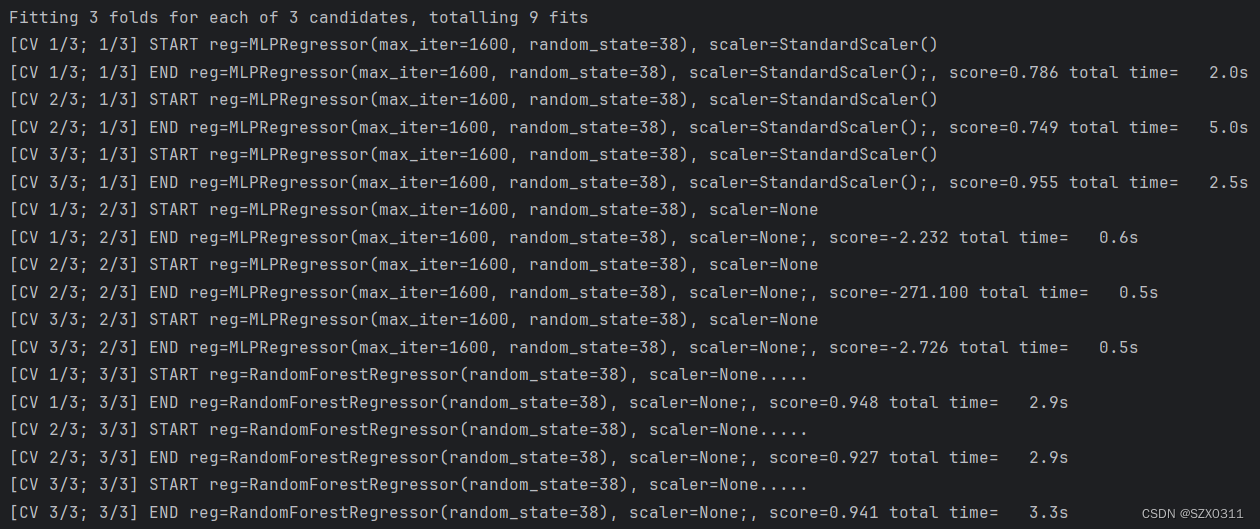
从结果中不难看出,参数字典中的参数组合有三种,GridSearchCV对三种不同的参数组合根据cv值分别进行了交叉验证;同时,Pipeline实例化对象pipe中的转换器MinMaxScaler()以及估计器SVC()并未被执行
















 511
511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









