







本文约5800字,建议阅读10+分钟
本文为我们带来了 2023 年最值得大家关注,也是最有影响力的十篇 AI 论文。
一年又过去,这一年,AI 圈子以一种“狂飙突进”的速度飞速发展,哪怕在这个领域深耕多年的学者们也开始感叹“从没有见过哪个领域在哪一年如同 AI 领域在 这样如此飞速的发展与不断的进化”,毫无疑问,这一年 AI,尤其是大模型的爆发将会深刻影响未来我们生活的方方面面。
抱着年终总结,也是对过去一年回顾与展望的态度,来自 Ahead AI 的 Sebastian Raschka 博士为我们带来了 2023 年最值得大家关注,也是最有影响力的十篇 AI 论文,这里我们就和大家一起,用这十篇工作再次为 2023 年写下一段注脚(十篇论文不分先后)~
Pythia — 大模型该如何训练?
来自 Eleuther AI 和耶鲁大学的学者们在 4 月份发布的论文《Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling》中发布了开源模型 Pythia,Pythia 由 8 个参数范围从 70M 到 12B 的大模型组成,并且,划重点, Pythia 从权重到数据做到了完完全全的开源,可以面向商业用途直接使用。
而除了“开源”,Pythia 论文的真正价值在于,它给出了一套完整而又详细的“大模型训练方案”,发布了 Pythia 的训练细节,并且对训练过程进行了详细的分析与充分的实验,在多个细节之处给出了出色的洞见与理解。
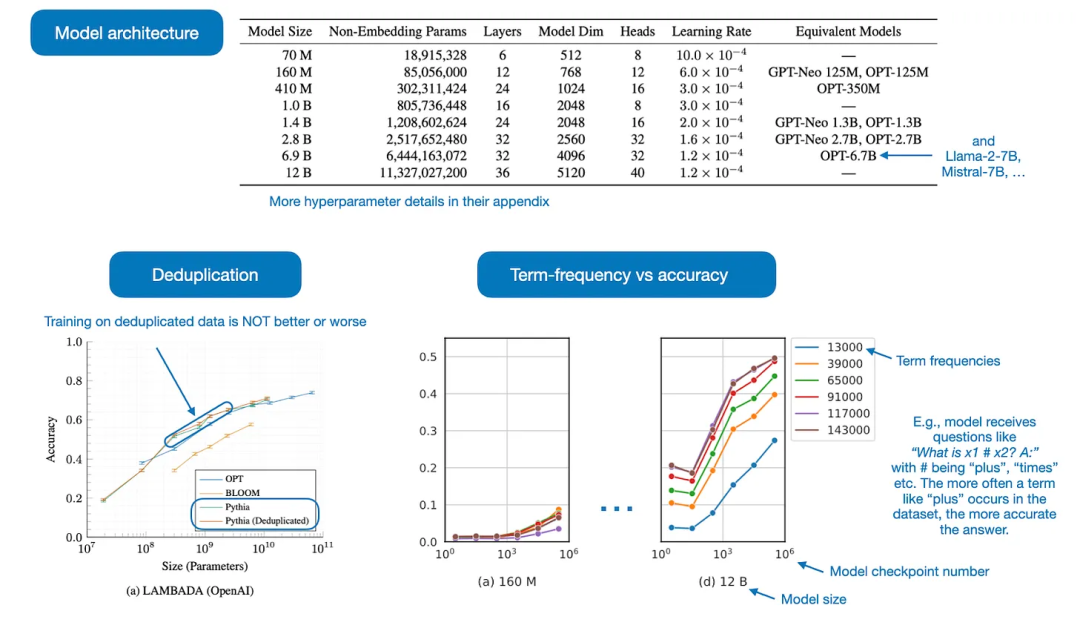
Pythia 给出的经验法则包括:
对重复数据进行预训练会带来什么问题?答:删除重复数据既不会增强模型性能也不会损害模型性能
训练顺序会影响模型记忆吗?答:不会,重新排序训练数据不会减轻模型的“逐字记忆”问题
预训练中,一些术语的频率会影响下游任务吗?答:会的,出现频次更高的术语在 few-shot 中准确往往更高
增强 batch 大小如何影响模型的训练?答:增加 batch 将会使得训练时间减半,但不会损害其收敛性
入选理由:不仅仅因为开源了一个大模型,Pythia 用大量实验与优美的文字回答了大模型训练过程中的许多有趣问题,细节翔实,过程透明。
论文题目:
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
论文链接:
https://arxiv.org/pdf/2304.01373.pdf
发表时间:2023 年 4 月 3 日
Llama 2 — 开源模型之王
