









HPL
性能分析
HPL(HighPerformanceLinpack)
测 试 可 以
表征
3
种拓扑在双精度浮点运算中的表现
。Bal
anceMode、CommonMode
和
CascadeMode3
种
拓扑的
HPL
性能测试结果如表
3
所示
。

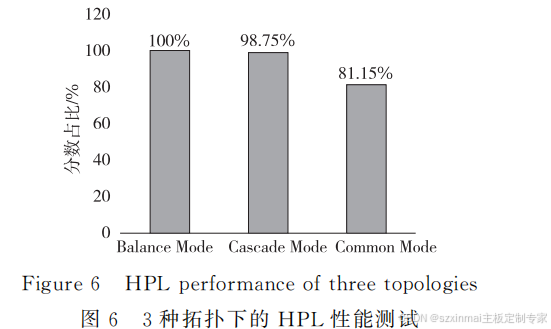
为清晰表征
3
种拓扑在
HPL
性能测试中的
表现差异
,
以
BalanceMode
的测试分数为基准
,
得
到
Common Mode
和
Cascade Mode2
种 拓 扑
HPL
性能测试分数对
BalanceMode
分数的占比
,
如图
6
所示
。
HPL
测试 需 要 使 用 处 理 器 与 主 内 存
,
由 于
Dualroot
的拓扑上行带宽和内存使用率提升
,
性
能将会优于
Singleroot
的拓扑
,
故
Balance Mode
和
CommonMode
在
HPL
测试中的分数会高于
CascadeMode
的
。
另外
,Balance Mode
结构将
8
个
GPU
平均挂载在
2
颗
CPU
下
,
可以利用
2
颗
CPU
及内存的资源来完成浮点运算
;
在
Common
C M P o U de
间 中 的
,
虽
U
然
PI
所 连 有 接
G
速
P
度
U
够 都 快 挂
,
载
CP
于
U C
间
PU
的
0
单 下 条
,
但
UP
因
I
连接速度高达
10.4GT/s,
同时运行
8
个
GPU
的
浮点运算时
,
可以通过
UPI
来与
CPU1
通信
,
且共
享内存
。
故整体而言
,BalanceMode
的
HPL
性能
会略高于
CommonMode
的
。
3.2.3
深度学习性能分析
深度学习
DL(DeepLearning)
通过多个处理
层构成的计算模型进行图像
、
视频和音频等的处理
和识别
[6]
,
常用模型有自动编码机
、
受限玻尔兹曼
机
、
深度神经网络
、
卷积神经网络和循环神经网络
等
,
其中卷积神经网络
[7]
在图像处理方面应用较为
广泛
,
如图
7
所示
。
Figure7 Imageprocessingusingconvolutionalneuralnetwork
图
7
卷积神经网络处理图像
在
2017
年 的
GPU
技 术 大 会
(GTC)
上
,
NVIDIA
发布了基于
volta
的
V100GPU。V100
GPU
是第
1
个包含
“
张量核心
”
的
NVIDIA GPU,
这是
4×4
矩阵乘法操作设计的核心
,
是深度学习
模型的主要部分
[8]
。
深度学 习 训 练 模 型 主 要 使 用
2
种 分 布 策
略
———
数据并行型和模型并行型
[9]
,
本文实验采用
数据并行型策略
。
对于数据并行
,
每个
GPU
都有
一个深度学习模型的完整副本
。
每个
GPU
接收
数据 的 不 同 部 分 进 行 训 练
,
然 后 将 其 参 数 通 过
RingAll-Reduce
的方式更新到所有
GPU,
以便与
所有
GPU
共享其训练输出
。
如图
8
所示
,
以
Bal
anceMode
为例
,
在运行数据并行的深度学习训练
模型时
,
当多台机器运行时
,GPU
的通信流通过
IB(InfiniBand)
卡实现机器之间的信息传递
;
当单
台机 器 运 行 时
,
基 于
NCCL(NVIDIA Collective
CommunicationsLibrary)
通信库
,8
个
GPU
卡的
信息传递构成环形通信流
。
与
GPU
之间的通信
带宽相比
,
减小的
CPU
和
GPU
之间的通信带宽
会影响
GPU
获取数据集所需要的时间
,
即完成一
个
Batchsize
所需的时间
。
Figure8 Dataparallelcommunication
modeforBalancemode
图
8 Balance
模式数据并行的通信模式
深度学习训练模型种类繁多
,
不同模型有不同
的优势
,
可以应用于各类实际应用场景
。
如图
9
所
示
,ResNet
计算模型借鉴了
HighwayNetwork
思
想
,
利用残差网络构建
,
其优化的目标为输出和输

