







来源:PaperWeekly
本文约2300字,建议阅读9分钟我们希望它可以为未来长视频的表征学习指明道路。一、介绍
我们提出了一个仅基于状态空间模型 (SSM) 的高效视频理解架构 VideoMamba,并通过大量的实验证明了它具备一系列良好的特性,包括 1)Visual Domain Scalability;2)Short-term Action Sensitivity;3)Long-term Video Superiority;4)Modality Compatibility。这使得 VideoMamba 在一系列视频 benchmark 上取得不俗的结果,尤其是长视频 benchmark,为未来更全面的视频理解提供了更高效的方案。

论文标题:
VideoMamba: State Space Model for Efficient Video Understanding
论文链接:
https://arxiv.org/abs/2403.06977
代码链接:
https://github.com/OpenGVLab/VideoMamba
模型链接:
https://huggingface.co/OpenGVLab/VideoMamba
Online Demo:
https://huggingface.co/spaces/OpenGVLab/VideoMamba
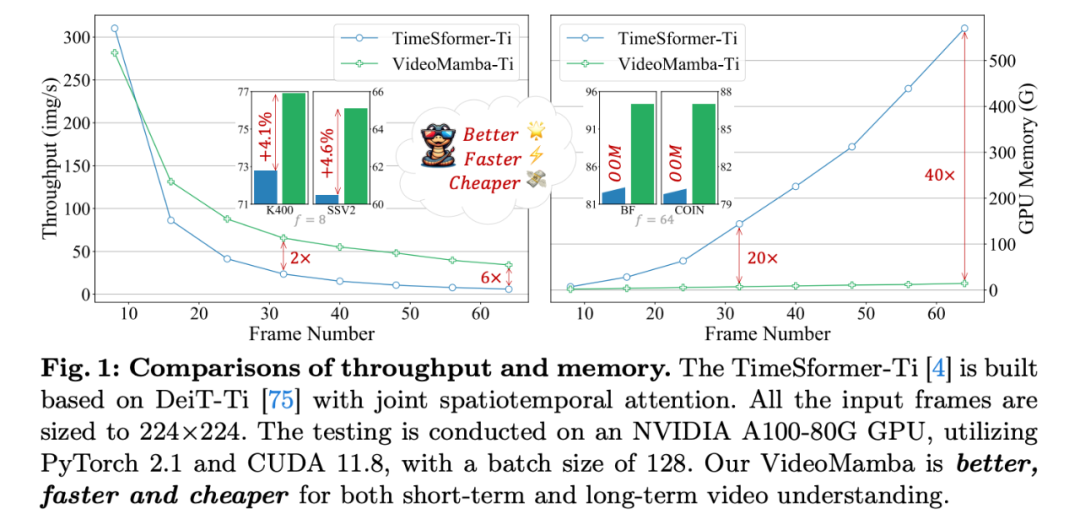
二、Motivation
视频表征学习长期以来存在两大痛点,一是短 clip 里存在大量的时空冗余,二是长上下本需要复杂的时空关联。曾经风靡一时的 3D CNN 和 video transformer,分别使用卷积和自注意力机制解决了两大难题。在我们之前的工作 UniFormer [1] 里,我们尝试将卷积和自注意力无缝地结合,尽管它能同时解决两大难题,但对于长视频仍力不从心。而 Gemini [2] 和 Sora [3] 的爆火,使得长视频理解与生成成为了研究的重心,这亟需更高效的视频表征模型。
幸运的是,NLP 领域这两年涌现了不少高效算子,如 S4 [4], RWKV [5] 和 RetNet [6]。而 Mamba [7] 提出动态状态空间模型 (S6),能以线性复杂度进行长时的动态建模。这引领了一系列视觉任务的适配,如 Vision Mamba [8] 和 VMamba [9],提出了多向 SSM 机制用于处理 2D 图片,这些模型不仅能与基于注意力的架构媲美,而且大大减小显存开销。
