







来源:Ray中文社区 Anyscale博客
本文约3500字,建议阅读7分钟本文分享了如何使用 HuggingFace、DeepSpeed 和 Ray 组合的实用方法。By Waleed Kadous, Jun Gong, Antoni Baum and Richard Liaw | April 10, 2023
这是我们发布的关于生成式AI系列博客的第四篇。在之前的博客中,我们解释了为什么 Ray 是生成式人工智能领域一个可靠的平台,我们展示了它如何推进性能的极限,以及如何借助Ray使用Stable Diffusion。
这篇博客我们分享了如何使用 HuggingFace、DeepSpeed 和 Ray 组合的实用方法,在不到 40 分钟的时间内,以不到 7 美元的价格,对一个拥有 60 亿参数的模型,搭建一个微调和部署的大语言模型的系统。特别地,我们将阐述以下内容:
使用这三个组件,您可以简单、快速地组建一个开源的 LLM 微调和部署系统。
利用 Ray 的分布式能力,我们展示了这种方式比使用单个大型而难以获得的机器更具有成本效益且更快速。
接下来,我们将从以下几点内容展开:
讨论为什么您可能希望部署自己的大语言模型 ,而不是使用涌现的API提供商。
我们将展示自己观察到的一个正在发展的技术栈,它结合了 HuggingFace、DeepSpeed、Pytorch 和 Ray,被用于高性价比的 LLM 微调和部署。
我们将展示一个仅用40 行 Python 代码就能部署60亿参数的 GPT-J 模型的例子。
我们还将展示,在不到 7 美元的成本下,如何以分布式方式在低成本机器上微调该模型,借助莎士比亚的作品,使得它听起来更像是中世纪的,并且这比使用单个强大的大型机器要更具成本效益。
展示如何部署这个经过微调的 60 亿参数大语言模型。
将这个微调过的模型与使用大型系统进行prompt工程方法进行比较。
为什么我要运行我自己的大语言模型?
既然现在有很多提供大语言模型API的服务商,为什么你要自己部署一个大语言模型呢?有几个原因:
针对微调推理的成本:例如,OpenAI对Davinci上的微调模型收取12美分每1000个标记(约700个单词)。重要的是要记住,许多用户交互需要触发多个后端调用(例如,一个用于帮助生成提示,一个用于生成后的中和调整等),因此一个与终端用户的交互可能会花费几美元,而这对于许多应用程序来说是不可接受的成本。
延迟:调用大语言模型可能会特别慢。例如,一条GPT-3.5的查询可能消耗到30秒。加上几次从您的数据中心到服务商数据中心的往返通信,一条查询的耗时可能是分钟级的。同样,这对很多应用来说不可行的。LLM推理的内部化使得开发者可以优化应用的技术栈,例如使用低分辨率模型或者使用更大的批量查询单位等。根据我们获得的用户反馈,优化应用工作流通常会带来5倍或更多的延迟优化。
数据安全和隐私: 为了从这些API中获得响应,对于很多应用来说,开发者必须向他们发送大量数据(例如,发送一些内部文件的片段并要求系统对其进行总结)。许多API供应商保留了使用这些实例进行再训练的权利。考虑到组织数据的敏感性,还有常见的法律约束,如数据主权,这一点尤其具有局限性。尤其是最近的发展表明,人们有能力从已经学习好的模型中重现训练数据,也有人无意中将机密信息泄露给大模型。
我该如何部署自己的大语言模型?
大语言模型领域是一个变化极其快速且积极进步的领域。目前,我们关注的是一组特定的技术堆栈,它结合了多种技术:

我们也观察到一种对于跨越单个机器进行训练的抵触。这种抵触的部分原因是多机训练被认为是复杂的。好消息是,这正是Ray的优势所在,它使用Python和Ray装饰器简化了跨机器协调和编排方面的问题,同时也是组合整个技术栈的绝佳框架。
最近Dolly和Vicuna这两个基于Ray训练出的模型也表明:规模相对较小的大语言模型,只要基于正确的数据进行微调,也可以是很强大的。关键点就是如何进行微调和获取正确的数据。因此,你不一定总是需要使用超过1500亿参数+的最新、最大的模型来取得有用的结果。
用Ray部署一个已有模型来进行文本生成
详细的使用Ray部署GPT-J模型的步骤可以通过这个链接访问 https://docs.ray.io/en/master/ray-air/examples/gptj_serving.html,接下来我们会强调其中一些方面。
@serve.deployment(ray_actor_options={"num_gpus":1})
classPredictDeployment:
def__init__(self, model_id:str, revision:str=None):
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
self.model = AutoModelForCausalLM.from_pretrained(
"EleutherAI/gpt-j-6B",
revision=revision,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto", # automatically makes use of all GPUs available to the Actor
)
在Ray中进行服务部署是在actor中实现的,在这个例子中,使用的是一个叫PredictDeployment的actor。这段代码展示了的在构造函数中从Hugging Face下载模型行为。为了在当前节点启动这个模型,我只需要运行以下代码:
deployment = PredictDeployment.bind(model_id=model_id, revision=revision)
serve.run(deployment)这会在当前机器的8000端口启动一个服务。接下来只要使用几行python代码就可以请求这个服务:
import requests
prompt = (
“Once upon a time, there was a horse. “
)
sample_input = {"text": prompt}
output = requests.post("http://localhost:8000/", json=[sample_input]).json()
print(output)显然,这会输出一段上面这段开头的续写,每次运行这段代码,输出都会略有不同:
"Once upon a time, there was a horse.
