






 本文介绍了一种新的持续学习方法PRD,通过联合表示学习和类原型更新,无需存储先前任务数据。实验显示PRD在任务增量和类增量设置中表现出色,且在限制数据访问的场景中优于依赖回放缓冲区的方法。
本文介绍了一种新的持续学习方法PRD,通过联合表示学习和类原型更新,无需存储先前任务数据。实验显示PRD在任务增量和类增量设置中表现出色,且在限制数据访问的场景中优于依赖回放缓冲区的方法。

来源:深度学习与计算机视觉
本文约2100字,建议阅读5分钟
本文提出了一种新的CL方法,PRD,它在训练或推理过程中不依赖于先前的数据存储。论文链接:
https://proceedings.mlr.press/v202/asadi23a.html
代码:暂未开源
引用:
Asadi N, Davari M R, Mudur S, et al. Prototype-sample relation distillation: towards replay-free continual learning[C]//International Conference on Machine Learning. PMLR, 2023: 1093-1106.


导读
持续学习的一个核心挑战是稳定性-可塑性困境。最近表现最佳的方法之一是利用各种形式的先前任务数据,比如回放缓冲区(replay buffer),以应对灾难性遗忘问题。然而,在许多实际场景中,访问先前任务数据可能受到限制,例如当任务数据是敏感或专有时。为了克服不使用先前任务数据的必要性,在这项工作中,我们采用了表现较不容易遗忘的强表示学习方法。我们提出了一种综合的方法,通过联合学习表示和类原型,同时保持旧类别原型及其嵌入相似性的相关性。
具体而言,样本被映射到一个嵌入空间,其中使用监督对比损失(supervised contrastive loss)学习表示。类原型在相同的潜在空间中不断演化,使得学习和预测可以在任何时刻进行。为了在不保留任何先前任务数据的情况下持续适应原型,我们提出了一种新颖的蒸馏损失(distillation loss),该损失约束类原型保持相对于新任务数据的相似性。这种方法在任务增量设置下取得了最先进的性能,在不使用大量数据的情况下胜过依赖存储数据点的方法,并在类增量设置中提供了强大的性能。
本文贡献
我们提出了一种新的CL方法,PRD,它在训练或推理过程中不依赖于先前的数据存储。
在各种具有挑战性的设置中,包括任务增量和类增量、使用不同数据集(如SplitMiniImagenet,SplitCIFAR100,Imagenet-32)以及任务序列长度(20到200),我们展示了PRD相对于基于回放和无回放方法的显著改进。
在几个实验中,我们证明了我们的方法不仅在控制先前观察到的任务遗忘方面具有强大的效果,而且还提高了学习新任务的可塑性。
本文方法
我们考虑了一种通用的持续学习情境,其中学习者面对可能永无止境的数据流,这些数据被划分为不同的训练会话。在每个会话 St 中,从分布 Dt 中抽取一组数据 Xt 及其对应的标签 Yt,该分布由 P(X, Y|T = t) 所特征化。在学习新会话时,假设对先前会话的样本的访问受到限制。这个定义包括任务增量设置,其中(Xt,Yt)表示一个独立的任务,类增量情景,其中P(X)的变化引发P(Y)的变化,以及域增量学习,其中P(X)的变化不影响P(Y)。
我们考虑了一个神经网络,由一个编码器 f 和一个投影头 g 组成。编码器将输入样本 x 映射到其特征表示 f(x) ∈ R^d,而投影头将特征投影到另一个潜在空间

,其中k < d。
我们的目标是在新的会话数据上最小化目标损失 Lt,同时不增加先前学习会话的目标损失

。为了控制先前遇到的会话损失,通常的方法是使用一个存储样本的缓冲区,并在遇到新的会话时重新使用它们。然而,在这种方法中,不需要访问过去的数据,而是通过一组原型来近似先前观察到的对象类别的行为。在访问新的会话时,通过一种新颖的蒸馏项,使用这个项来近似先前会话的不可访问损失,并设置以限制这个代理损失,从而控制先前观察到的会话的损失。
PROTOTYPE 原型
文中所提到的prototype 是指一个线性层。对于N个类,我们设置了N个prototypes,每个prototype由一个线性层构成,prototype接受一个sample作为输入,得到该sample的线性输出向量,称之为score,在之后的Objective function中作条件和constraints。

监督对比学习
监督对比学习是一种强大的表示学习方法,已被观察到在许多下游任务中非常有用。在之前的研究中,如(Khosla et al., 2020)和(Davari et al., 2022),监督对比训练被应用于持续学习,并且相对于使用交叉熵损失(CE)学习的表示,显示出学到的表示对遗忘较为鲁棒。在这项工作中,我们基于对监督对比学习的观察,提出了一种方案,以增量方式共同训练表示和分类头。为了优化用于学习的任务的表示,我们在输入数据上应用了一个监督对比损失。
论文中使用的监督对比损失的公式如下:
总体损失函数:

每个样本的损失:

值得注意的是,这个损失由正对之间的紧密性项和与负对之间的对比项组成。
没有对比的原型学习
为了将通过优化LSC(X)学到的判别性表示与最终的类别级别预测连接起来,我们考虑类原型的概念,它允许我们针对每个类别对样本的表示进行评分。一种简单的学习类原型的解决方案是将Softmax与交叉熵损失相结合,对于给定的样本,产生的损失为:
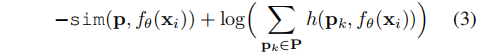
然而,研究已经表明,在类增量设置中,Softmax结合交叉熵会导致对先前学习的类别的干扰,因为其中的项会抑制先前类别的logits。为了解决这个问题,我们提出了一种学习类原型的方法,仅考虑该损失中的第一项,即“紧密度”项(“tightness”),而不包括抑制先前类别原型的对比项。我们提出的损失函数为:
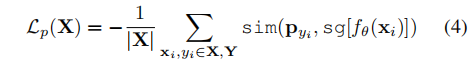
该损失仅包含一个紧密度项,即不包括对比项,这不会直接影响先前类别的原型。该损失的目标是仅优化原型而不改变样本的表示,因为样本表示的改变已经由之前的LSC(X)损失照顾。一旦得到了原型,可以直接在测试时通过使用样本表示与原型集的相似性来决定最近的类原型,从而进行预测。
相似性蒸馏更新原型
由于使用监督对比损失更新特征提取器(Equation (1)),以前任务类别的原型可能会过时,导致先前学到的类别被遗忘。为了在更新表示时更新旧原型,我们提出使用新类别数据作为旧数据的代理进行相似性蒸馏。在新的训练会话开始之前,计算原型与每个新类别样本的相似性。在新的训练会话期间,通过最小化原型与小批量样本之间的相似性分布的KL散度,强制使当前相似性类似于先前相似性。
对于输入的小批量X和相应的原型,可以考虑Softmax输出

,其中第 i 个条目为:

使用KL散度构建相似性蒸馏损失,表示为:
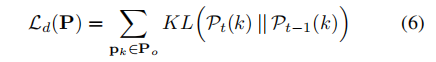
综合三个损失项,得到整体的训练目标:
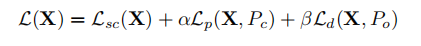
实验
实验结果
任务增量结果:
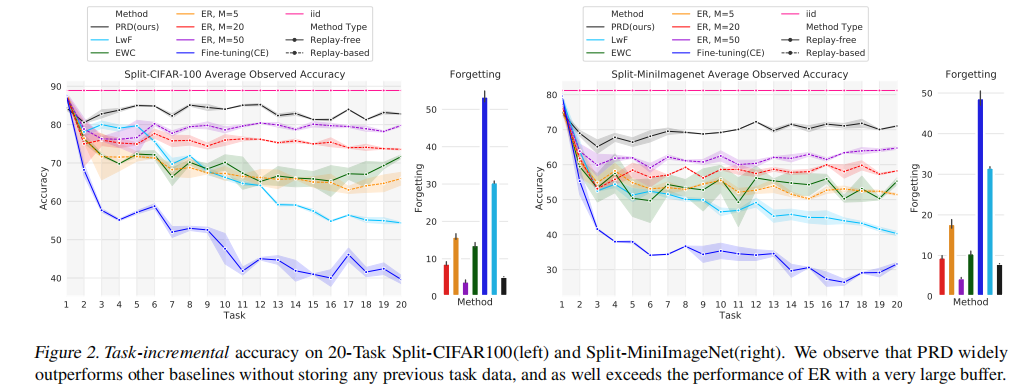

类增量结果:
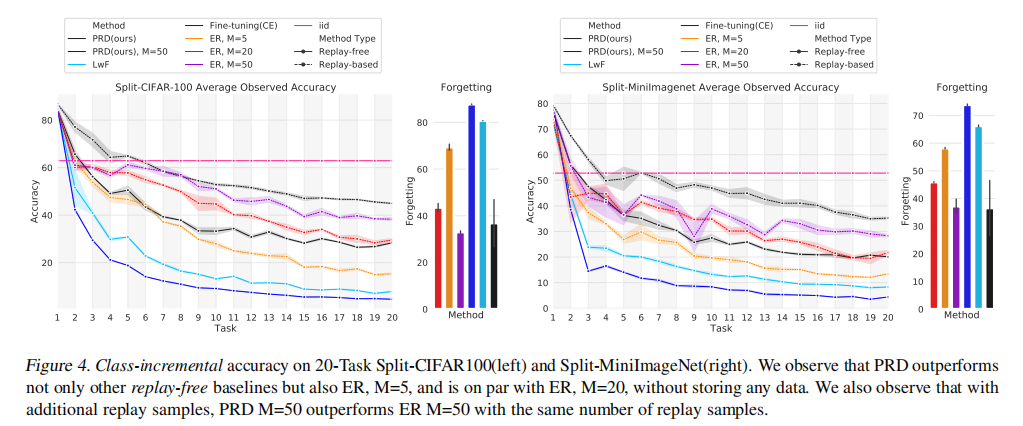
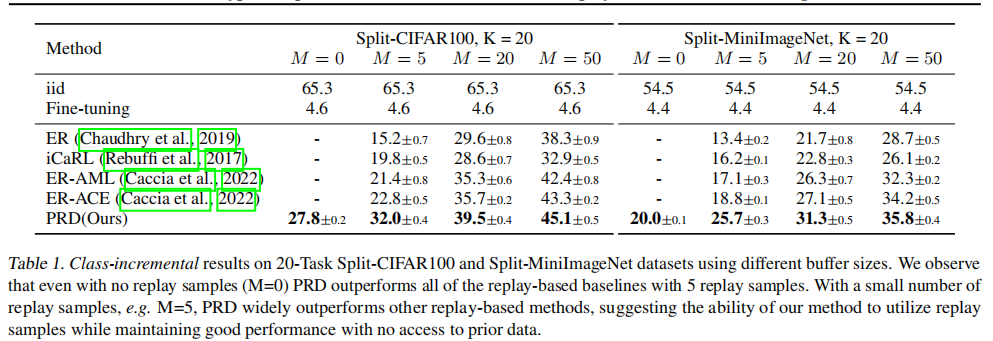
消融实验

编辑:于腾凯
校对:林亦霖
















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