考虑到视频产生的超长 token 序列,一个自然而然的问题便是,Mamba 对视频理解是否同样有效?答案是肯定的。
三、Method - Architecture
在进入 VideoMamba 结构的介绍之前,我们先看看用于 1D 序列的 Mamba block,和用于视觉任务的双向 Mamba block。这里我们不再赘述 SSM 和 Mamba 的底层原理,感兴趣的同学可以通过油管视频学习:
https://www.youtube.com/watch?v=8Q_tqwpTpVU
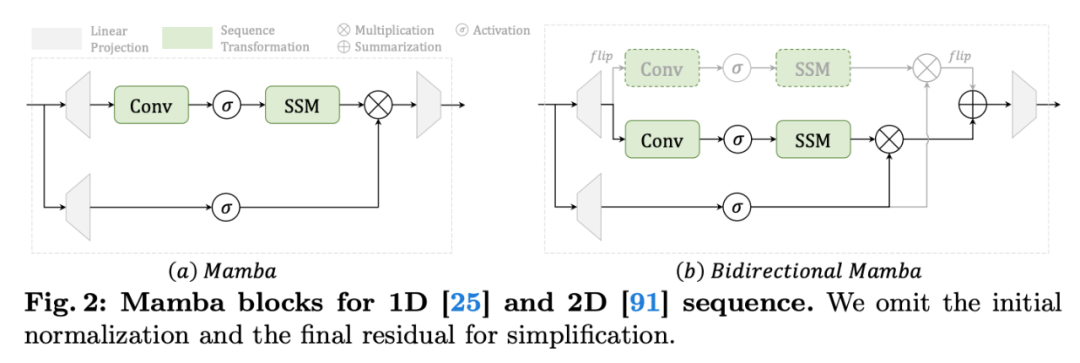
双向 Mamba 在单向 Mamba 的基础上,引入了对反向序列的 SSM,这使得双向 Mamba 能更好地对 2D 序列建模,从而提升对视觉输入的感知能力。基于双向 Mamba,我们按照 ViT [10] 的设计,引入 [CLS] token 和空间位置编码,并针对视频建模,引入 3D patch embedding 和空间位置编码,提出了如下所示的 VideoMamba:
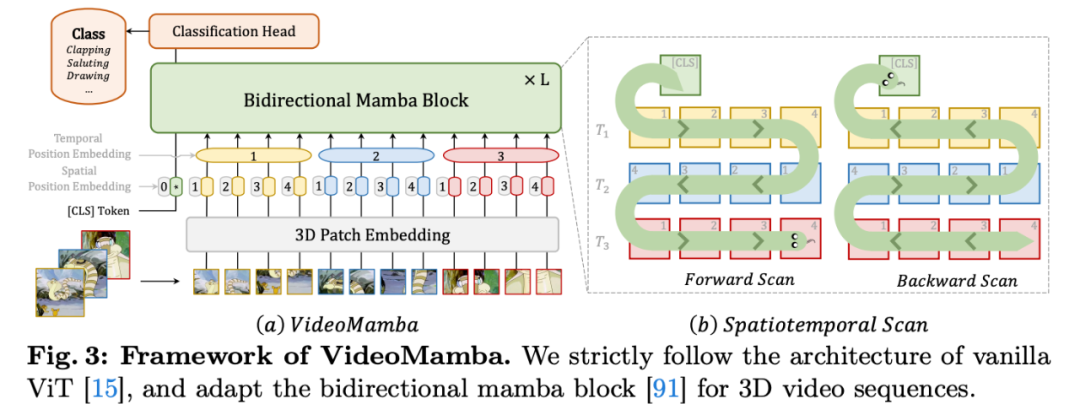
为了应用双向 Mamba 处理时空信息,我们拓展原本的 2D 扫描到不同的双向 3D 扫描:
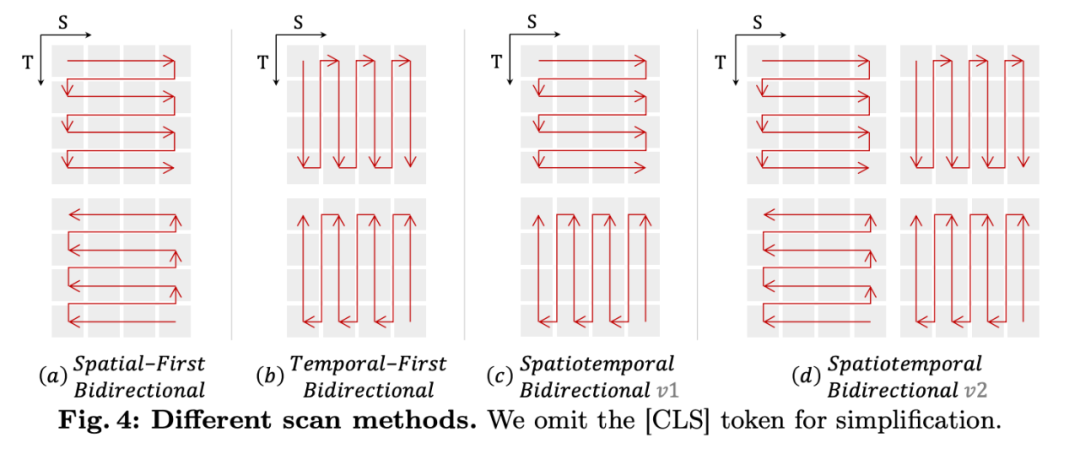
其中空间优先扫描最简单,实验证明效果也最好。基于该架构,我们提出了三种不同 size 的模型,VideoMamba-Ti,VideoMamba-S 和 VideoMamba-M。
但在实验里,当我们增大 VideoMamba 规模时,非常容易过拟合,导致大模型的结果甚至差于小模型。为此,我们提出了 Self-Distillation 策略,使用训练好的小模型当老师,引导大模型训练,有效地避免模型过拟合,而只需少量额外的开销。
掩码建模
近来,VideoMAE [11] 引入掩码建模,显著增强了模型对细粒度时序的理解能力,而 UMT [12] 进一步提出高效的掩码对齐策略,不仅大大减小了训练开销,还使得模型能鲁棒地处理各种单模态和多模态任务。为了增强 VideoMamba 对时序的敏感性,同时验证它和文本模态的兼容性,我们借鉴 UMT 的方式,引入 CLIP-ViT 当 teacher,进行两阶段蒸馏训练。
不同于 UMT 使用多层对齐,由于 VideoMamba 和 ViT 存在架构差异,我们只对齐模型最后一层,考虑到 Mamba block 对连续 token 更友好,我们设计了逐行掩码策略:
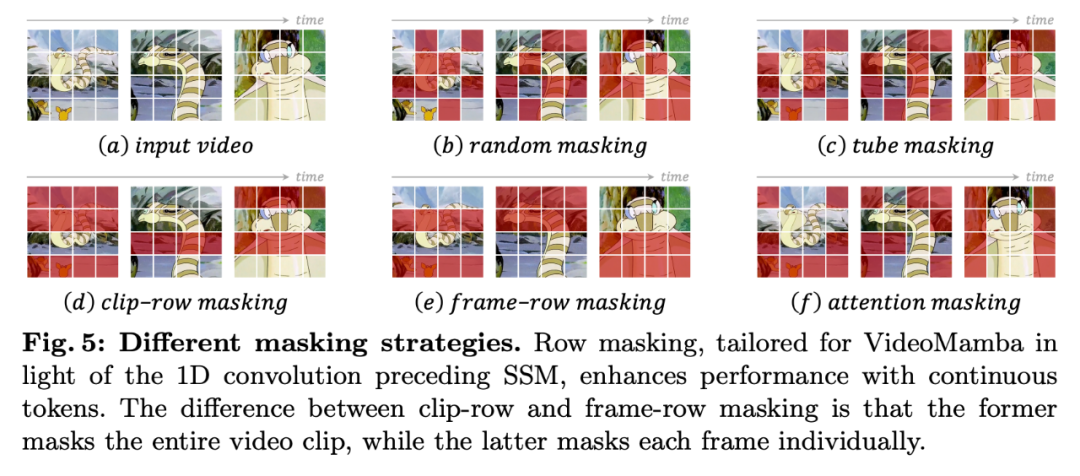
