




来源:多模态机器学习与大模型
本文约2300字,建议阅读5分钟
本文提出了链接上下文学习(LCL),强调“因果推理”来增强 MLLM 的学习能力。Link-Context Learning for Multimodal LLMs
作者:
Yan Tai, Weichen Fan, Zhao Zhang, Ziwei Liu
作者单位:
南洋理工大学 S-Lab,商汤科技,东方工学院宁波数字孪生研究所
论文链接:
https://arxiv.org/pdf/2308.07891
代码链接:
https://github.com/isekai-portal/Link-Context-Learning
简介
从上下文中学习新概念并提供适当响应的能力在人类对话中至关重要。尽管当前的多模态大语言模型(MLLM)和大语言模型(LLM)正在大规模数据集上进行训练,但以免训练的方式识别看不见的图像或理解新概念仍然是一个挑战。情境学习(ICL)探索免训练的小样本学习,鼓励模型从有限的任务中“学会学习”并泛化到未见过的任务。本文提出了链接上下文学习(LCL),强调“因果推理”来增强 MLLM 的学习能力。LCL 通过显式强化支持集和查询集之间的因果关系超越了传统的 ICL。通过提供因果关系的演示,LCL 引导模型不仅辨别类比,而且辨别数据点之间的潜在因果关联,这使 MLLM 能够识别看不见的图像并更有效地理解新概念。为了促进对这种方法的评估,文中引入了 ISEKAI 数据集,专门包含为链接上下文学习而设计的未见过的生成图像标签对。

图 1.链接上下文学习的演示对话。在向模型呈现一对看不见的图像和新颖的概念后,改进模型获得了在整个对话过程中学习和保留所获得知识的能力,而普通 MLLM 无法提供准确的答案。
研究动机
MLLM 从演示中学习的主要方法被称为上下文学习,其中模型在接触一些输入标签对后在下游任务上显示出显着的改进。然而,当前的 MLLM 从上下文学习中获得的好处非常有限,因为重点主要是引导模型在从元任务“学习”之后获得处理新任务的能力。然而,即使元任务中提供的答案全部错误,模型的性能也不会受到影响。因此,MLLM 从演示中“学到”的仍然是以特定格式回答问题,而不是理解图像-标签对之间的因果关系。
为了使 MLLM 能够更多地关注图像和标签对之间的因果关系,Frozen 方法将不同的标签绑定到已知图像。然而,当 MLLM 遇到图像和标签都看不见的全新场景时,就会出现重大挑战。在这种情况下,从演示中提取潜在的因果关系并根据新发现的知识做出准确的预测仍然是一个未解决的难题。
