







作者:Kamil Polak翻译:刘思婧
校对:孙韬淳
本文约2700字,建议阅读5分钟本文为大家介绍了主题建模的概念、LDA算法的原理,示例了如何使用Python建立一个基础的LDA主题模型,并使用pyLDAvis对主题进行可视化。
图片来源:Kamil Polak
引言
主题建模包括从文档术语中提取特征,并使用数学结构和框架(如矩阵分解和奇异值分解)来生成彼此可区分的术语聚类(cluster)或组,这些单词聚类继而形成主题或概念。
主题建模是一种对文档进行无监督分类的方法,类似于对数值数据进行聚类。
这些概念可以用来解释语料库的主题,也可以在各种文档中一同频繁出现的单词之间建立语义联系。
主题建模可以应用于以下方面:
发现数据集中隐藏的主题;
将文档分类到已经发现的主题中;
使用分类来组织/总结/搜索文档。
有各种框架和算法可以用以建立主题模型:
潜在语义索引(Latent semantic indexing)
潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)
非负矩阵分解(Non-negative matrix factorization,NMF)
在本文中,我们将重点讨论如何使用Python进行LDA主题建模。具体来说,我们将讨论:
什么是潜在狄利克雷分配(LDA, Latent Dirichlet allocation);
LDA算法如何工作;
如何使用Python建立LDA主题模型。
什么是潜在狄利克雷分配(LDA, Latent Dirichlet allocation)?
潜在狄利克雷分配(LDA, Latent Dirichlet allocation)是一种生成概率模型(generative probabilistic model),该模型假设每个文档具有类似于概率潜在语义索引模型的主题的组合。
简而言之,LDA背后的思想是,每个文档可以通过主题的分布来描述,每个主题可以通过单词的分布来描述。
LDA算法如何工作?
LDA由两部分组成:
我们已知的属于文件的单词;
需要计算的属于一个主题的单词或属于一个主题的单词的概率。
注意:LDA不关心文档中单词的顺序。通常,LDA使用词袋特征(bag-of-word feature)表示来代表文档。
以下步骤非常简单地解释了LDA算法的工作原理:
1. 对于每个文档,随机将每个单词初始化为K个主题中的一个(事先选择K个主题);
2. 对于每个文档D,浏览每个单词w并计算:
P(T | D):文档D中,指定给主题T的单词的比例;
P(W | T):所有包含单词W的文档中,指定给主题T的比例。
3. 考虑所有其他单词及其主题分配,以概率P(T | D)´ P(W | T) 将单词W与主题T重新分配。
LDA主题模型的图示如下。
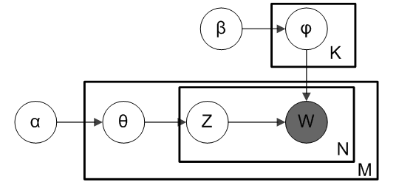
图片来源:Wiki

下图直观地展示了每个参数如何连接回文本文档和术语。假设我们有M个文档,文档中有N个单词,我们要生成的主题总数为K。
图中的黑盒代表核心算法,它利用前面提到的参数从文档中提取K个主题。

图片来源:Christine Doig
如何使用Python建立LDA主题模型
我们将使用Gensim包中的潜在狄利克雷分配(LDA)。
首先,我们需要导入包。核心包是re、gensim、spacy和pyLDAvis。此外,我们需要使
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