同时我们也考虑了注意力掩码策略,这能保持语义性更强的邻近 token。
四、Experiments - Scale Up
我们首先在 ImageNet 上进行了图像分类实验如下所示:
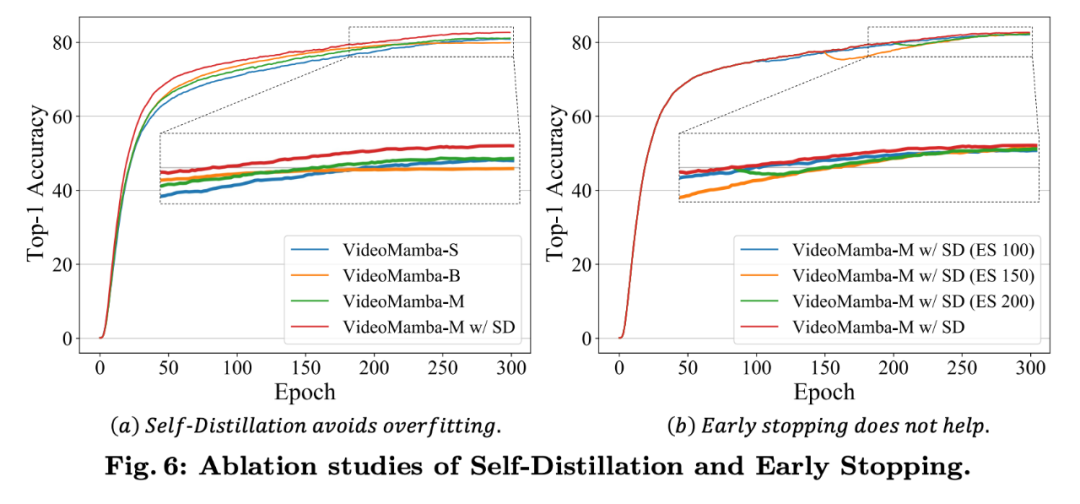
可见在没有 Self-Distillation (SD) 时,VideoMamba-M 和 VideoMamba-B 都会在训练的最后过拟合,其中 VideoMamba-B 尤为严重。而在引入 SD 后,VideoMamba-M 收敛符合期望,且明显强于老师模型 VideoMamba-S。为了避免老师模型带偏训练,我们引入了 Early Stop 策略,即提前移除蒸馏引导,实验发现并无提升。完整 ImageNet 对比如下:
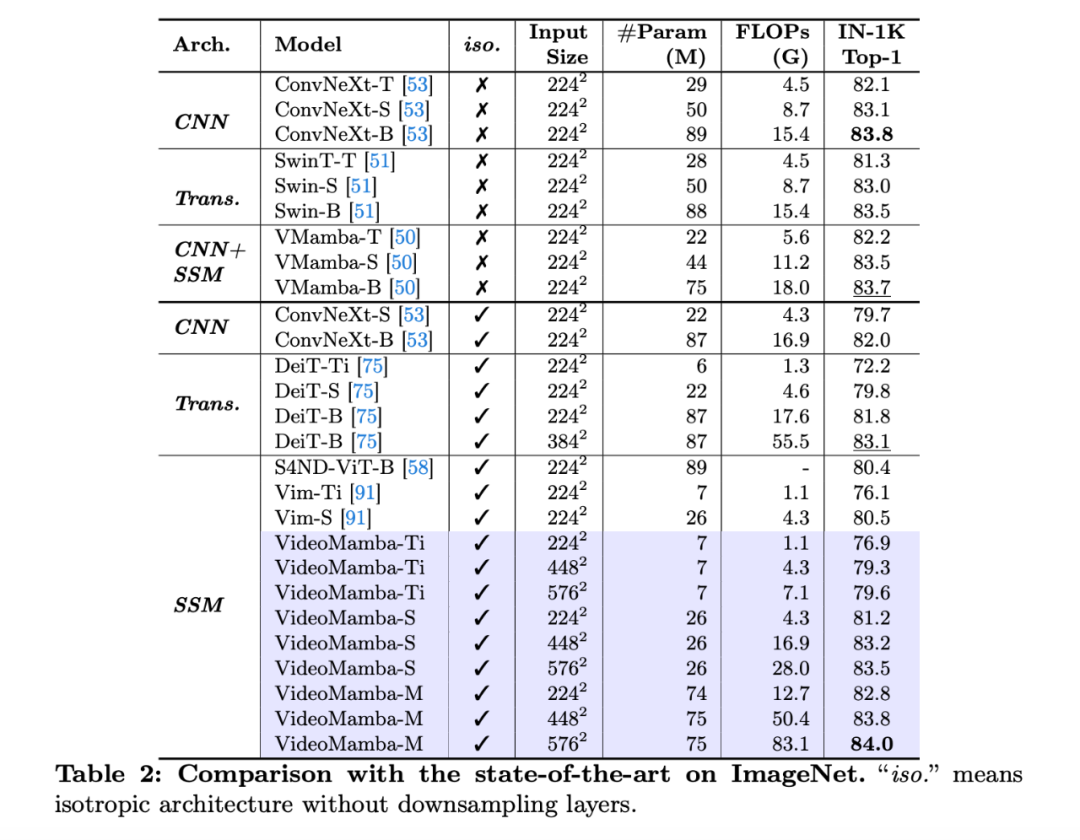
和无层次化结构的其他模型相比,VideoMamba 优于其他 CNN 和 ViT 的模型,如 ConvNeXt 和 ViT。随着模型规模和分辨率放大,性能稳定提升。
Short-term Video Understanding
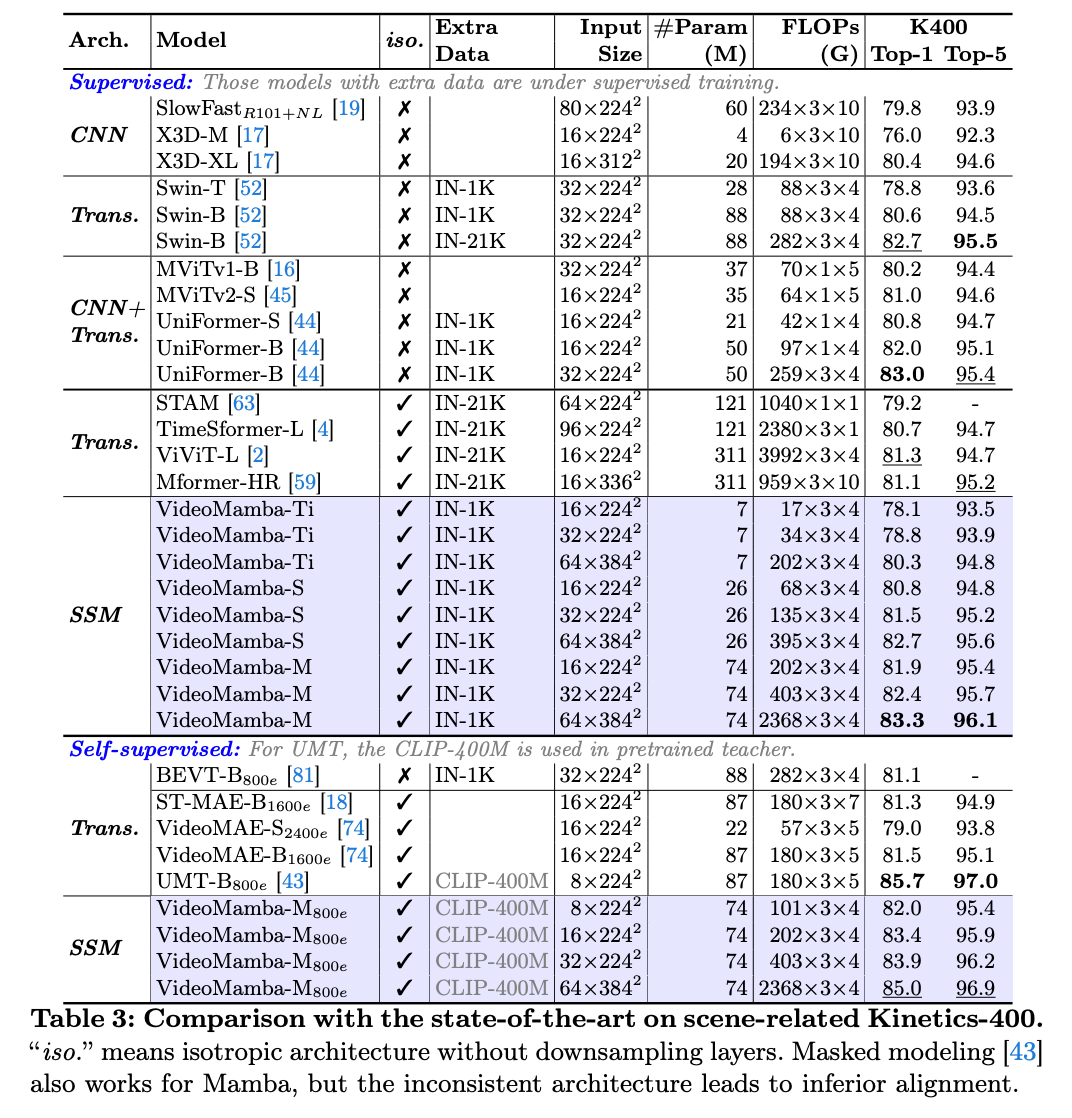