在
2017
年 的
GPU
技 术 大 会
(GTC)
上
,
NVIDIA
发布了基于
volta
的
V100GPU。V100
GPU
是第
1
个包含
“
张量核心
”
的
NVIDIA GPU,
这是
4×4
矩阵乘法操作设计的核心
,
是深度学习
模型的主要部分
[8]
。
深度学 习 训 练 模 型 主 要 使 用
2
种 分 布 策
略
———
数据并行型和模型并行型
[9]
,
本文实验采用
数据并行型策略
。
对于数据并行
,
每个
GPU
都有
一个深度学习模型的完整副本
。
每个
GPU
接收
数据 的 不 同 部 分 进 行 训 练
,
然 后 将 其 参 数 通 过
RingAll-Reduce
的方式更新到所有
GPU,
以便与
所有
GPU
共享其训练输出
。
如图
8
所示
,
以
Bal
anceMode
为例
,
在运行数据并行的深度学习训练
模型时
,
当多台机器运行时
,GPU
的通信流通过
IB(InfiniBand)
卡实现机器之间的信息传递
;
当单
台机 器 运 行 时
,
基 于
NCCL(NVIDIA Collective
CommunicationsLibrary)
通信库
,8
个
GPU
卡的
信息传递构成环形通信流
。
与
GPU
之间的通信
带宽相比
,
减小的
CPU
和
GPU
之间的通信带宽
会影响
GPU
获取数据集所需要的时间
,
即完成一
个
Batchsize
所需的时间
。
=================PCIe5.0 Retimer 卡==============
*消除确定性抖动与随机抖动
*Tx/Rx 按通道性能可调
* 2*MICROx8接口
*支持热插拔
* 低功耗,低延时
*符合PCIe5.0基本规范.
*Tx/Rx 按通道性能可调
* 2*MICROx8接口
*支持热插拔
* 低功耗,低延时
*符合PCIe5.0基本规范.

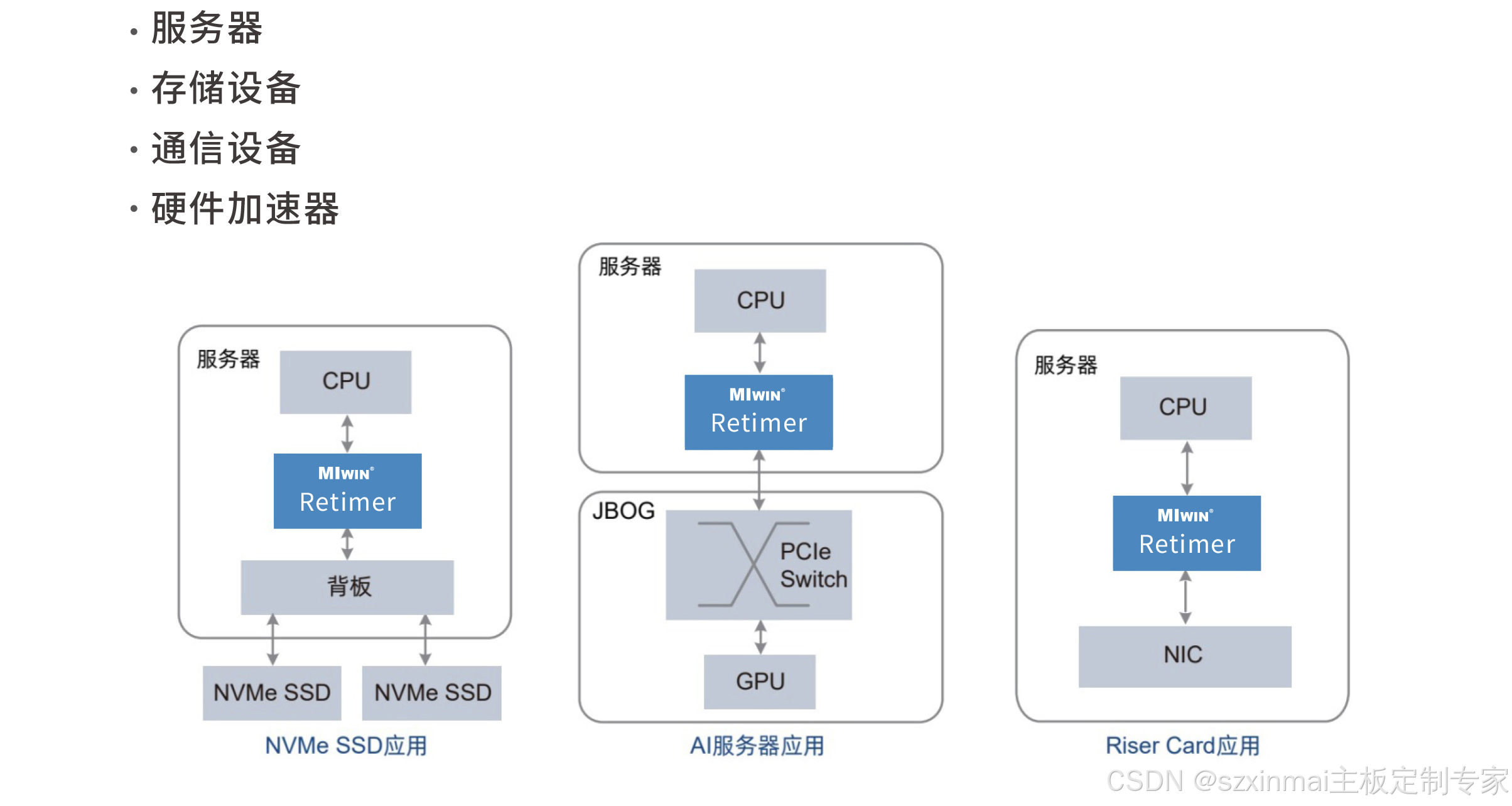
功能特性
| · 高性能 32GT/s SerDeS ; |
| ·2*MICROx8接口; |
| · Tx/Rx 按通道性能可调; |
| · 支持通道极性翻转; |
| ·支持热插拔; |
| ·低功耗,低延时; |
| ·符合PCIe5.0基本规范; |
☑支持OEM/ODM定制服务



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