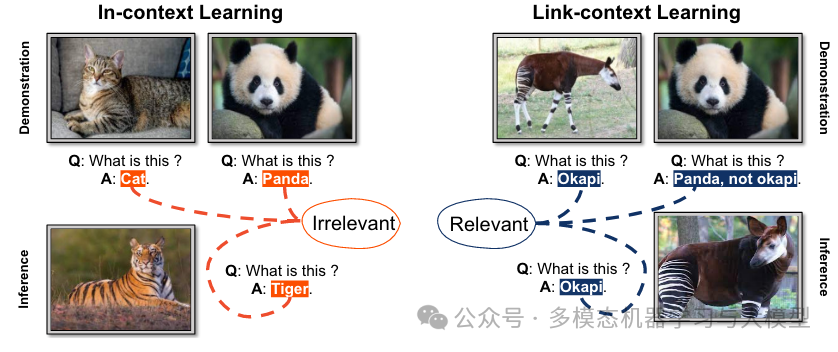 图 2.链接上下文学习与上下文学习之间的区别。上下文学习涉及为演示提供不相关的任务,而链接上下文学习的演示和推理阶段之间存在直接的因果关系。
图 2.链接上下文学习与上下文学习之间的区别。上下文学习涉及为演示提供不相关的任务,而链接上下文学习的演示和推理阶段之间存在直接的因果关系。
如图 2 所示,当前 MLLM 中的情境学习强调从因果无关的演示中受益。然而,对于链接上下文学习,演示和最终任务是因果关联的。(例如,如果在演示中将“苹果”重命名为“橙色”,则模型应在推理过程中将苹果称为“橙色”。)有了这种能力,MLLM 可以以灵活的方式支持小样本学习。
论文贡献
链接上下文学习:引入了一种新的因果相关的小样本学习设置,其中 MLLM 面临的挑战是从正在进行的对话中吸收新概念,并保留这些知识以准确回答问题。在链接上下文学习下,使 MLLM 能够从演示中掌握源和目标之间的因果关系。
ISEKAI 数据集:由于 MLLM 并非完全看不到大多数现实世界的数据,因此本文发布了一个具有挑战性的数据集,其中引入了新的图像概念对,用于评估 MLLM 的性能。
方法
文中提出链接上下文学习(LCL),赋予 MLLM 理解对话中潜在因果关系并处理看不见的图像和概念的能力。与 ICL 主要侧重于启发具有各种不同任务的模型不同,LCL 更进一步,通过授权模型在源和目标之间建立映射,从而提高其整体性能。
链接上下文学习的主要限制和区别
上下文学习是指:给定查询输入,模型应从一组候选答案 中选择预测得分最高的答案x,以支持集 S 为条件,该支持集由来自各种任务的多个输入标签对组成,其中 。(查询和S的样本应该属于不同的任务。)
。(查询和S的样本应该属于不同的任务。)
从另一个角度来看,上下文学习可以表示为免训练的少样本学习,因为它将少样本学习的训练阶段转变为演示输入对于大型语言模型。注意到 ICL与 FSL 一致,其中演示(训练)阶段和推理(查询)阶段的任务是不同的。
链接上下文学习(LCL)代表了一种免训练且因果链接的小样本学习的形式。在这种方法中,提供了支持集 S,以及来自查询集 Q 的查询样本 x,其中数据对来自支持集与查询集有因果关系。该模型的任务是根据查询和支持集之间的因果关系来预测答案。
将链接上下文学习引入 MLLM
提出了一种新的训练策略来微调 MLLM。这种方法旨在使模型能够有效地从上下文中掌握因果关系。这种新的训练策略使 MLLM 能够在需要推理和理解因果关系的任务中表现出色,从而扩大他们的能力范围并提高他们的整体表现。
训练数据集
