







来源:专知
本文约2000字,建议阅读5分钟
在本教程中,我们提供了一种以人为中心的方法来理解神经网络的鲁棒性,使AI能够在社会中正常运行。
神经网络提供了具有普遍适用性和任务独立性的表示空间,这些表示空间在图像理解应用中得到了广泛应用。图像数据中特征交互的复杂语义已被分解为一组非线性函数、卷积参数、注意力机制以及多模态输入等。这些操作的复杂性引入了神经网络架构中的多种漏洞,包括对抗样本、自信校准问题和灾难性遗忘等。鉴于人工智能有望引领第四次工业革命,理解和克服这些漏洞至关重要。实现这一目标需要创建驱动AI系统的鲁棒神经网络。然而,定义鲁棒性并非易事。简单的对噪声和扰动不变性的测量在现实环境中并不适用。在本教程中,我们提供了一种以人为中心的方法来理解神经网络的鲁棒性,使AI能够在社会中正常运行。因此,我们提出以下几点:
所有神经网络必须向人类提供上下文相关的解释。
神经网络必须知道它们不知道的内容和范围。
神经网络必须允许人在决策阶段进行干预。
这三点要求鲁棒的神经网络具有可解释性、具备不确定性量化,并且能够被干预。
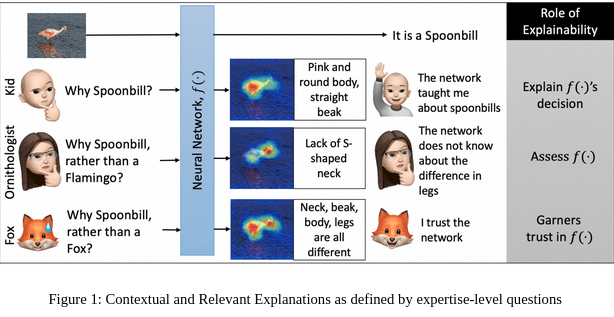
我们提供了一个基于概率的事后分析,以实现可解释性、不确定性和可干预性。事后分析意味着决策已经做出。一个简单的事后上下文相关解释的例子如图1所示。对于一个训练良好的神经网络,常规解释回答了“为什么是琵鹭?”的问题,通过突出鸟的身体。然而,一个更相关的问题可能是“为什么是琵鹭,而不是火烈鸟?”这样的提问需要提问者了解火烈鸟的特征。如果网络显示区别在于没有S形的颈部,那么提问者会对所提供的上下文回答感到满意。上下文解释不仅建立信任,还评估神经网络并解释其决策。在更大的背景下,可解释性的目标必须是满足各种水平的专家的需求,包括研究人员、工程师、政策制定者和普通用户。在本教程中,我们详细介绍了一种基于梯度的方法,能够提供上述所有解释而无需重新训练。一旦神经网络被训练,它就像一个知识库,不同类型的梯度可以用来遍历对抗性、对比性、解释性、反事实表示空间。除了解释外,我们还展示了这些梯度在定义不确定性和可干预性方面的实用性。我们将讨论多种图像理解和鲁棒性应用,包括异常检测、新奇检测、对抗性样本检测、分布外图像检测、图像质量评估和噪声识别实验等。在本教程中,我们将审视鲁棒性作为一种以人为中心的衡量大规模神经网络实用性的方法的类型、视觉含义和解释。
教程大纲
本教程由四个主要部分组成:
第一部分:神经网络中的推理讨论一些关于使用分布外(OOD)数据训练神经网络的近期令人惊讶的结果,其结论是,在大数据环境中何时及如何使用OOD数据并不总是明确的。我们将以此作为课程材料的动机。
第二部分:推理中的可解释性介绍每一种可解释性、不确定性和可干预性的基本数学框架。
第三部分:推理中的可解释性和不确定性详细讨论可解释性和不确定性。
第四部分:推理中的可干预性专门讨论可干预性。
第五部分:结论与未来方向总结和探讨未来的发展方向。
每部分的具体内容和讲解者如下所示。
参考文献:
[1] AlRegib, Ghassan, and Mohit Prabhushankar. “Explanatory Paradigms in Neural Networks: Towards relevant and contextual explanations.” IEEE Signal Processing Magazine 39.4 (2022): 59-72.
[2] M. Prabhushankar, and G. AlRegib, “Introspective Learning : A Two-Stage Approach for Inference in Neural Networks,” in Advances in Neural Information Processing Systems (NeurIPS), New Orleans, LA,, Nov. 29 – Dec. 1 2022.
[3] Kwon, G., Prabhushankar, M., Temel, D., & AlRegib, G. (2020). Backpropagated gradient representations for anomaly detection. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI 16, Springer International Publishing.
[4] M. Prabhushankar and G. AlRegib, “Extracting Causal Visual Features for Limited Label Classification,” IEEE International Conference on Image Processing (ICIP), Anchorage, AK, Sept 2021.
[5] Selvaraju, Ramprasaath R., et al. “Grad-cam: Visual explanations from deep networks via gradient-based localization.” Proceedings of the IEEE international conference on computer vision. 2017.
[6] Prabhushankar, M., Kwon, G., Temel, D., & AlRegib, G. (2020, October). Contrastive explanations in neural networks. In 2020 IEEE International Conference on Image Processing (ICIP) (pp. 3289-3293). IEEE.
[7] G. Kwon, M. Prabhushankar, D. Temel, and G. AlRegib, “Novelty Detection Through Model-Based Characterization of Neural Networks,” in IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, Oct. 2020.
[8] J. Lee and G. AlRegib, “Gradients as a Measure of Uncertainty in Neural Networks,” in IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, Oct. 2020.
[9] M. Prabhushankar*, G. Kwon*, D. Temel and G. AIRegib, “Distorted Representation Space Characterization Through Backpropagated Gradients,” 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 2019, pp. 2651-2655. (* : equal contribution, Best Paper Award (top 0.1%))
[10] J. Lee, M. Prabhushankar, and G. AlRegib, “Gradient-Based Adversarial and Out-of-Distribution Detection,” in International Conference on Machine Learning (ICML) Workshop on New Frontiers in Adversarial Machine Learning, Baltimore, MD, Jul., 2022.























 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