作为 Meta AI 广受好评的 Llama 1 的续作,《Llama 2: Open Foundation and Fine-Tuned Chat Models》公布的从 7B 到 70B 的一系列大模型当今天也仍然是世界范围内功能最强大与使用最为广泛的开源模型之一。
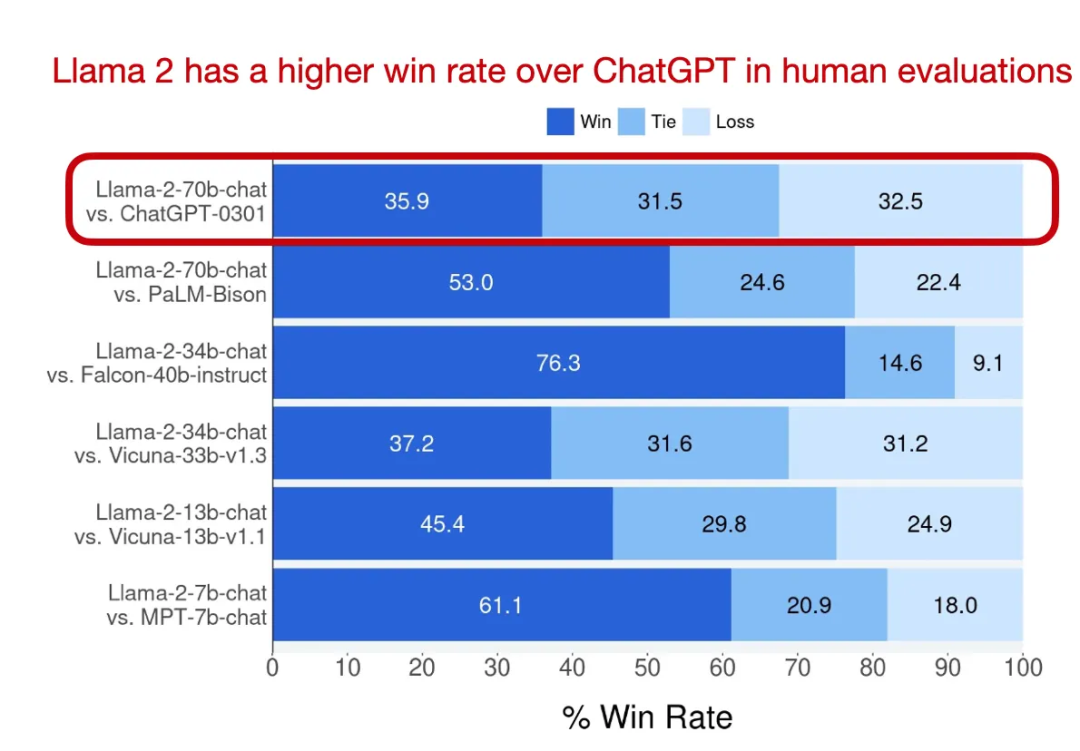
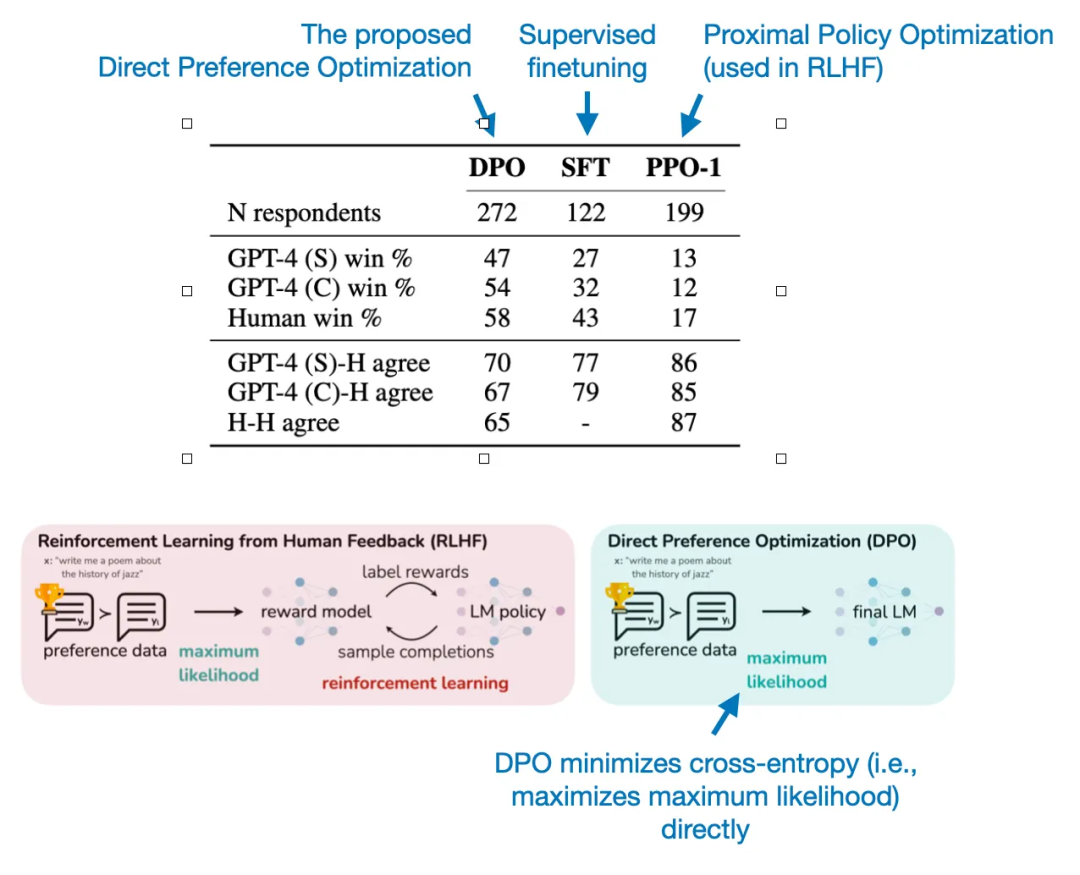
在模型方面,Llama 2 与许多其他 LLM 的区别在于,Llama 2 是目前市面上不多的经过了 RLHF 微调后的模型
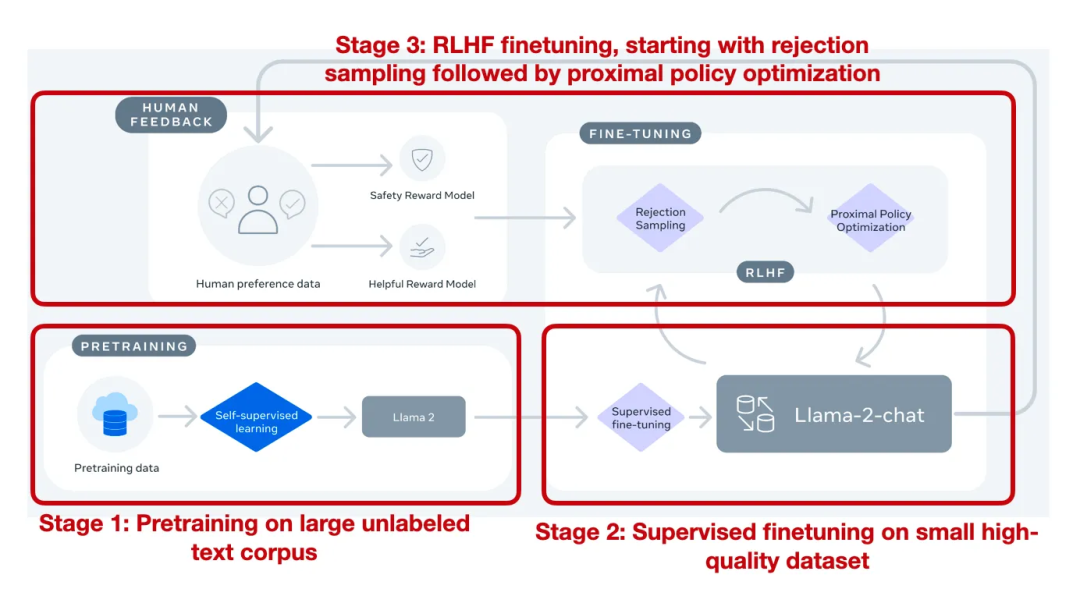
此外,Llama 2 77 页的论文中记录的技术细节也是为开源社区留下的一笔不可多得的财富,其中记录的如从最开始的有监督微调(SFT-v1) 到最终使用 PPO + RLHF 微调(RLHF-v5) 的演变历程,也可以促使人们更多的思考大模型这项技术的持续改进。
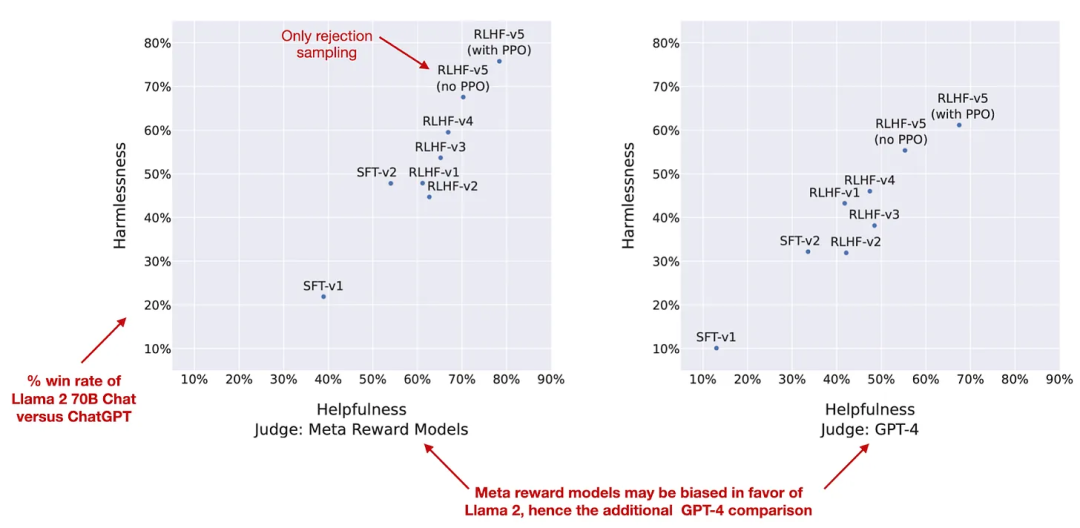
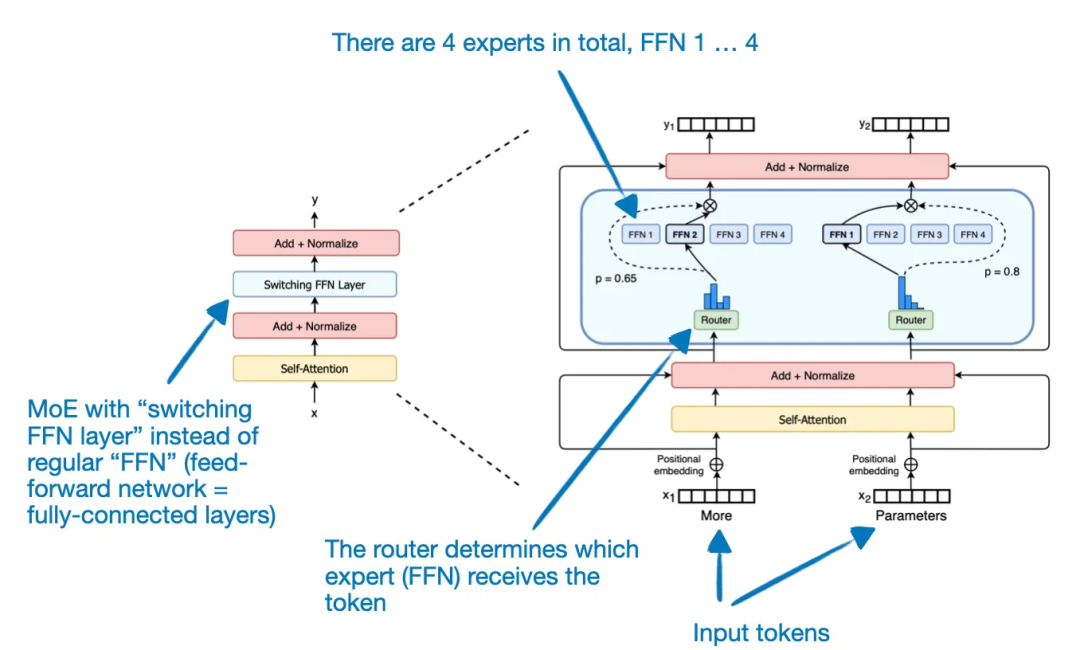
尽管目前可能 Mistral-8x7B、DeepSeek-67B 和 YI-34B 等模型在大量基准测试中的表现优于作为靶子的 Llama-2-70B,但放眼望去在公开可用的 LLM 中,Llama 2 仍然是大家的不二选择。
入选理由:尽管许多大公司现在都在推出自己专有的大模型,但看到 Meta 在开源领域内的深耕还是让人眼前一亮
论文题目:Llama 2: Open Foundation and Fine-Tuned Chat Models
论文链接:
https://arxiv.org/pdf/2307.09288.pdf
发表时间:2023 年 7 月 18 日
QLoRA — 高效微调
QLoRA 可能是目前大模型微调这个领域最亮眼的一颗明星,《QLoRA: Efficient Finetuning of Quantized LLMs》这篇论文建立在流行的 LoRA 技术基础之上,提出了一种更加内存高效的微调方法,使得更大的模型可以放进显存更小的 GPU。
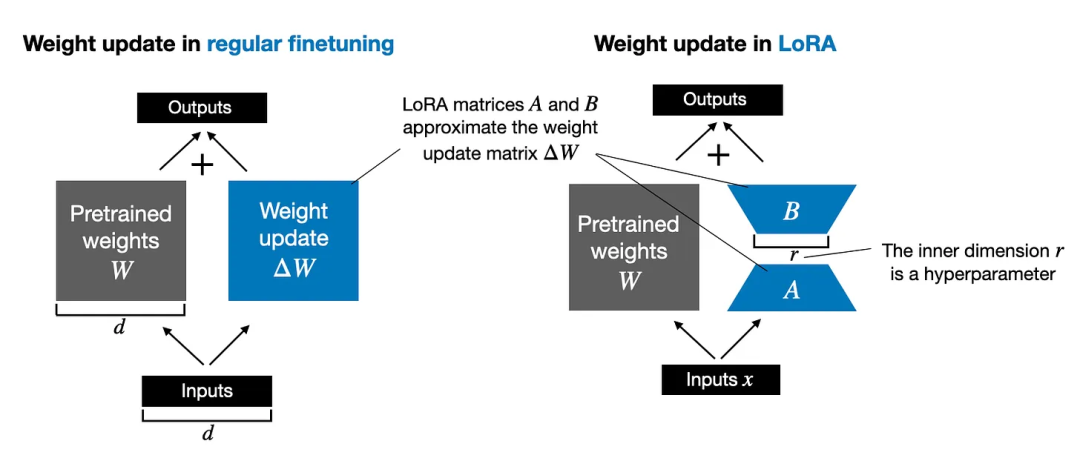
LoRA 的技术原理如上图所示,将更新权重拆成两个低秩矩阵相乘的形式,降低了模型微调的资源需求。而 QLoRA 指经过量化处理的 LoRA,通过将 LoRA 中的低秩矩阵的连续值范围映射到一组有限的离散区间,以降低其数值精度需求,而减少模型的内存占用和计算需求。
