







来源:专知
本文为论文介绍,建议阅读5分钟
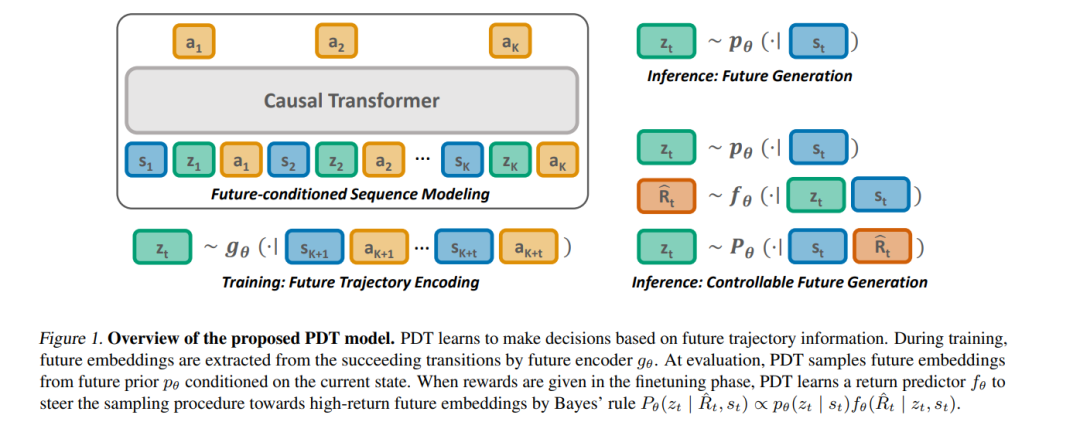
我们提出了预训练决策变换器(PDT),这是一种在概念上简单的无监督RL预训练方法。近期在离线强化学习(RL)的研究中,我们发现基于回报的监督学习是解决决策问题的强大范式。然而,尽管有前景,但基于回报的方法仅限于使用标注有奖励的训练数据,因此在从无监督数据中学习时面临挑战。在这项工作中,我们旨在利用泛化的未来条件,以实现从无奖励和次优离线数据中进行有效的无监督预训练。我们提出了预训练决策变换器(PDT),这是一种在概念上简单的无监督RL预训练方法。PDT利用未来轨迹信息作为特权上下文在训练期间预测动作。能够根据当前和未来因素做出决策,增强了PDT的泛化能力。此外,这个特性可以很容易地融入到基于回报的框架中进行在线微调,通过为可能的未来分配回报值并根据各自的值采样未来嵌入。从实证上看,PDT的表现优于或与其监督预训练的对手相当,特别是在处理次优数据时。进一步分析表明,PDT能够从离线数据中提取出多样的行为,并通过在线微调可控地采样高回报行为。代码可在此处获取。
https://arxiv.org/abs/2305.16683
















 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