But this particular horse was too big to be put into a normal stall. Instead, the animal was moved into an indoor pasture, where it could take a few hours at a time out of the stall. The problem was that this pasture was so roomy that the horse would often get a little bored being stuck inside. The pasture also didn’t have a roof, and so it was a good place for snow to accumulate."
这确实是个有趣的故事方向,不过现在我们想要把它设计在中世纪,该如何做呢?
模型微调
现在我们已经展示了如何部署一个模型服务,如何对其进行微调以使模型的表达更具中世纪风格呢?或许我们可以用2500行莎士比亚的文本对其进行训练?
这就是DeepSpeed派上用场的地方。DeepSpeed是一系列用于训练和微调神经网络的优化算法。问题在于DeepSpeed没有一个编排层。在单个节点上这不是太大的问题,但如果您想使用多台机器,它通常需要使用一堆定制的ssh命令(译注:使用无鉴权的ssh)、或者复杂的密钥管理等等。
而编排正是Ray发挥作用的领域。Ray文档中的这个页面
https://docs.ray.io/en/master/rayair/examples/gptj_deepspeed_fine_tuning.html讨论了如何通过一些独特的技巧将模型微调得更像15世纪的样子。让我们来看看关键部分,首先,我们从Hugging Face加载数据:
from datasets import load_dataset
print("Loading tiny_shakespeare dataset")
current_dataset = load_dataset("tiny_shakespeare")跳过分词部分代码,下面这段代码是每个worker节点上运行的核心代码:
def trainer_init_per_worker(train_dataset, eval_dataset=None,**config):
# Use the actual number of CPUs assigned by Ray
model = GPTJForCausalLM.from_pretrained(model_name, use_cache=False)
model.resize_token_embeddings(len(tokenizer))
enable_progress_bar()
metric = evaluate.load("accuracy")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
data_collator=default_data_collator,
)
return trainer现在我们构建一个Ray AIR HuggingFaceTrainer来编排分布式运行和封装多个上面的训练循环:
trainer = HuggingFaceTrainer(
trainer_init_per_worker=trainer_init_per_worker,
trainer_init_config={
"batch_size":16, # per device
"epochs":1,
},
scaling_config=ScalingConfig(
num_workers=num_workers,
use_gpu=use_gpu,
resources_per_worker={"GPU":1,"CPU": cpus_per_worker},
),
datasets={"train": ray_datasets["train"],"evaluation": ray_datasets["validation"]},