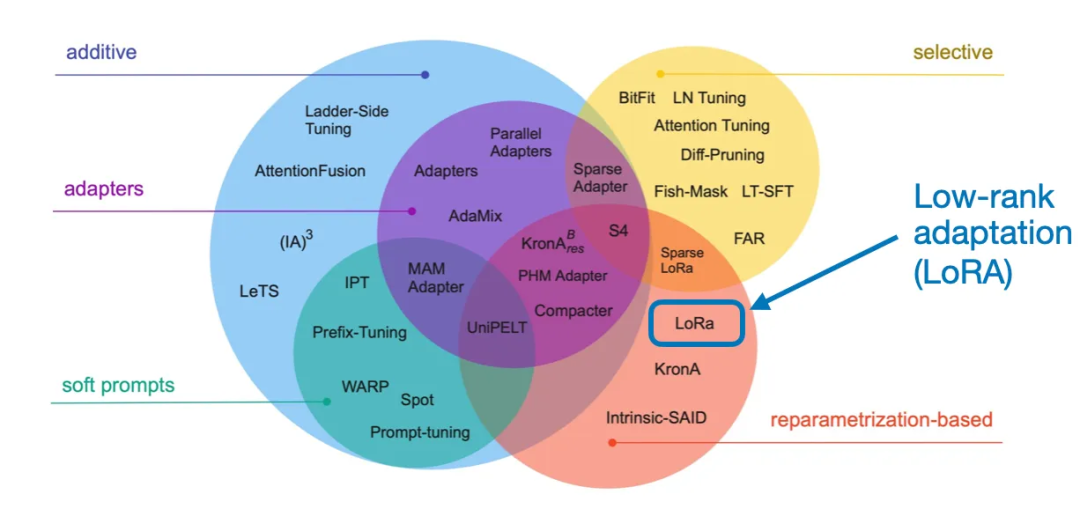
在 QLoRA 的论文中,QLoRA 大大降低了 65B Llama 的内存需求,使得其可以被单个显存 48GB 的 GPU(A100) 所训练,使用 QLoRA 经过 24 个小时的微调就达到了 ChatGPT 性能的 99.3% ,当然由于多了一步映射,导致 QLoRA 的计算时长略长于普通的 LoRA。

入选理由:大模型微调问题与大模型问题本身一样重要,而 QLoRA 给出了一种方便优雅的工具通过降低 GPU 显存需求而使得大模型微调更加容易
论文题目:QLoRA: Efficient Finetuning of Quantized LLMs
论文链接:
https://arxiv.org/pdf/2305.14314.pdf
发表时间:2023 年 5 月 23 日
BloombergGPT — 垂直领域大模型翘楚
区别于其他论文,《BloombergGPT: A Large Language Model for Finance》可能并没有提出什么突破性的新见解或新方法。但是这个由全球商业、金融信息和财经资讯的巨头公司 Bloomberg(彭博)发布的今日大模型,在一众垂直领域模型越来越 “close” 的大趋势下,还将垂直领域模型训练方法描述的如此详尽实属不多见。
具体而言,BloombergGPT 是一个投资数百万美元的 500 亿参数的金融领域大模型,使用了来自金融行业专用的数据集进行训练(包含 3630 亿的垂直数据以及 3450 个通用公开数据)。由于使用了 Chinchilla 缩放法则,相比之下,GPT-3 的大小是其的 3.5 倍,但是训练数据量却少了 1.4 倍。
入选理由:BloombergGPT 是一个垂直领域大模型训练的有趣实例与示范性研究。在商业秘密变得越来越重要的当下,对希望在垂直领域训练大模型的研究者们而言,这是一篇不可多得的实用参考文献。
论文题目:BloombergGPT: A Large Language Model for Finance
论文链接:
https://arxiv.org/pdf/2303.17564.pdf
发表时间:2023 年 3 月 30 日
DPO — 对 RLHF 的革命性技术
《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》的入选可以说是毫无悬念。RLHF 是一项成功而又有用的技术,但是无论是在 ChatGPT 中,还是在 Llama 2 中,它的实现都复杂且繁琐,并且成本高昂。简单回顾一下 RLHF 的工作流程:
