







官方文档
决策树的一些优点:易于理解、可以可视化、白盒模型–可解释性强、既可分类又可回归、几乎不需要数据预处理(删除缺失值,中心化等)、复杂度为节点的对数。
决策树的缺点 : 容易过拟合(剪枝、设置最大深度等)、不稳定(集成树)、在最优性的几个方面都是NP-complete的、有些概念很难学习(异或、奇偶校验等)、
如果数据集种某些类占主导地位,决策树会有偏好,所以创建树前最好平衡数据集。
sklearn.tree.DecisionTreeClassifier
这是分类树,回归树是另一个类DecisionTreeRegressor 。
官方
class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort='deprecated', ccp_alpha=0.0)
注意: 决策树在某些数据集上的复杂度可能很大,最好设置参数max_depth,min_samples_leaf等。
一些参数:
max_depth : int, default=None
树的最大深度。如果取值为None, 则将所有节点展开,直到所有的叶子都是纯净的或者直到所有叶子都包含少于min_samples_split个样本。
min_samples_split: int or float, default=2
拆分内部节点所需的最少样本数:
· 如果取值 int , 则将min_samples_split视为最小值。
· 如果为float,则min_samples_split是一个分数,而ceil(min_samples_split * n_samples)是每个拆分的最小样本数。
max_features: 可以使用"best"或者"random"。前者在特征的所有划分点中找出最优的划分点。后者是随机的在部分划分点中找局部最优的划分点。默认的"best"适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐"random"
类别权重class_weight: 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,或者用“balanced”,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。当然,如果你的样本类别分布没有明显的偏倚,则可以不管这个参数,选择默认的"None"。
调参注意点:
- 容易过拟合,样本数比特征数多一些建立的模型会比较健壮。
- 如果特征数非常多,考虑先降维 or 特征选择
- 多使用可视化,可以先画少几层。
- 如果类别不平衡,要使用class_weight来限制模型过于偏向样本多的类别。