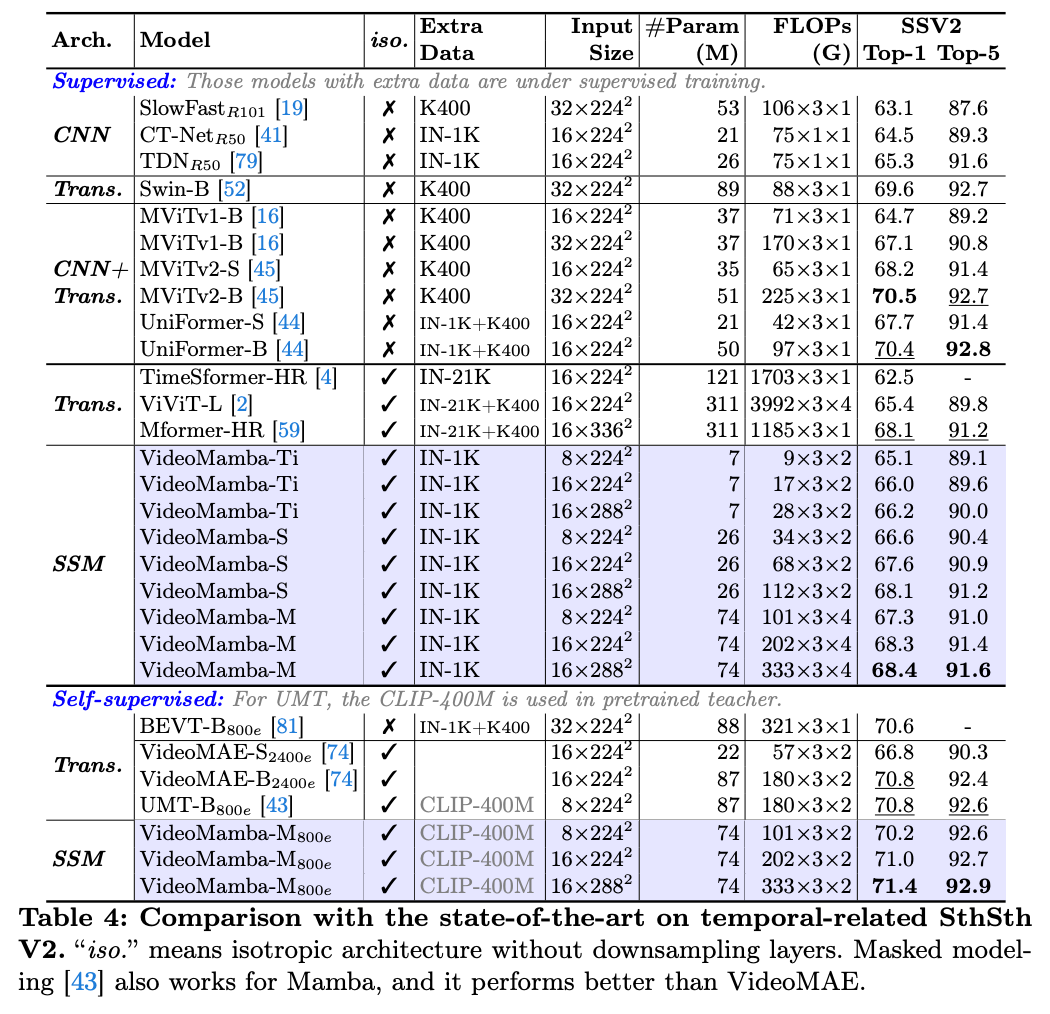
在上述 K400 和 SthSthV2 的短视频分类任务中,我们同样观察到 VideoMamba 良好的放缩性,且显著优于基于注意力的视频模型如 TimeSformer 和 ViViT,与结合卷积和自注意力的 UniFormer 性能相当。再者,在引入掩码训练后,VideoMamba 性能显著提升,在细粒度动作分类 SthSthV2 数据集上,显著好于基于 ViT 的 UMT。
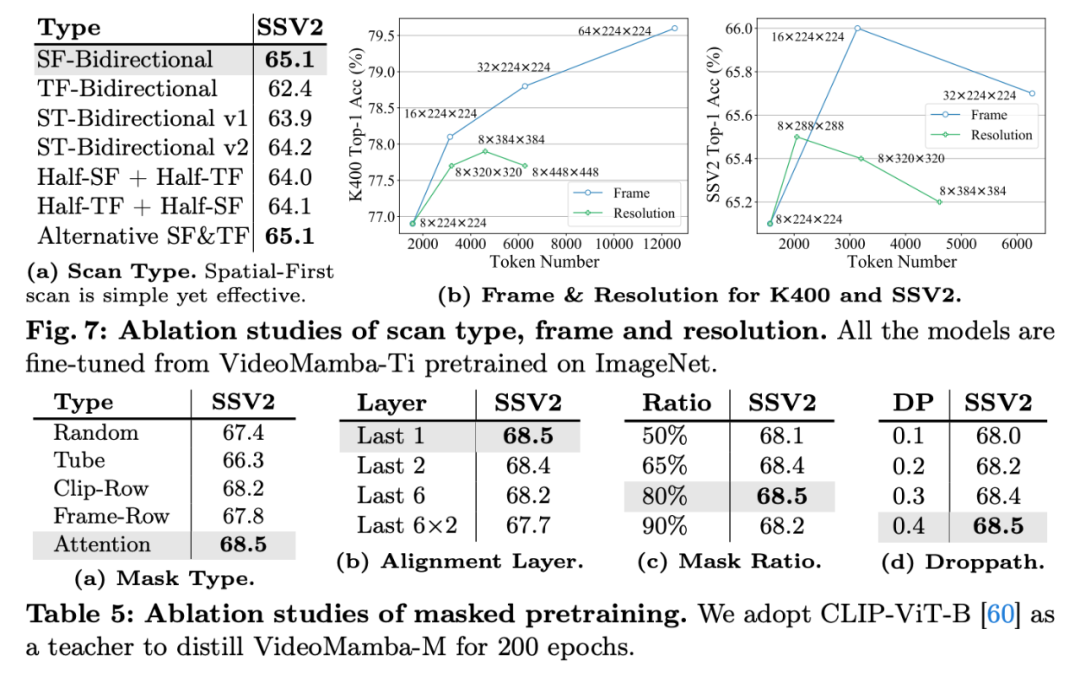
进一步的消融实验表明,spatial-first 扫描方案效果最好。不同于 ImageNet 上性能随分辨率逐渐提升,视频数据集上分辨率对性能影响有限,而帧数对性能影响明显。对于掩码建模,逐行掩码优于随机掩码策略,且注意力掩码策略最有效;对齐最后一层效果最好;合适的掩码比例和 Droppath 能较好提升训练效果。
Long-term Video Understanding
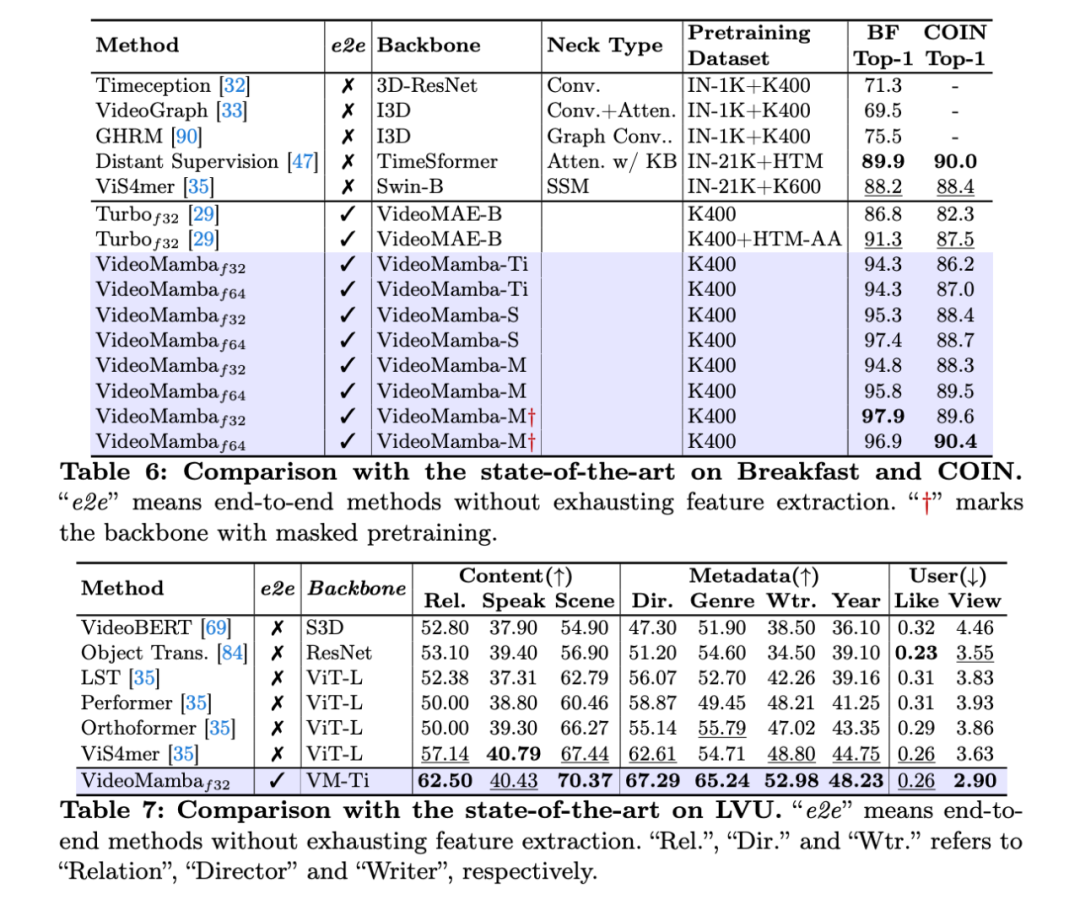