有监督微调:在下游任务数据集上进行微调
奖励建模:通过人类评估者给出的有关模型输出的反馈,创建奖励模型以学习预测“与人类价值观一致”的输出类型
PPO:使用强化学习的 PPO 算法利用奖励模型来调整模型策略

而 DPO 的突出贡献在于,通过推导使用下图的式子直接将 RLHF 中奖励建模的一步省略,使用简单的分类目标无需显式建模奖励模型就可以优化语言模型以符合人类偏好。
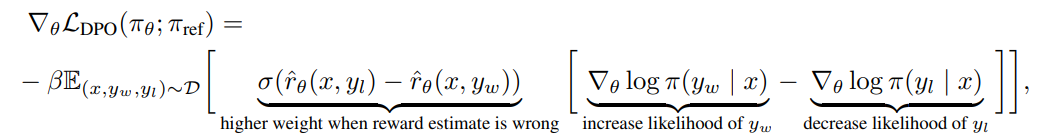
目前,一些模型开始使用 DPO 取代 RLHF 来作为大模型对齐方法,例如 Zephyr-7B 基于 Mistral-7B 使用了 DPO 进行微调,而 Zephyr-7B 的实验表明,使用 DPO 后它优于同期所有同尺寸的其他模型。
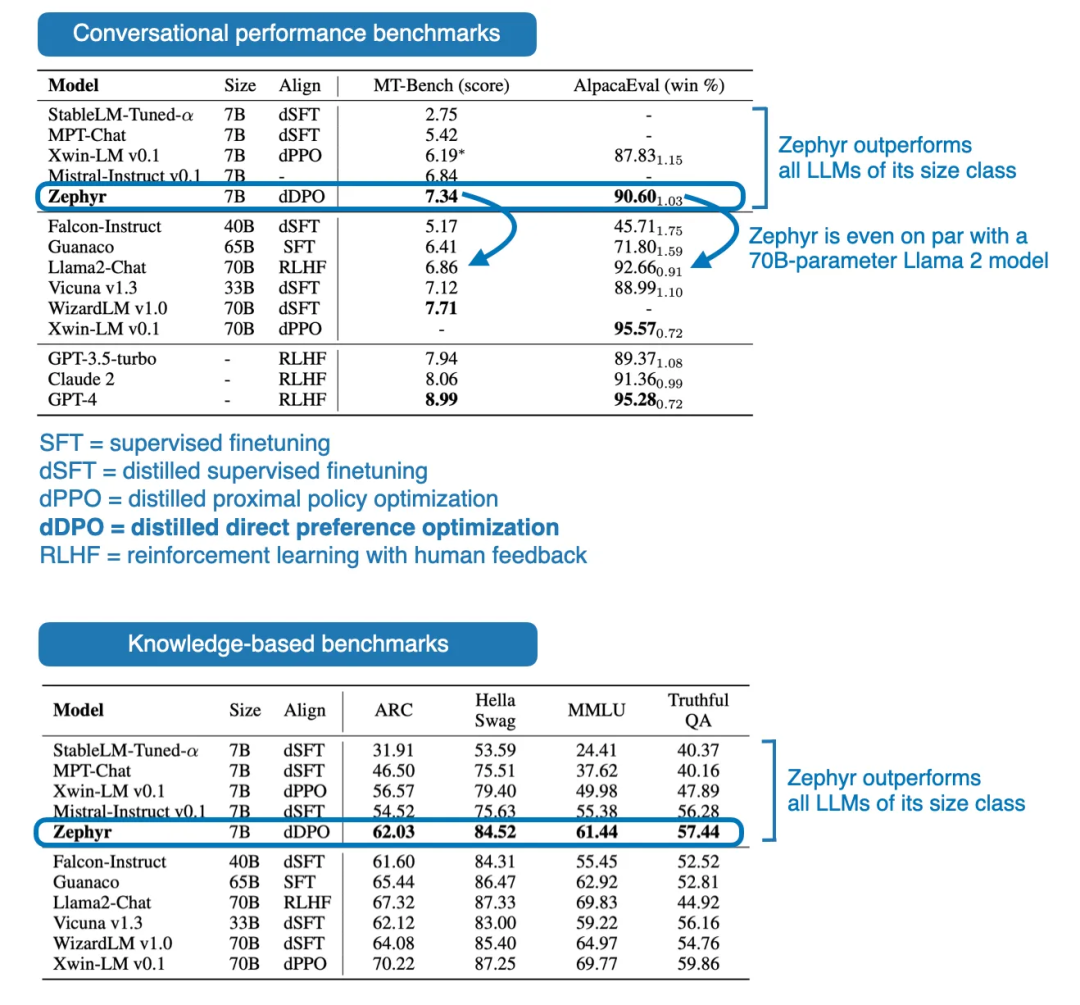
入选理由:DPO 以其令人印象深刻的简单性同样做到了复杂的 RLHF 所做到的事,其对问题的理解与公式推导堪称优美
论文题目:
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
论文链接:
https://arxiv.org/pdf/2305.18290.pdf
发表时间:2023 年 5 月 29 日
Mistral 7B — “小模型”的典范
《Mistral 7B》这篇论文的标题简洁到不符合任何学术论文的起名规范,但是它提出的模型却是相当有影响力的。作为基础模型,Mistral 7B 直接催生了另外两个著名的模型:前文提到的 Zephyr 7B 和最新的 Mistral Mixture of Experts(MoE)方法。
简而言之,《Mistral 7B》 论文提出了一个只有 7B 的小模型,但在各种基准测试中,其性能却超过了其他更大的模型,例如 13B 的 Llama 2 模型。Mistral 7B 也同时是 NeurIPS LLM 微调和效率挑战赛中获胜方案的基础模型。
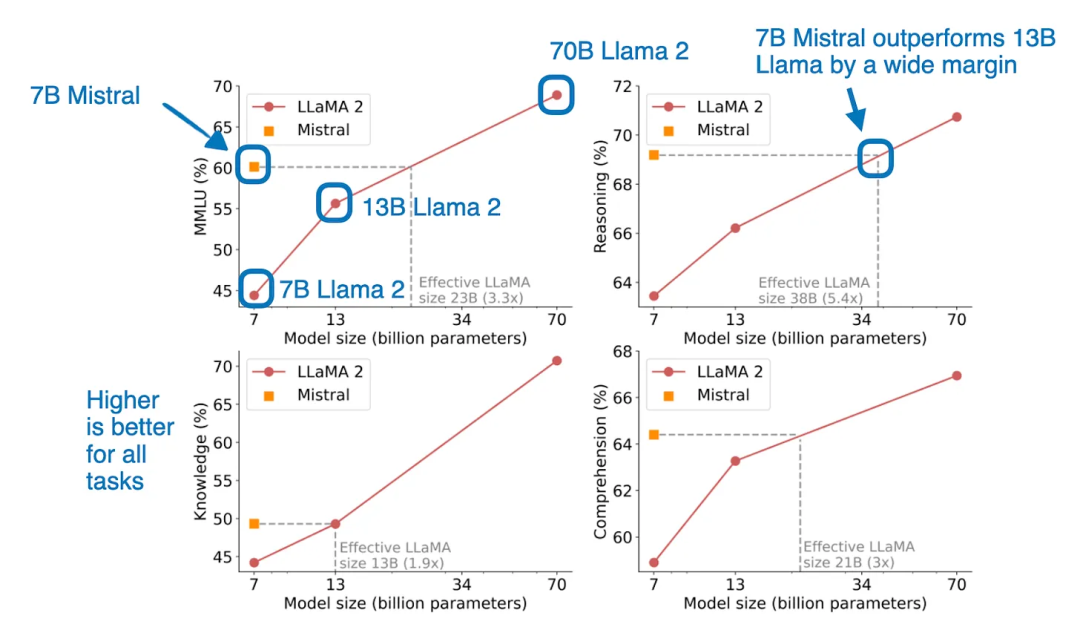
由于没有公布训练数据,因此 Mistral 7B 的优异表现是否来源于高质量的数据集还不能确定。而在架构方面,Mistral 7B 与 Llama 2 类似,不过多了一个滑动窗口注意力机制(Sliding Window Attention),以节省内存,增强计算效率并加快训练速度。滑动窗口注意力使得模型不必关注未来之前所有的 tokens,而只需要关注特殊数量的 tokens。