- 决策树的数组使用的是numpy的float32类型,如果训练数据不是这样的格式,算法会先做copy再运行。
- 如果输入的样本矩阵是稀疏的,推荐在拟合前调用csc_matrix稀疏化,在预测前调用csr_matrix稀疏化。
简单例子:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
# 准备鸢尾花数据
iris_data = load_iris()
X, y = iris_data.data, iris_data.target # 150x4
ctree = DecisionTreeClassifier() # 创建决策树对象
ctree.fit(X, y) # 拟合
scores = cross_val_score(ctree, X, y, cv=10)
print(scores)
可视化:
# 可视化
dot_data = tree.export_graphviz(ctree, out_file=None,
feature_names=iris_data.feature_names,
class_names=iris_data.target_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph.view("iris") # 创建pdf文件,并且直接查看,render()方法是创建文件
r = export_text(ctree, feature_names=iris_data['feature_names']) # 不需要借助外部库,以文本格式导出树
# r是字符串类型
print(r)
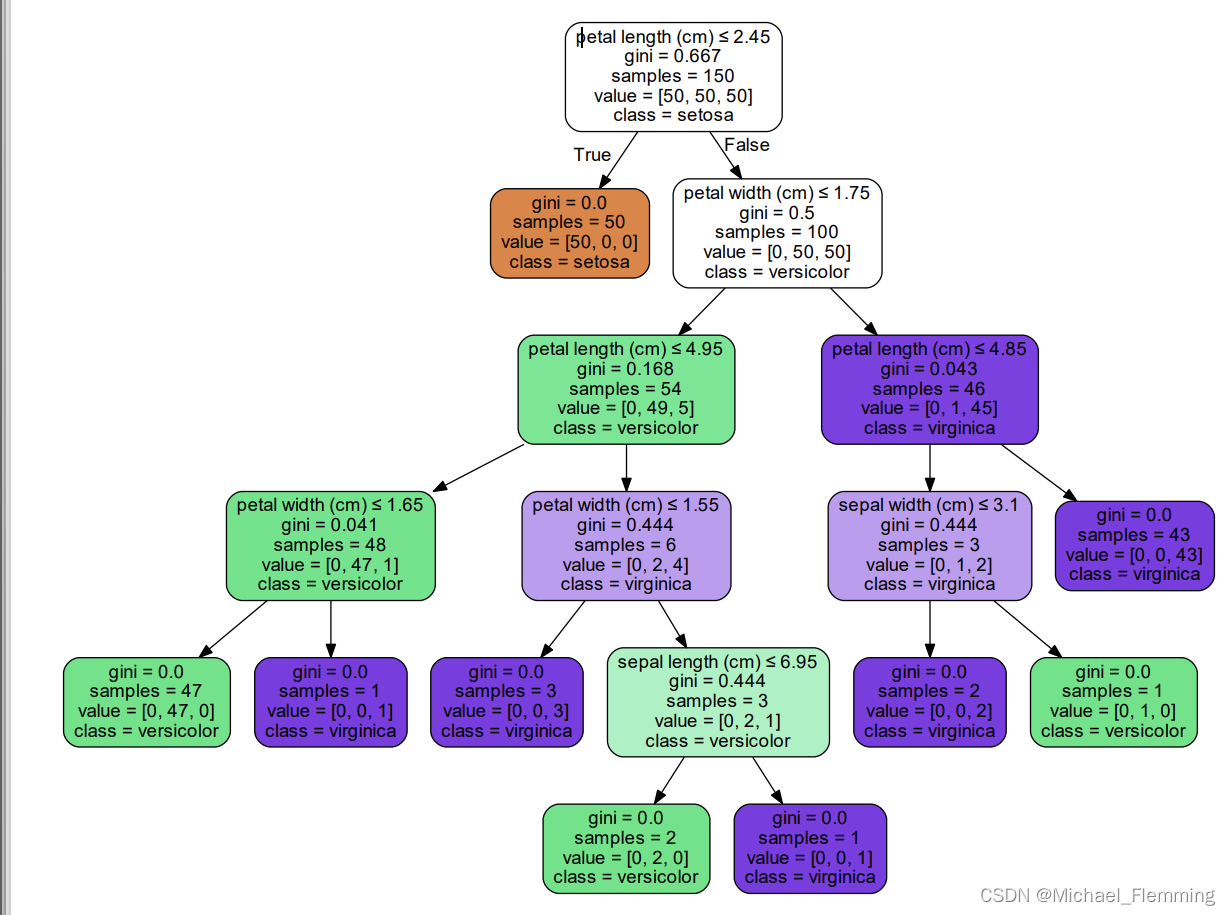
|--- petal width (cm) <= 0.80
| |--- class: 0
|--- petal width (cm) > 0.80
| |--- petal width (cm) <= 1.75
| | |--- petal length (cm) <= 4.95
| | | |--- petal width (cm) <= 1.65
| | | | |--- class: 1
| | | |--- petal width (cm) > 1.65
| | | | |--- class: 2
| | |--- petal length (cm) > 4.95
| | | |--- petal width (cm) <= 1.55
| | | | |--- class: 2
| | | |--- petal width (cm) > 1.55
