







作者:贾恩东
本文约2500字,建议阅读9分钟本文将介绍在异常检测领域中的一种具有线性时间复杂度和较高精准度且在学术界和工业界都有着不错反响的算法:孤立森林。异常检测是机器学习研究领域中和现实应用联系紧密,有广泛的直接需求的一大类问题。这一类问题的解决方案往往可以直接应用于网络安全中的攻击检测,金融交易欺诈检测,敌方活动的军事异常监测,罕见疾病侦测,和噪声数据过滤等实际业务,具有较为明显的商业价值。
背景介绍
我们先来简单了解一下孤立森林算法所属的机器学习分类领域,即异常检测。异常检测 (anomaly detection),或者又被称为“离群点检测” (outlier detection),指的是在数据中发现不符合预期行为模式的特别数据的问题。在不同的应用领域中,这些不一致模式的特别数据通常被称为异常、异常值、不一致观察、离群值、异常、畸变、意外、特殊性或污染物。但对于“异常”的具体定义,在不同的问题上往往其实并没有标准答案,甚至在同一个问题上,在不同的角度下,所谓何为“异常”的答案可能也不尽然相同。事实上,正常和异常之间的界限往往是不清晰的。在靠近边界处,正常观测常被错分类为异常观测,而异常观测又容易被分类为正常的。而不同场景下的异常定义不同:举例来说,医学领域的微小偏差(如体温波动)可能是异常,而在股市领域的类似偏差(如股票价值波动)可能被视为正常。
异常检测领域存在的另一个困难是数据集往往缺乏标签,很多场景下没有异常数据的标签,无法使用监督学习;即使使用人工打标创建标签,通常情况下负样本(异常样本)是极少的,属于样本不平衡问题。
孤立森林的前提假设
孤立森林对于异常数据的分布有一个非同寻常的前提假设,整个算法也是由这个假设自然推出的。
孤立森林认为:异常数据的样本数量少且在被隔离时需要较少的步骤数。
用一个通俗的例子来说明隔离样本这个过程。我们用西瓜来类比我们的全样本空间。而我们的数据集,则是分布在这个全样本空间内的西瓜籽。这些西瓜籽绝大多数是成熟的(正常样本),少数是未成熟的(异常样本)。隔离样本意味着我们需要用刀将该西瓜切成若干块,每一个仅包含一个西瓜籽。对于某西瓜籽来说,隔离它所需的切割次数即为所谓的“被隔离时需要的步骤数”。
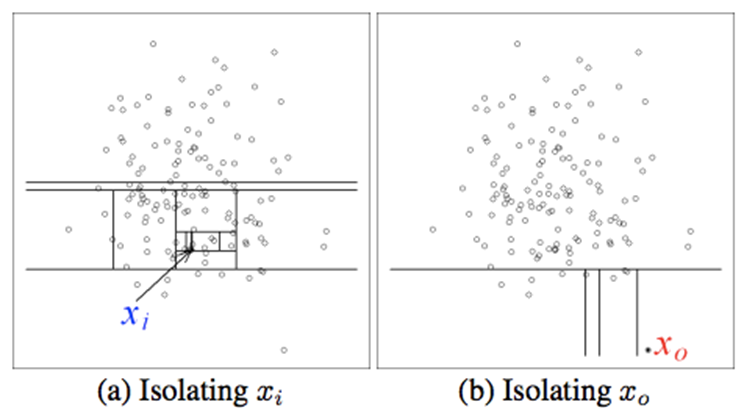
如下图,在这个样本空间中,异常点位于两个正常簇的外围。对于这些处于外围的异常样本,由于其附近很稀疏,所以需要较少的分割步骤即可“脱颖而出”。所以,孤立森林的前提假设,本质上是暗示:正常样本分布空间,正常样本的密度很高,所以需要较高的分割步骤,而异常样本,不仅数量较少,而且处于一种分散的状态,所以需要较少的分割步骤。
孤立森林算法
如上节所说,孤立森林是基于对数据分割这个过程来实现的。如下图,对于正常样本和异常样本,其分离难易程度是不同的。那么接下来我们需要一种更具体的方法来量化这个难易程度。
孤立森林,顾名思义,是多个孤立树的集合。我们先介绍一颗孤立树的训练步骤。
1. 从训练数据中随机选择 N个点作为子样本集合U作为该孤立树的训练集
2. 随机指定一个特征F,在该特征区间上随机产生一个切割点c
3. 切割点将该子样本集合U切割成了2个部分,即特征F大于c和不大于c的两部分样本空间,
4. 对于3中的两部分样本空间,重复进行2,3步骤,进行递归
5. 直到所分割后的样本集合内样本个数为1时停止分割
该过程就是一个树的分裂过程。拿一个特征维度为2,样本数为8的数据集举例,其一个随机的孤立树分割过程可能如下:
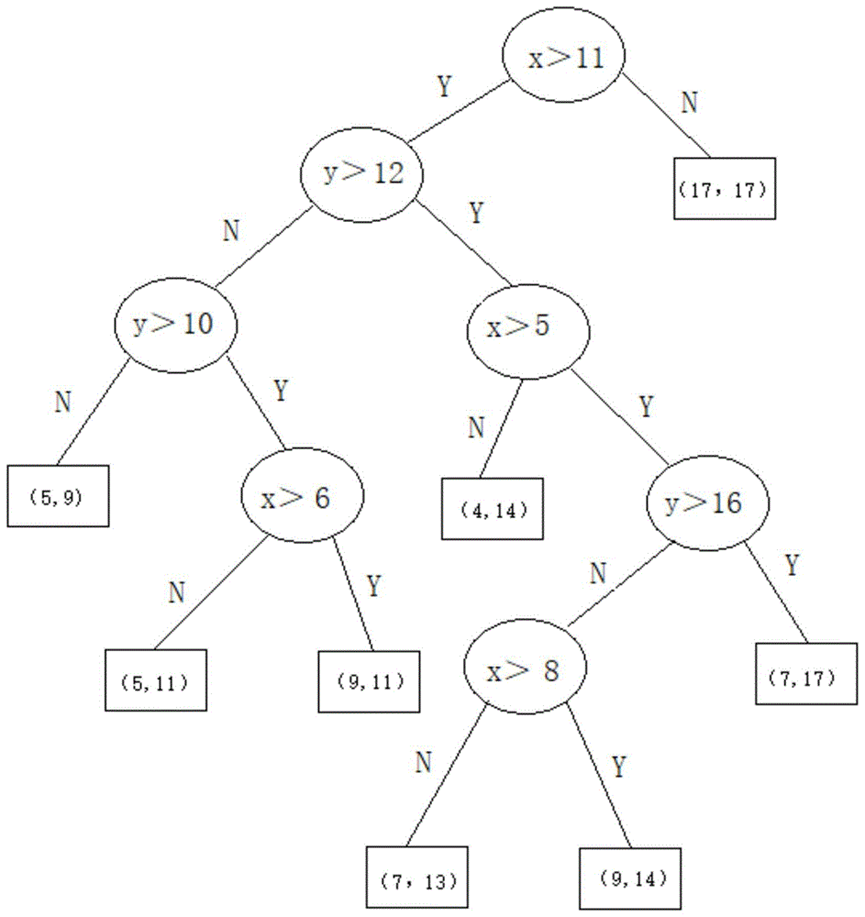
由于切割过程是完全随机的,所以需要用多次切割求平均 的方法来使结果收敛,即反复从头开始切,然后计算每次切分结果的平均值。