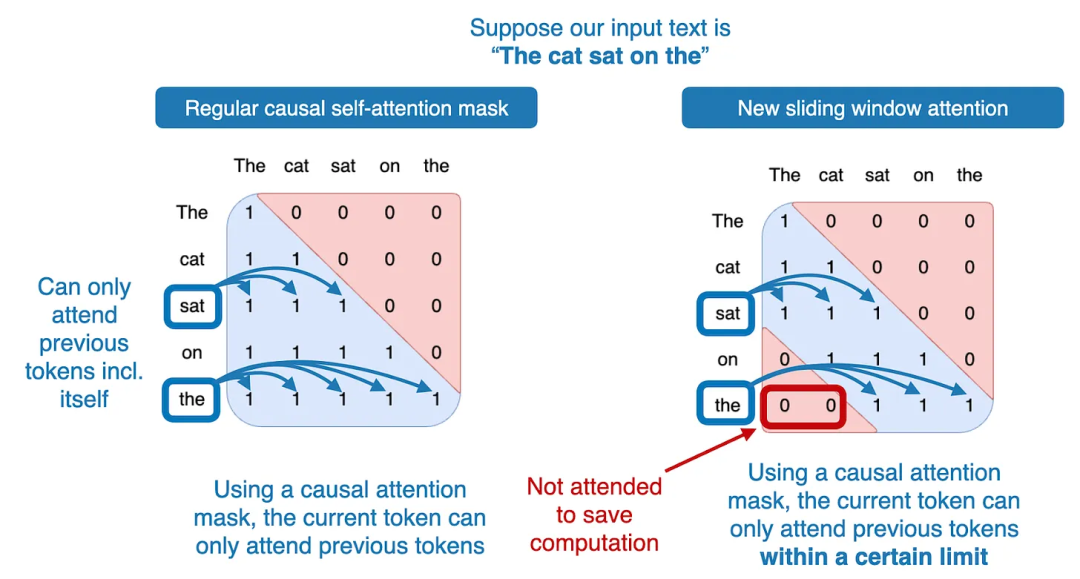
举个例子,当窗口大小为 4096 时,在常规的自注意力机制中,模型看到第 50000 个 token 时需要关注所有之前的 49999 个 token。而在滑动窗口自注意力中,Mistral 模型只需要关注 45904 到 50000 的 tokens。当然,尽管滑动窗口注意力对 Mistral 模型有可能带来了提升,但是其优异的性能应该不止是由于滑动窗口注意力。
在 Mistral 7B 的基础上,有两个值得关注的模型被提出,分别是 Zephyr 7B ——第一个经过 DPO 训练的优秀模型以及 Mistral Mixture of Experts (MoE),MoE 也称 Mixtral-8x7B,该模型在多个公共基准测试中的性能相当或超过了更大的 Llama-2-70B 模型。
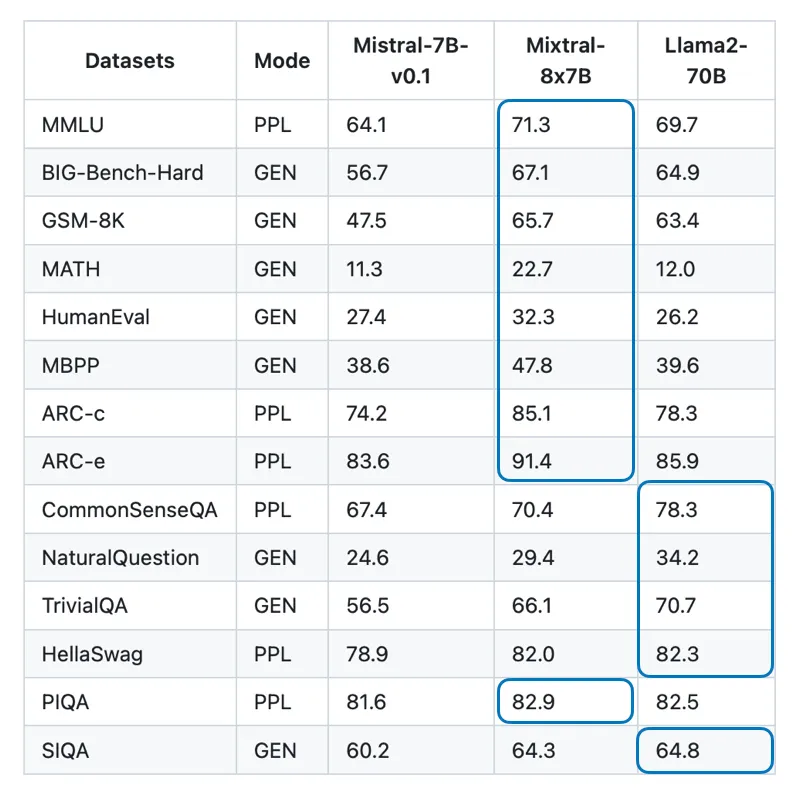
MoE 是一个非常有趣的模型,据传整个 2023 年大模型的带头大哥 GPT-4 就是一个由 16 个子模块组成的 MoE,而这 16 个子模块中的每一个都有 1110 亿个参数(做个对比,GPT-3 的参数量为 1750 亿)。Mixtral-8x7B 的一个显著不同就是这个 8x7B,这里首先, Mixtral-8x7B 是一款混合专家模型(Mixtrue of Experts),由8个拥有 70 亿参数的专家网络组成,对于每个输入 token,都输入两个专家网络进行处理,最后整个序列事实上来源于一系列「不同的两两专家」输出的组合。这里 MoE 方法仅应用于 FFN,因此其总的参数量并非 8*7-56,而是在 40-50B 左右。
不得不说,除了让模型越变越大以外,“小模型”也是 2023 年后期的一个主流趋势,除了 Mistral 7B 和 Zephyr 7B 以外,还有我们曾经介绍过的 Phi-2《微软官宣放出一个「小模型」,仅2.7B参数,击败Llama2和Gemini Nano 2》
入选理由:Mistral 7B 小而强大,并且催生了一系列在其基础上的小模型工作,在这些小模型的基础上,2024 年很有可能将开源模型推广到新的高度
论文题目:Mistral 7B
论文链接:
https://arxiv.org/pdf/2310.06825.pdf
发表时间:2023 年 10 月 10 日
Orca 2 — “小模型”如何推理?