ImageNet1k 通常用于图像分类任务,通常在整个数据集上训练模型以增强其跨所有类别的识别能力。相比之下,在 LCL 的训练配置中,文中仅从每个类别中随机选择有限数量的样本。然后,为每个类别排列一组相似度递减的相关类别,称为“邻居”。具体来说,采用 CLIP 来计算训练数据集中不同类之间的相似度。首先,从每个类别中随机选择 100 张图像,并计算每个类别的平均图像特征。随后,对所有类的文本名称进行编码以获得其对应的特征向量。最终,计算不同类对之间的加权相似度,包括图像到图像、图像到文本和文本到文本的相关性。对于特定类别,根据相似性对所有其他类别进行排序,并将它们划分为 N 个区间。然后,在每个区间内,随机选择类别来构造一组总数为 N 的“邻居”。
训练策略
为了使 MLLM 理解支持集和查询样本之间的因果关系,以及支持集中输入标签对之间的因果关系,文中构建正负对来促使模型从比较中学习。令支持集表示为 。根据样本之间的相关性,可以将支持集重新定义为 ,其中每个 作为代表 S 中样本簇的原型。这些原型捕获了本质关系以及 S 内样本之间的相似性。给定查询 x,训练 θ 来最大化可能性:
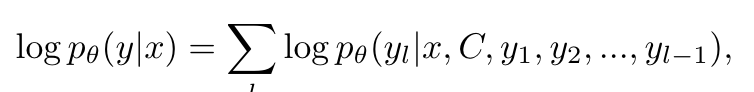
其中θ表示语言模型的参数。视觉编码器的参数在训练期间被冻结。
[2-way] 策略:训练 MLLM 进行二值图像分类,其中。训练类集表示为 ,随机采样一个类 作为正类,其中它的邻居类集 是与 最相似的类,而 是最不相似的)。然后应用硬负挖掘策略,以概率 从 中采样负类 。请注意,此设置固定为 16 个镜头进行训练。
实验结果
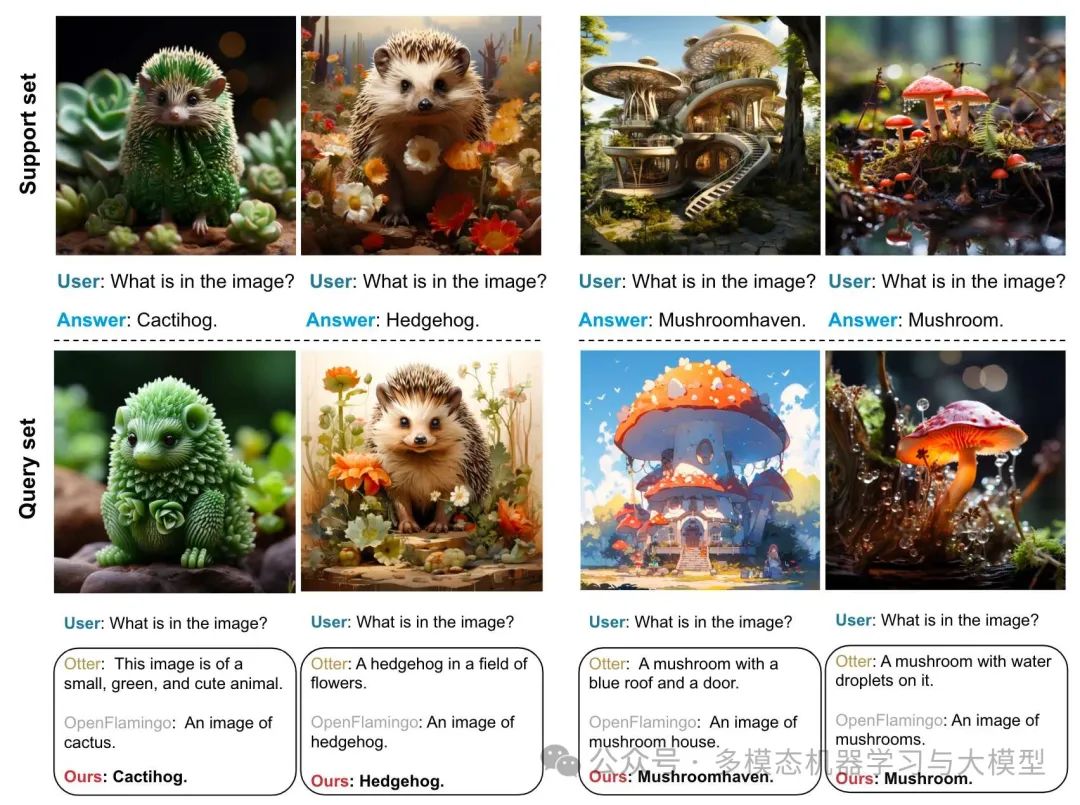
图 4. 与 OpenFlamingo、Otter 之间新图像理解结果的定性比较。

图 5.ISEKAI 数据集概述:该数据集完全由生成的图像组成,其中来自“ISEKAI World”的图像在现实生活中不存在,而来自“Real World”的图像来自现实。
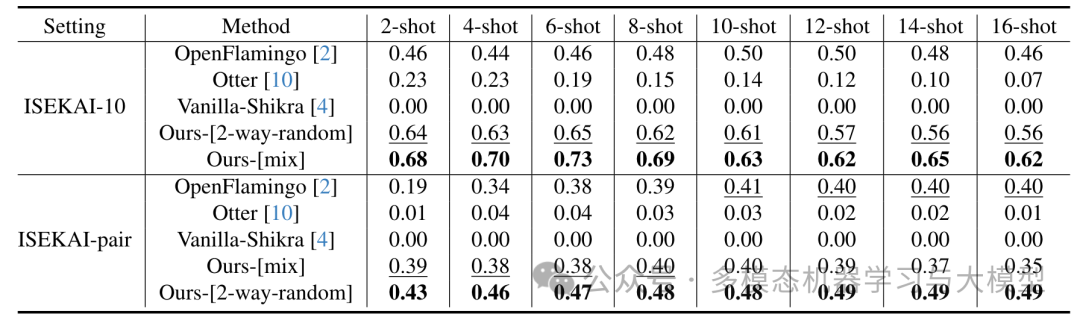 表 1.ISEKAI 从零次到 16 次的定量评估,以准确度衡量。
表 1.ISEKAI 从零次到 16 次的定量评估,以准确度衡量。
编辑:于腾凯
校对:梁锦程
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 1726
1726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