| | | | |--- sepal length (cm) <= 6.95
| | | | | |--- class: 1
| | | | |--- sepal length (cm) > 6.95
| | | | | |--- class: 2
| |--- petal width (cm) > 1.75
| | |--- petal length (cm) <= 4.85
| | | |--- sepal length (cm) <= 5.95
| | | | |--- class: 1
| | | |--- sepal length (cm) > 5.95
| | | | |--- class: 2
| | |--- petal length (cm) > 4.85
| | | |--- class: 2
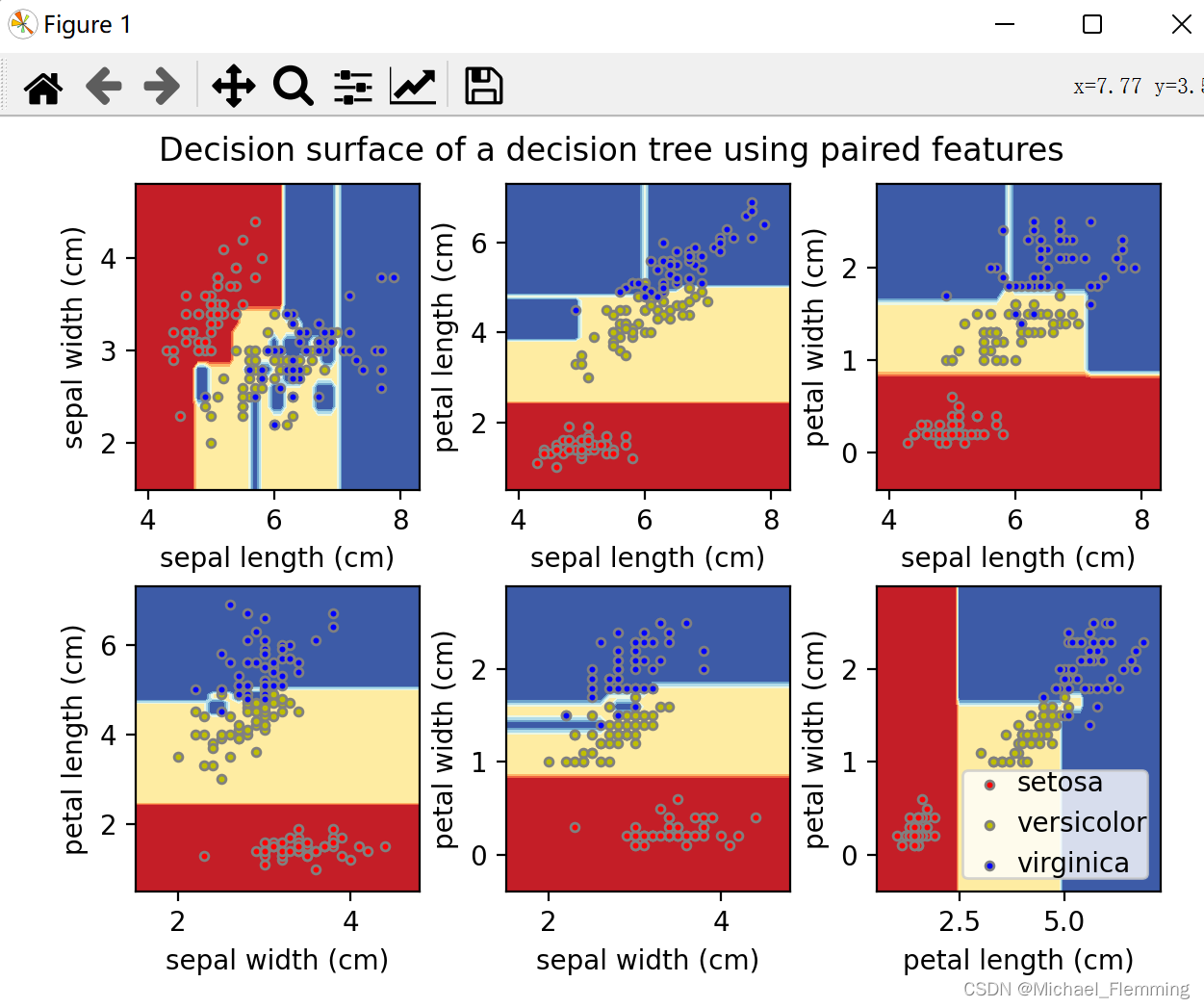
在iris数据集上绘制决策树的决策面
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn import tree
from sklearn.datasets import load_iris
from matplotlib import pyplot as plt
import numpy as np
# 加载数据
iris_data = load_iris()
# 创建学习器对象
ctree = DecisionTreeClassifier()
fig1 = plt.figure(1)
fig2 = plt.figure(2)
for idx, pair in enumerate([[0, 1], [0, 2], [0, 3], [1, 2], [1, 3], [2, 3]]):
# 获取训练数据
X, y = iris_data.data[:, pair], iris_data.target
# 拟合数据,训练学习器
ctree.fit(X, y)
# 对张图上所有网格点都做一个预测,以便画决策边界
# 注意:上面的y是标签,用来匹配颜色。矩阵X的两列分别对应x轴和y轴
x1_min, x1_max = X[:, 0].min(), X[:, 0].max()
x2_min, x2_max = X[:, 1].min(), X[:, 1].max()
x1x1, x2x2 = np.meshgrid(np.arange(x1_min - 0.5, x1_max + 0.5, 0.1), np.arange(x2_min - 0.5, x2_max + 0.5, 0.1))
plt.tight_layout(h_pad=0.5, w_pad=0.5, pad=2.5)