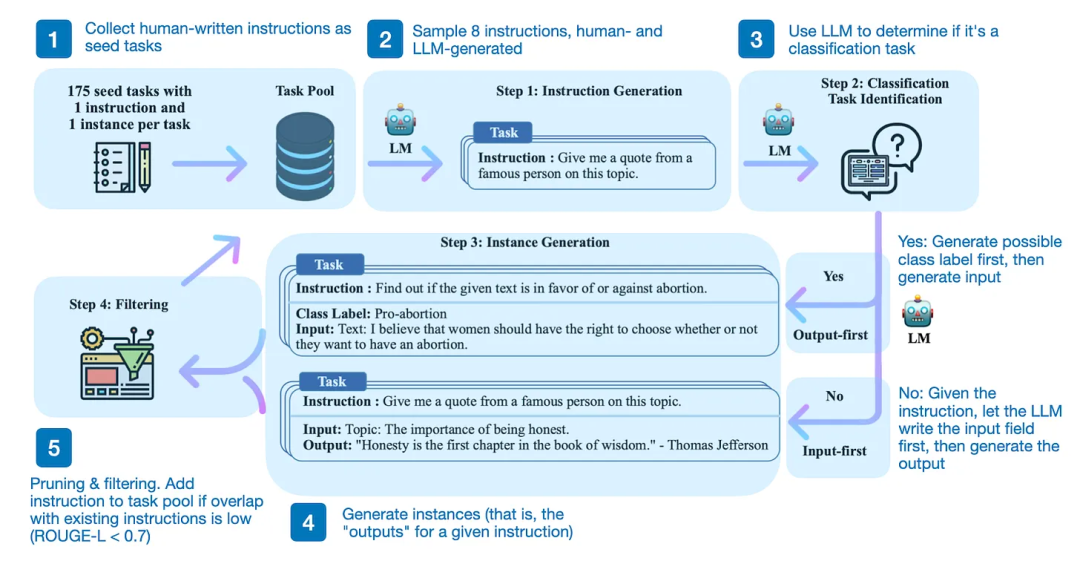
《Orca 2: Teaching Small Language Models How to Reason》是一篇面世不久的论文,但是 Orca 2 成功结合了两个漂亮的 idea。第一个是“是否可以从 GPT-4 这样的大模型中提取一些数据来训练小型的模型呢?”,Alpaca (一个在 ChatGPT 输出基础上微调 Llama 模型的方法)实现了这种想法,具体而言由四步组成:
构建任务种子池,包含一组由人工编写的指令与示例;
使用预训练的模型如 ChatGPT 确定任务类别;
给定新指令,输入 ChatGPT 获得回复;
将回复添加到任务种子池并进行过滤。
而第二个想法则是“高质量数据对于微调非常重要”,例如论文《LIMA: Less Is More for Alignment》给出了一个由人类生成的高质量数据集,仅仅包含一千个示例但是微调时却超越了在五万条由 ChatGPT 生成的示例中的微调结果。
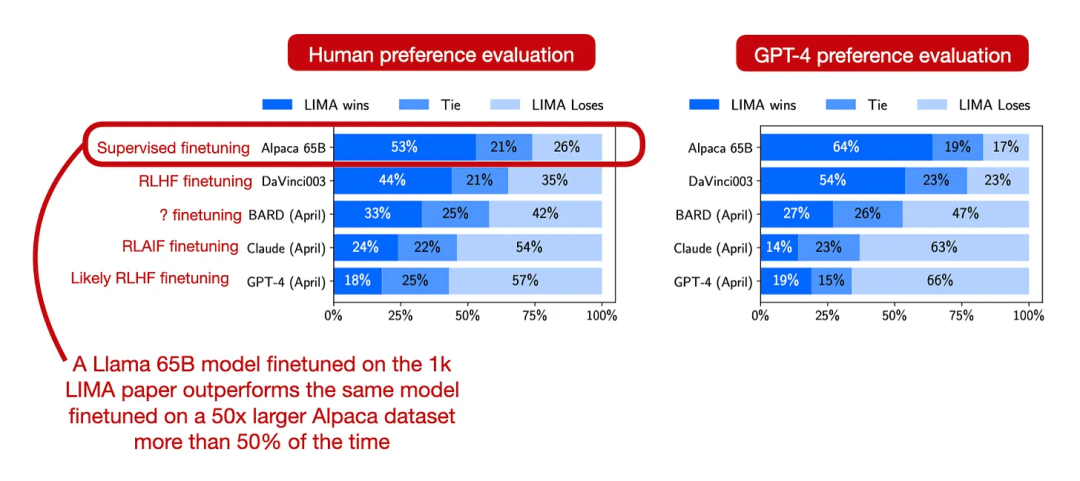
结合这两个想法,Orca 2 想完成的事呼之欲出,Orca 2 旨在向 7B 或 13B 的小模型“教授”各种推理技术并且帮助他们确定完全每项任务所应该使用的最佳策略,而实现方式则是从大模型中索取“解题思路”。这种方法使 Orca 2 的性能明显优于同尺寸的模型,甚至达到了与其 5-10 倍大的模型相当的结果。
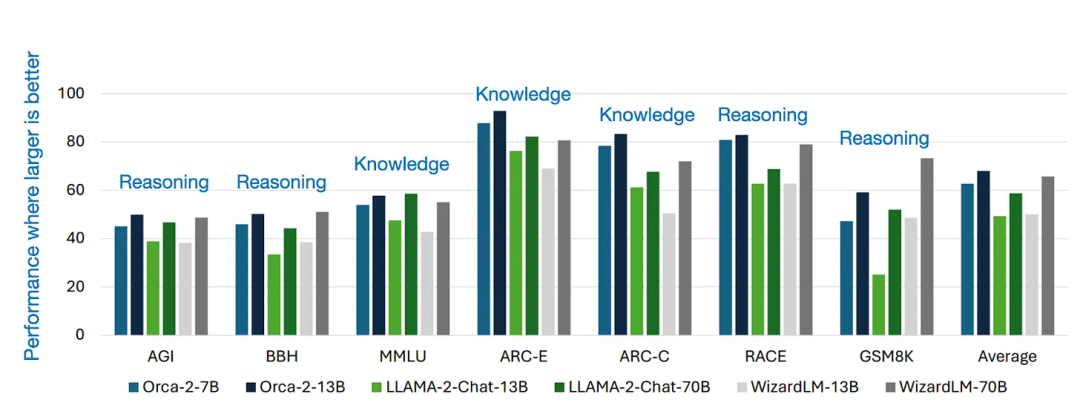
入选理由:尽管刚刚提出,但是 Orca 2 有可能为我们展现它在“改进的训练信号和方法使得小模型实现更强的推理能力”上的巨大潜力
论文题目:Orca 2: Teaching Small Language Models How to Reason
论文链接:
https://arxiv.org/pdf/2311.11045.pd
f发表时间:2023 年 11 月 18 日
CNN vs Transformer — CNN 也不弱于 ViT
接下来三篇从大模型转向计算机视觉领域,首当其冲是 DeepMind 的这篇短短五页的《ConvNets Match Vision Transformers at Scale》
深度学习的成功最早就来源于卷积神经网络,但是伴随着 ViT 的出现卷积逐渐没落,在视觉大模型的领域 ViT 独步天下,卷积神经网络逐渐被认为只能处理小型或中等规模数据集的任务。但是,DeepMind 的这篇工作相当“反直觉”的证明,当能够访问足够大的数据集时,卷积神经网络事实上可以与 ViT 竞争。
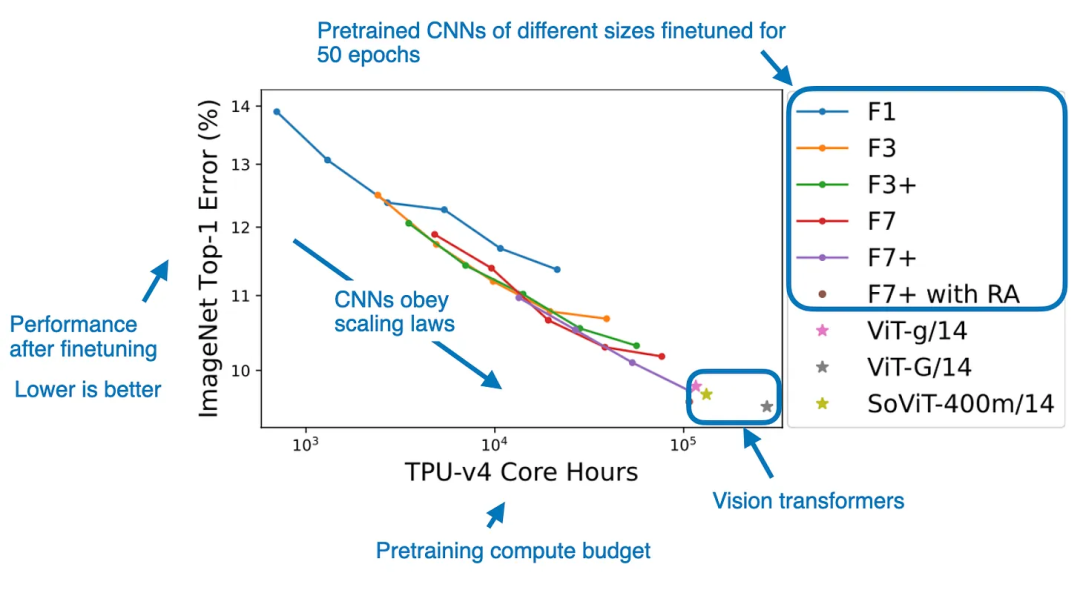
在实验中,通过使用高达 11 万个 TPU 小时的计算,论文对 ViT 和 CNN 进行了公平的比较。而结果是,当 CNN 使用类似于 ViT 通常使用的计算时间进行预训练时,它们完全可以匹敌 ViT 的性能。
入选理由:正本清源,这篇论文让 CNN 与 ViT 来了一场公平的对决,最终证明在同等计算条件下, CNN 也不弱于 ViT
