







来源:深度学习这件小事
本文约1500字,论文复现了一遍建议阅读5分钟
本文为你介绍关于难分样本的挖掘,如何将难分样本抽取出来。最近看了几篇文章关于难分样本的挖掘,如何将难分样本抽取出来,通过训练,使得正负样本数量均衡。一般用来减少实验结果的假阳性问题。
Training Region-based Object Detectors with Online Hard Example Mining
论文:https://arxiv.org/pdf/1604.03540.pdf
代码:https://github.com/abhi2610/ohem
01、概念
对于分类来说:
正样本:我们想要正确分类出的类别所对应的样本,例如,我们需要对一张图片分类,确定是否属于猫,那么在训练的时候,猫的图片就是正样本。
负样本:根据上面的例子,不是猫的其他所有的图片都是负样本。
难分正样本(hard positives):错分成负样本的正样本,也可以是训练过程中损失最高的正样本。
难分负样本(hard negatives):错分成正样本的负样本,也可以是训练过程中损失最高的负样本。
易分正样本(easy positive):容易正确分类的正样本,该类的概率最高。也可以是训练过程中损失最低的正样本。
易分负样本(easy negatives):容易正确分类的负样本,该类的概率最高。也可以是训练过程中损失最低的负样本。
02、核心思想
用分类器对样本进行分类,把其中错误分类的样本(hard negative)放入负样本集合再继续训练分类器。
关键是找出影响网络性能的一些训练样本,针对性的进行处理。
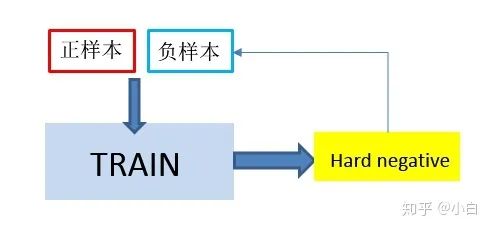
简单来说就是把难分的样本,剔除出来,放到另外一个地方里面。最后将难分样本,给负样本,加强训练分类器。但是,这样又会造成数据不平衡的问题,下面会讲到。
03、方法:离线和在线
离线:
在样本训练过程中,会将训练结果与GroundTruth计算IOU。通常会设定一个阈值(0.5),结果超过阈值认为是正样本,低于一定阈值的则认为是负样本,然后扔进网络中训练。
但是,随着训练的进行,这样的策略也许会出现一个问题,那就是正样本的数量会远远小于负样本,这样会导致数据的分布不平衡,使得网络的训练结果不是很好。
当然有些论文作者针对这种导致不平衡的数据,提出了一种对称的模型。就是类似上图,将Hard Posiotive也重新赋给正样本。
在线:
CVPR2016的Training Region-based Object Detectors with Online Hard Example Mining(oral)将难分样本挖掘(hard example mining)机制嵌入到SGD算法中,使得Fast R-CNN在训练的过程中根据region proposal的损失自动选取合适的Region Proposal作为正负例训练。
上面的论文就是讲的在线的方法:Online Hard Example Mining,简称OHEM
实验结果表明使用OHEM(Online Hard Example Mining)机制可以使得Fast R-CNN算法在VOC2007和VOC2012上mAP提高 4%左右。
即:训练的时候选择hard negative来进行迭代,从而提高训练的效果。
简单来说就是从ROI中选择hard,而不是简单的采样。
Forward: 全部的ROI通过网络,根据loss排序;
Backward:根据排序,选择B/N个loss值最大的(worst)样本来后向传播更新model的weights.
这里会有一个问题,即位置相近的ROI在map中可能对应的是同一个位置,loss值是相近的,所以针对这个问题,提出的解决方法是:对hard做nms,然后再选择B/N个ROI反向传播,这里nms选择的IoU=0.7。
在后向传播时,直觉想到的方法就是将那些未被选中的ROI的loss直接设置为0即可,但这实际上还是将所有的ROI进行反向传播,时间和空间消耗都很大,所以作者在这里提出了本文的网络框架,用两隔网络,一个只用来前向传播,另一个则根据选择的ROIs进行后向传播,的确增加了空间消耗(1G),但是有效的减少了时间消耗,实际的实验结果也是可以接受的。

给定图像和选择性搜索RoI,卷积网络计算转换特征映射。在(a)中,只读RoI网络在特征映射和所有RoI上运行正向传递(以绿色箭头显示)。然后Hard RoI模块使用这些RoI损失来选择B个样本。在(b)中,RoI网络使用这些硬性示例来计算前向和后向通道(以红色箭头示出)。
想法很类似于新扩展一个空间,错放错误样本,然后单独训练这些样本,更新权重。
04、扩展idea
难分样本挖掘的思想同样可以利用到图像的语义分割上。
可以对难以分割的样本,或者无法分割的样本,单独建立字典或者模型来训练,更新网络权重。
用于不平衡数据的扩增也是一个不错的选择。
文中图片中的思想可以借鉴哦。读者可以自定义一个自己的Hard ROI模块哟~
【参考】
https://blog.csdn.net/u014381600/article/details/79161261
https://blog.csdn.net/qq_29981283/article/details/83350062
https://blog.csdn.net/u013608402/article/details/51275486
编辑:于腾凯
校对:林亦霖
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