我们在 Breakfast,COIN 和 LVU 上评估了 VideoMamba 对长时视频的理解能力,相较于以往 feature-based 的方法,VideoMamba 仅需要输入稀疏采样的 32-64 帧,效果便大幅领先,且模型规模更小。
Multi-modality Video Understanding
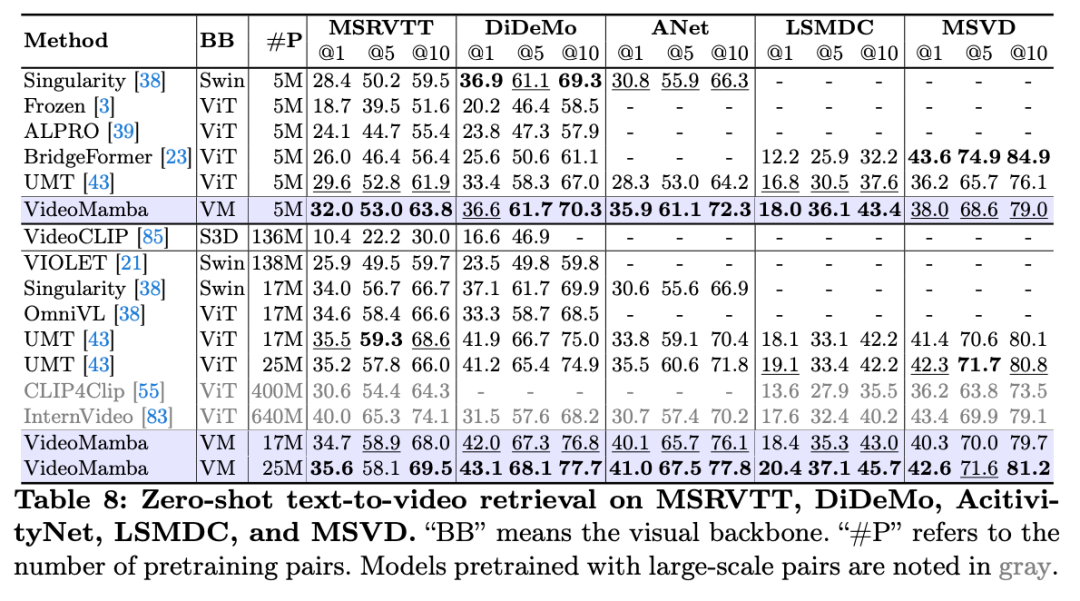
我们将 VideoMamba 和 BERT 连接,构造多模态模型,并使用大规模多模态数据进行预训练,在多个视频文本检索任务上进行了性能评估。实验揭示 VideoMamba 同样能很好地作为多模态的视觉编码器,随着预训练数据的增加,能持续提升多模态理解的能力,且由于以 ViT 为视觉编码器的 UMT,尤其是在包含长视频(ANet 和 DiDeMo)和更复杂场景(LSMDC)的数据集上。
五、Conclusion
我们提出了仅基于状态空间模型的视频理解架构 VideoMamba,全面的实验表明 VideoMamba 对视频理解具有一系列良好特性,我们希望它可以为未来长视频的表征学习指明道路。
参考文献
[1] UniFormer https://github.com/Sense-X/UniFormer
[2] Gemini https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/
[3] Sora https://openai.com/sora
[4] S4 https://github.com/state-spaces/s4
[5] RWKV https://www.rwkv.com/
[6] RetNet https://github.com/microsoft/unilm/tree/master/retnet
[7] Mamba https://github.com/state-spaces/mamba
[8] Vim https://github.com/hustvl/Vim
[9] VMamba https://github.com/MzeroMiko/VMamba
[10] ViT https://github.com/google-research/vision_transformer
[11] VideoMAE https://github.com/MCG-NJU/VideoMAE
[12] UMT https://github.com/OpenGVLab/unmasked_teacher
编辑:黄继彦
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