训练结束后,这些孤立树的切割方式就固定了(具体指的是每一个节点处的切割点c),接下来就可以用训练好的孤立森林来评估测试集。为了方便在不同的特征维数,树的最大深度下对比,我们把“切割次数”这个量进行归一化:

这里Depth是指样本的平均深度(分割次数),Height是指树的最大深度(高度)。可见,这个量化后的异常Score,是介于0.5-1之间的,越接近1,其分割次数越小,表明该样本越倾向为异常样本(轻易分离);越接近0.5,其分割次数越接近最大分割次数,表明该样本越倾向于正常样本(难以分离)。
孤立森林的优点
由于孤立森林每一次都是在一个子样本集合上做树的生成,而每一棵树的胜场都是互相独立的,因此孤立森林的优势就是计算量小、天生可以分布式训练和计算,非常适合海量数据的场景。
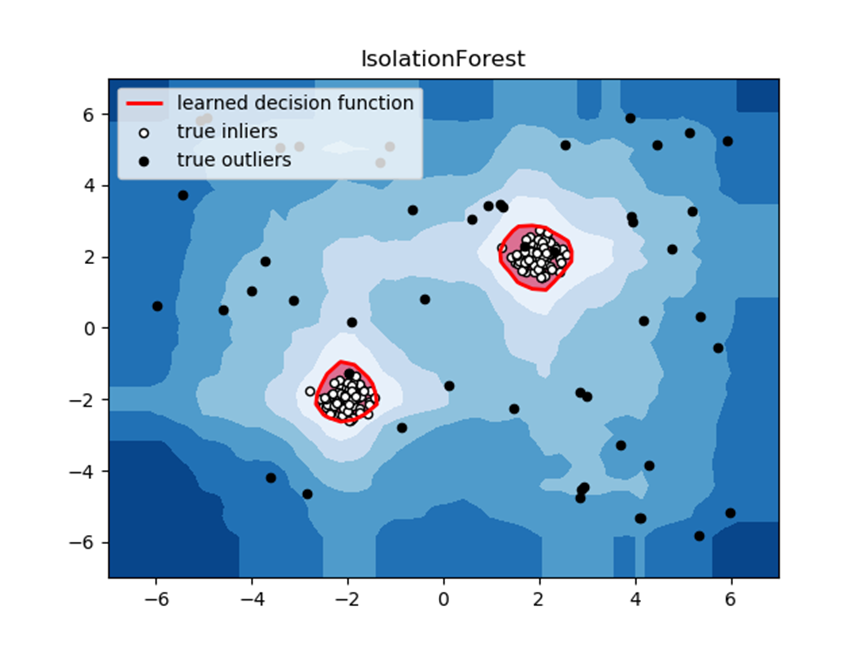
和异常检测领域中的其他几种常见的简单算法在几种不同的toy dataset下的对比效果如下图所示。读者可以自行对比这几种算法的特点。

孤立森林的局限
成也萧何,败也萧何。孤立森林虽然简单高效,但在使用孤立森林进行实际异常检测的过程中,暗含了很强的假设:1. 异常样本点是全局稀疏的 2. 异常样本点是总体偏少的
因此,当该假设不符合数据集的特点时,该算法的效果就要大打折扣。另一方面,孤立森林也不太适用于当特征维度过多的高维数据集。这是因为,当特征维度过多时,可能样本点的分离过程并不需要所有的特征维度都参与进来,也就是说,孤立森林对于高维数据集的利用并不完整。
编辑:黄继彦
欢迎留言,有机会与本文作者互动哦~
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU
点击“阅读原文”加入组织~















 4839
4839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