论文题目:ConvNets Match Vision Transformers at Scale
论文链接:
https://arxiv.org/pdf/2310.16764.pdf
发表时间:2023 年 10 月 25 日
SAM — 分割一切!
去年上半年非常火热的由 Meta 发布的图像分割里程碑式的工作《Segment Anything》,这个被命名为 SAM 的模型可以在零样本的情况下真正如论文名字一样“分割一切”,作为一个通用模型,SAM 被认为已经学会了关于物体的一般概念,哪怕遇到训练中没有遇到的物体或图像,SAM 都可以“泛化”为此物体生成 mask,让大家直呼 CV 不存在了!
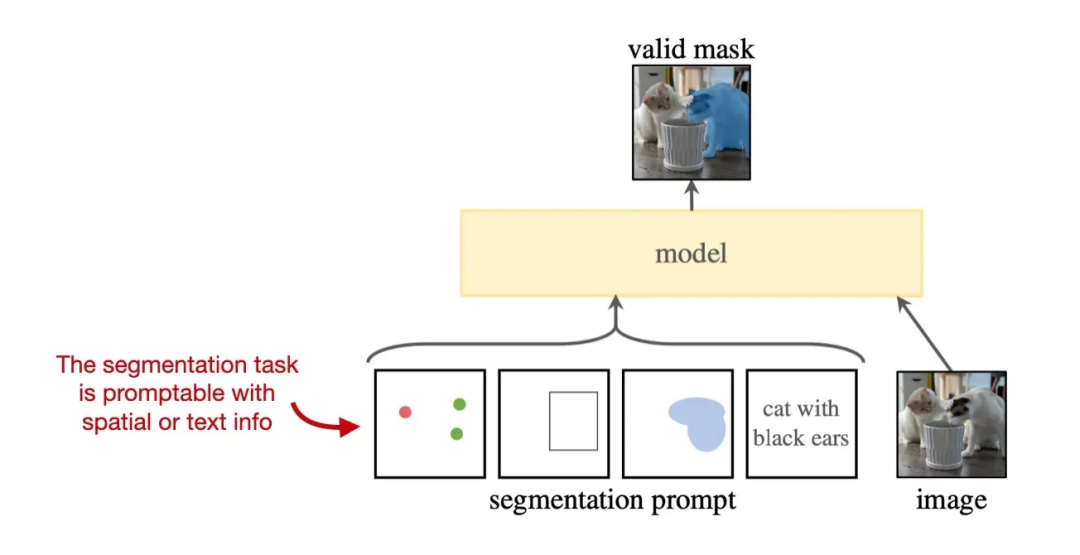
SAM 主要由三个组件组成,分别是:
图像编码器:使用预训练 ViT 作为图像编码器
Prompt 编码器:对输入的由点框组成的 Prompt 进行编码,使用 CLIP 与卷积实现
解码器:将图像嵌入,提示嵌入与输出标记进行解码,使用 Transformer 架构中的 Decoder 模块。
入选理由:CV 领域的 GPT-3 时刻!CV 不存在了
论文题目:Segment Anything
论文链接:
https://arxiv.org/pdf/2304.02643.pdf
发表时间:2023 年 4 月 5 日
Emu Video — 令人印象深刻的文本到视频生成模型
依然来自 Meta,这篇《Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning》提出了一个令人印象深刻的文本转视频模型。
Emu Video 在目前最大的一个文本到视频的数据集中进行训练,其中包含近 1000 万个样本,实验结果表明,Emu Video 生成视频的语义一致性超过 86%,质量一致性超过 91%。
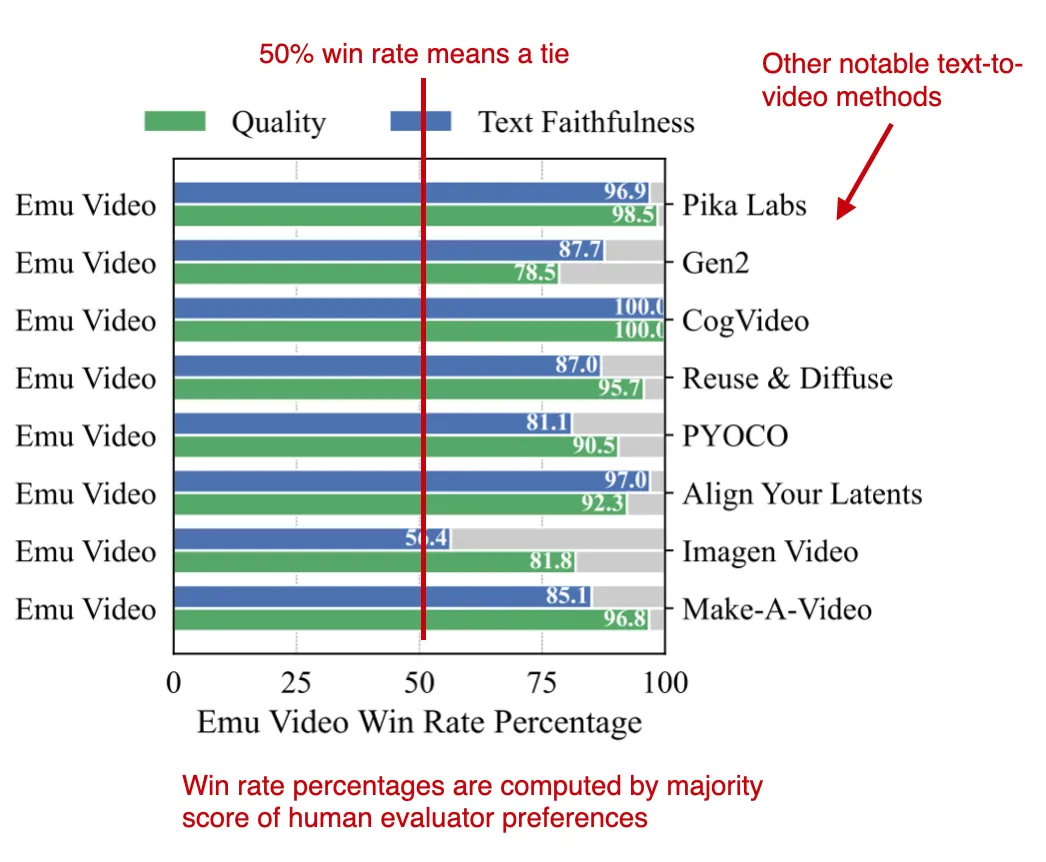
与之前的一众文本转视频方法相比,Emu Video 的设置相当简单,整个生成过程分为两步:首先使用扩散模型从文本生成图像,然后再根据文本+生成的图像创建视频,使用的模型依然是扩散模型。
通过将文本到视频的过程中间添加图像的阶段,从而简化了这一任务的难度。而在实际推理时,在给定一段文本后,Emu Video 先用文本到图像部分生成第一帧图像,再输入该图像及文本到视频部分生成完整的视频。
入选理由:2024 年文本到视频模型可能会相当流行,Emu Video 将会是一个承前启后的作品!
论文题目:Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
论文链接:
https://arxiv.org/pdf/2311.10709.pdf
发表时间:2023 年 11 月 17 日
总结
最后当然,这十篇论文只是 Sebastian Raschka 博士主观性很强的“评选与推荐”,可以看到这十篇还是更多关注在语言模型之中的进展,而对视觉等其他领域关注较少。也有许多论文比如 Medprompt、思维树 Tree of Thoughts 等等没有被提到。