# 对网格上每一点进行预测
# 注意:predict不接受上面x1x1,x2x2的格式,需要处理,把x1x1,x2x2都展平
z = ctree.predict(np.c_[x1x1.ravel(), x2x2.ravel()]) # 现在z是一维数组
z = z.reshape(x1x1.shape) # 将z的形状变回去,才能画contour
plt.figure(1)
plt.subplot(2, 3, idx + 1)
# 设置坐标轴
plt.xlabel(iris_data['feature_names'][pair[0]])
plt.ylabel(iris_data['feature_names'][pair[1]])
# 画决策边界
plt.contourf(x1x1, x2x2, z, cmap=plt.cm.RdYlBu)
# 画散点图,不同类型的点颜色不同
for i, color in zip(range(3), 'ryb'): # 有3类
idxs = np.where(y == i)
plt.scatter(X[idxs, 0], X[idxs, 1], s=10, c=color, edgecolors='gray', label=iris_data['target_names'][i])
plt.tight_layout(h_pad=0.5, w_pad=0.5, pad=2.5)
plt.figure(2)
plt.subplot(2, 3, idx + 1)
tree.plot_tree(ctree, rounded=True, filled=True)
# 因为每一张图的标签都是一样的,只画最后一张图就行了。
plt.figure(1)
plt.suptitle("Decision surface of a decision tree using paired features")
plt.legend(loc='lower right', borderpad=0, handletextpad=0)
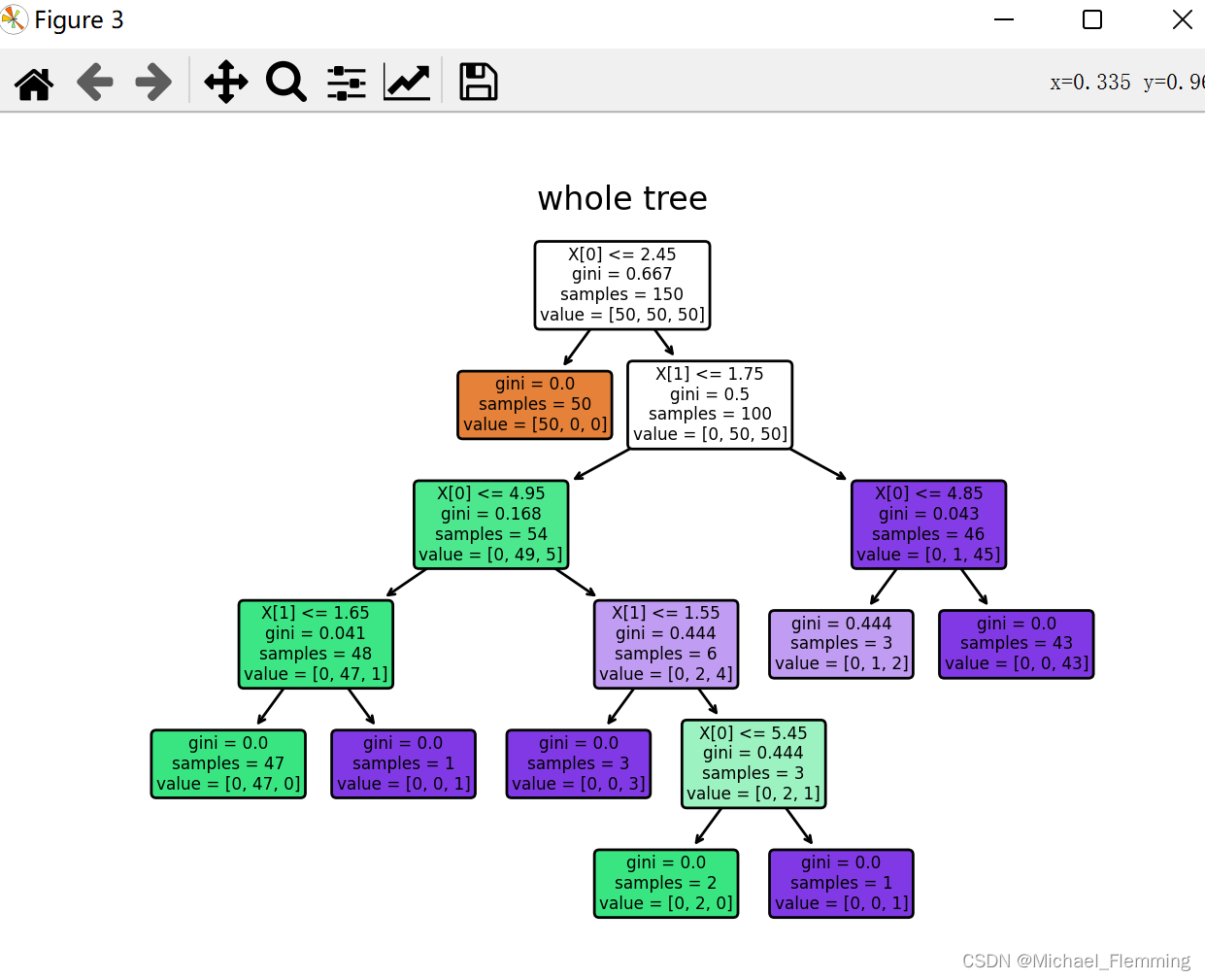
# 画出完整的tree
ctree.fit(X, y)
plt.figure()
tree.plot_tree(ctree, rounded=True, filled=True)
plt.title("whole tree")
plt.show()















 1333
1333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