preprocessor=Chain(splitter, tokenizer),
)
results = trainer.fit()尽管存在一些复杂度,但它并不比在单机上实现的代码复杂多少。
微调和性能
大模型领域一个最重要的话题就是成本的问题。在这个案例中,微调的成本是很小的(部分原因是因为我们只进行了一个周期的微调,根据问题使用1-10个微调周期,并且还有一部分原因是因为这个数据集不是很大)。但在不同配置的机器上运行测试表明,理解性能并不总是容易的。以下是在AWS上使用不同配置的机器进行的基准测试结果。
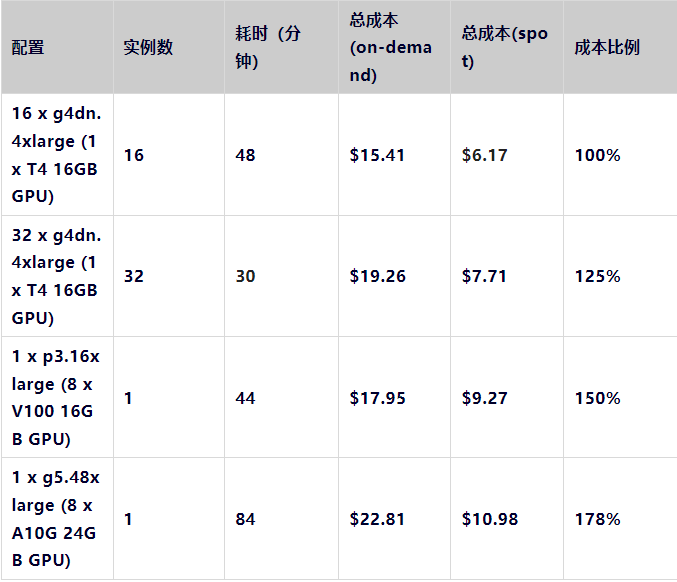
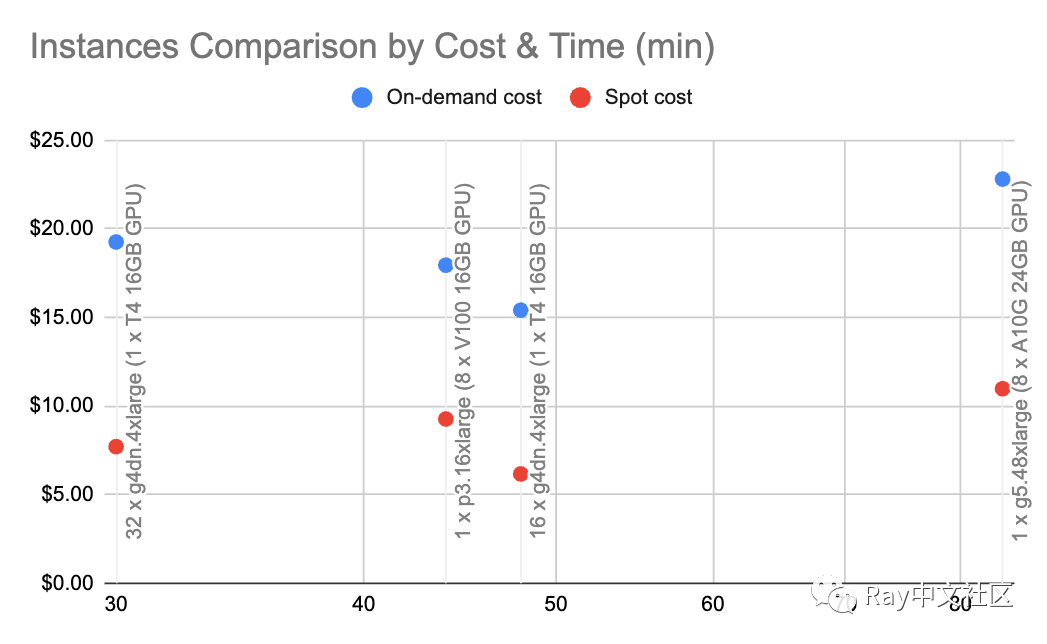
注:我们试图用A100来运行相同的测试,但我们无法取得p4d机器
观察这些数据,我们有了一些令人惊讶的发现:
显然,g5.48xlarge是纸面性能最高的机器,使用spot实例时的价格几乎是其他机器的两倍,但这种方案是最贵却也是最慢的。
具有NVLink的p3.16xlarge是一个更好的选择。
最令人惊讶的是,使用多台机器既是最便宜的,也是最快的选项。
所有的机器都运行了完全相同的代码,并且除了调整worker使用的GPU的数量之外,没有做其他任何更改。多台机器的方案为我们提供了基准测试中最便宜(16台机器)和最快(32台机器)的选项。
这就是Ray的美妙之处和强大之处。代码本身足够简单,实际上,开发者可以使用标准库DeepSpeed而无需进行任何修改。因此,在这种情况下,使用Ray的代码和单机代码一样简单。同时,它提供了更多的选择和灵活性,这使得优化后的结果可以比使用单机成本更低,速度也更快。
形成闭环:部署微调后的模型服务
现在,我们有了一个经过微调的模型,让我们尝试用它提供服务。我们需要进行的唯一更改是:一、从微调过程中将模型复制到S3;二、从S3中加载它。换句话说,与我们最初开始的上一段代码相比,唯一的改变是:
checkpoint = Checkpoint.from_uri(
"s3://demo-pretrained-model/gpt-j-6b-shakespeare"
)
with checkpoint.as_directory() as dir:
self.model = AutoModelForCausalLM.from_pretrained(
dir,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto")
self.tokenizer = AutoTokenizer.from_pretrained(dir)现在让我们试试再调用一次服务:
"Once upon a time there was a horse. This horse was in my youth, a little unruly, but yet the best of all. I have, sir; I know every horse in the field, and the best that I have known is the dead. And now I thank the gods, and take my leave."
可以看到,输出结果有了更多莎士比亚的韵味。
结论
我们展示了一个结合了Ray、HuggingFace, DeepSpeed和Pytorch的技术栈来实现一个系统,这个系统可以:
简单且迅速部署一个大模型服务;
被用于高效地微调大模型,并且能使用多节点获得最高性价比而不带来额外的复杂度;
通过仅仅是一个周期的微调对与训练模型的输出带来改变;
部署一个微调过的模型仅仅比部署一个标准模型困难些许。
编辑:于腾凯
校对:刘光栋














 2361
2361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