所谓仁者见仁智者见智,希望大家可以在评论区广泛留言,补充这份“2023 十佳论文”的榜单。
22年11月30日,ChatGPT问世
23年2月1日,ChatGPT plus 版本上线
23年2月7日,微软宣布并发布集成ChatGPT功能的New Bing
23年2月7日,谷歌Bard首秀Demo并翻车
23年2月24日,Meta发布LLaMa 并开源
23年3月1日,OpenAI推出ChatGPT API,供开发者集成
23年3月14日 OpenAI发布GPT-4,并在ChatGPT和Bing中支持
23年3月16日,百度发布文心一言
23年上半年,国内百模大战开启
2023年3月14日,斯坦福发布Alpaca
23年3月17日,微软GPT-4 Office全家桶发布
23年3月21日,Midjourney v5版本画出100%逼真情侣
23年3月22日,Runway 重磅发布Gen-2,文生视频里程碑
23年3月24日,ChatGPT可以联网、添加插件
23年3月29日,千名大佬发联名信,叫停GPT-5超强大模型
23年3月31日,意大利暂时禁止ChatGPT使用
23年4月6日,Meta发布可以分割一切的Segment Anything
23年4月20日,Google Brain与DeepMind 合并成立 Google DeepMind
23年5月5日,微软BingChat全面开放
23年5月15日,OpenAI发布ChatGPT的iOs应用
2023年5月18日,特斯拉人形机器人进化
23年5月30日,谷歌宣布开放「生成式搜索平台」
23年6月14日,ChatGPT 大更新,API能力升级还降价
23年7月13日,马斯克高调官宣成立xAI
23年7月19日,Llama 2开源可商用
23年 8月10日,斯坦福「虚拟小镇」开源,引爆智能体研究
23年8月23日 GPT-3.5 Turbo正式开放微调功能
23年8月29日,OpenAI发布企业版ChatGPT:没有限制、更快、更强、更安全的GPT-4
23年9月21日,OpenAI推出DALL·E 3,并将原生集成至ChatGPT中
23年10月17日,文心大模型4.0发布
23年10月20日,ChatGPT全球宕机,API崩溃
23年10月29日,完全版GPT-4智能体:图像生成+插件+代码运行器+文件上传
23年11月7日,OpenAl首届开发者日官宣GPTs商店,推出更强版GPT-4 turbo
23年11月15日,奥特曼被OpenAI董事会开除系列事件
23年11月29日 文生视频产品Pika 1.0正式发布
23年12月6日,谷歌DeepMind发布Gemini系列模型
23年12月10日,最新开源模型Mixtral 超越LLama2和GPT-3.5
23年12月14日,谷歌官宣开放Gemini API,奥特曼宣布ChatGPT Plus恢复订阅
23年12月21日,MidJounery V6 发布
编辑:黄继彦













 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









