










 早停止是一种防止过拟合的策略,当验证集上的损失不再下降或开始上升时,提前结束模型训练。在PyTorch中,可以通过实现EarlyStopping类来监控验证损失,并在满足条件时保存最优模型。这种方法有助于在模型性能达到峰值时及时保存,避免过拟合导致的性能下降。
早停止是一种防止过拟合的策略,当验证集上的损失不再下降或开始上升时,提前结束模型训练。在PyTorch中,可以通过实现EarlyStopping类来监控验证损失,并在满足条件时保存最优模型。这种方法有助于在模型性能达到峰值时及时保存,避免过拟合导致的性能下降。
1.什么是早停止?为什么使用早停止?
早停止(Early Stopping)是 当达到某种或某些条件时,认为模型已经收敛,结束模型训练,保存现有模型的一种手段。
机器学习或深度学习中,有很大一批算法是依靠梯度下降,求来优化模型的。是通过更新参数,让Loss往小的方向走,来优化模型的。可参考BP神经网络推导过程详解
关于模型何时收敛(模型训练好了,性能达到要求了或不能再优化了),此时我们可以采取一些判断标准:
1.验证集上的Loss在模型多次迭代后,没有下降
2.验证集上的Loss开始上升
3.验证集上的准确率在模型多次迭代后,没有上升
3.验证集上的准确率开始下降
……
这时,一般可以认为,模型没必要再训练了,可以及时结束训练了。这就被称为早停止,也是避免模型过拟合的一种方法(不等模型拟合,就结束训练了)。
2.如何使用早停止?
early_stopping.py
import numpy as np
import torch
import os
class EarlyStopping:
"""Early stops the training if validation loss doesn't improve after a given patience."""
def __init__(self, save_path, patience=7, verbose=False, delta=0):
"""
Args:
save_path : 模型保存文件夹
patience (int): How long to wait after last time validation loss improved.
Default: 7
verbose (bool): If True, prints a message for each validation loss improvement.
Default: False
delta (float): Minimum change in the monitored quantity to qualify as an improvement.
Default: 0
"""
self.save_path = save_path
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
def __call__(self, val_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score < self.best_score + self.delta:
self.counter += 1
print(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 0
def save_checkpoint(self, val_loss, model):
'''Saves model when validation loss decrease.'''
if self.verbose:
print(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')
path = os.path.join(self.save_path, 'best_network.pth')
torch.save(model.state_dict(), path) # 这里会存储迄今最优模型的参数
self.val_loss_min = val_loss
把该文件拷贝到自己项目中,
在需要使用早停止的文件中,导入:
from early_stopping import EarlyStopping
使用示例(大致代码):
train_losses = []
train_acces = []
# 用数组保存每一轮迭代中,在测试数据上测试的损失值和精确度,也是为了通过画图展示出来。
eval_losses = []
eval_acces = []
save_path = ".\\" #当前目录下
early_stopping = EarlyStopping(save_path)
for e in range(20000):
# 4.1==========================训练模式==========================
train_loss = 0
train_acc = 0
model.train() # 将模型改为训练模式
# 每次迭代都是处理一个小批量的数据,batch_size是64
for im, label in train_data:
im = Variable(im)
targets = Variable(label)
# 计算前向传播,并且得到损失函数的值
outputs = model(im)
loss = criterion(outputs, targets)
#add by tyb
#model.save_metrics(metrics)
# 反向传播,记得要把上一次的梯度清0,反向传播,并且step更新相应的参数。
optimizer.zero_grad()
loss.backward()
optimizer.step()
#scheduler.step()
# 记录误差
train_loss += loss.item()
# 计算分类的准确率
out_t = outputs.argmax(dim=1) #取出预测的最大值
num_correct = (out_t == targets).sum().item()
acc = num_correct / im.shape[0]
train_acc += acc
train_losses.append(train_loss / len(train_data))
train_acces.append(train_acc / len(train_data))
# 4.2==========================每次进行完一个训练迭代,就去测试一把看看此时的效果==========================
# 在测试集上检验效果
eval_loss = 0
eval_acc = 0
model.eval() # 将模型改为预测模式
# 每次迭代都是处理一个小批量的数据,batch_size是128
for im, label in test_data:
#print("test_data len:",len(test_data))
im = Variable(im) # torch中训练需要将其封装即Variable,此处封装像素即784
label = Variable(label) # 此处为标签
out = model(im) # 经网络输出的结果
loss = criterion(out, label) # 得到误差
# 记录误差
eval_loss += loss.item()
# 记录准确率
out_t = out.argmax(dim=1) # 取出预测的最大值的索引
num_correct = (out_t == label).sum().item() # 判断是否预测正确
acc = num_correct / im.shape[0] # 计算准确率
eval_acc += acc
eval_losses.append(eval_loss / len(test_data))
eval_acces.append(eval_acc / len(test_data))
#scheduler.step()
print('epoch: {}, Train Loss: {:.6f}, Train Acc: {:.6f}, Eval Loss: {:.6f}, Eval Acc: {:.6f}'
.format(e, train_loss / len(train_data), train_acc / len(train_data),
eval_loss / len(test_data), eval_acc / len(test_data)))
# 早停止
early_stopping(eval_loss, model)
#达到早停止条件时,early_stop会被置为True
if early_stopping.early_stop:
print("Early stopping")
break #跳出迭代,结束训练
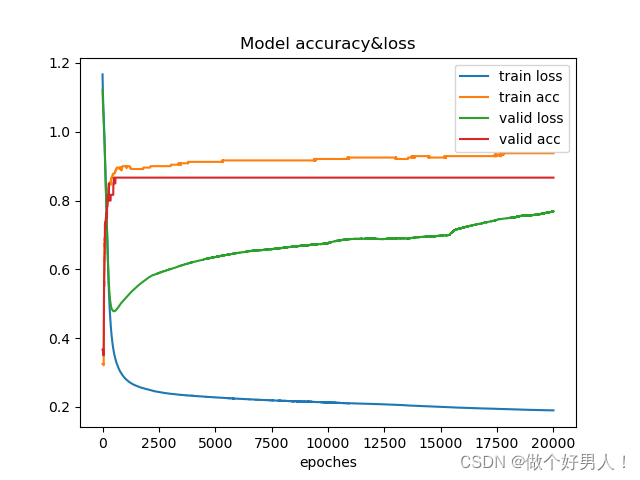
未用早停止:训练集和验证集上的accuracy和loss曲线
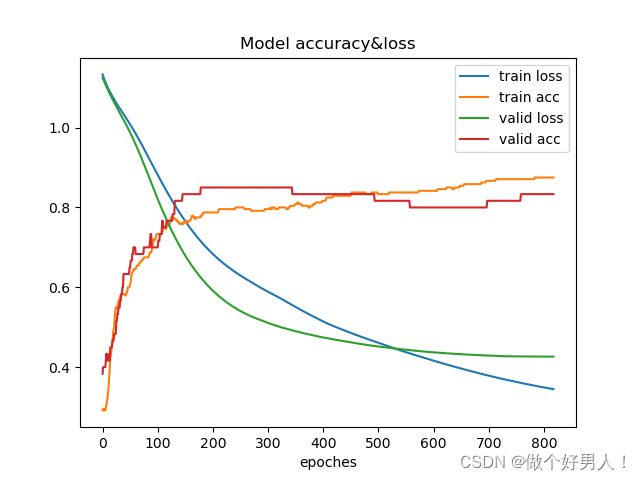
使用早停止:训练集和验证集上的accuracy和loss曲线


















 1575
1575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











