







来源:时序人
本文约3000字,建议阅读5分钟
本文为你介绍一种新型框架 CATCH。多变量时间序列异常检测(MTSAD)旨在检测多变量时间序列中的异常数据。该技术被广泛应用于金融欺诈检测、疾病识别和网络安全威胁检测等领域。然而,现实中的多变量时间序列异常检测常面临挑战,传统方法难以检测复杂多样的异质子序列异常。
近日,来自华东师范大学和香港科技大学(广州)的研究团队提出了一种新型框架 CATCH,通过频域分块建模和通道感知机制,显著提升了多类型异常检测能力。研究团队在10个真实数据集和12个合成数据集上进行了广泛验证,CATCH 均展现出最优性能。这一创新成果为复杂场景下的异常检测提供了全新的解决方案。

【论文标题】
CATCH: Channel-Aware Multivariate Time Series Anomaly Detection via Frequency Patching
【论文地址】
https://arxiv.org/pdf/2410.12261
【论文源码】
https://github.com/decisionintelligence/CATCH
主要挑战
01、细粒度频率特征建模不足
在多变量时间序列中会出现异质的子序列异常,异常序列与正常序列在频域上会呈现出显著的差异,并且不同的子序列异常会体现在不同的频段上。
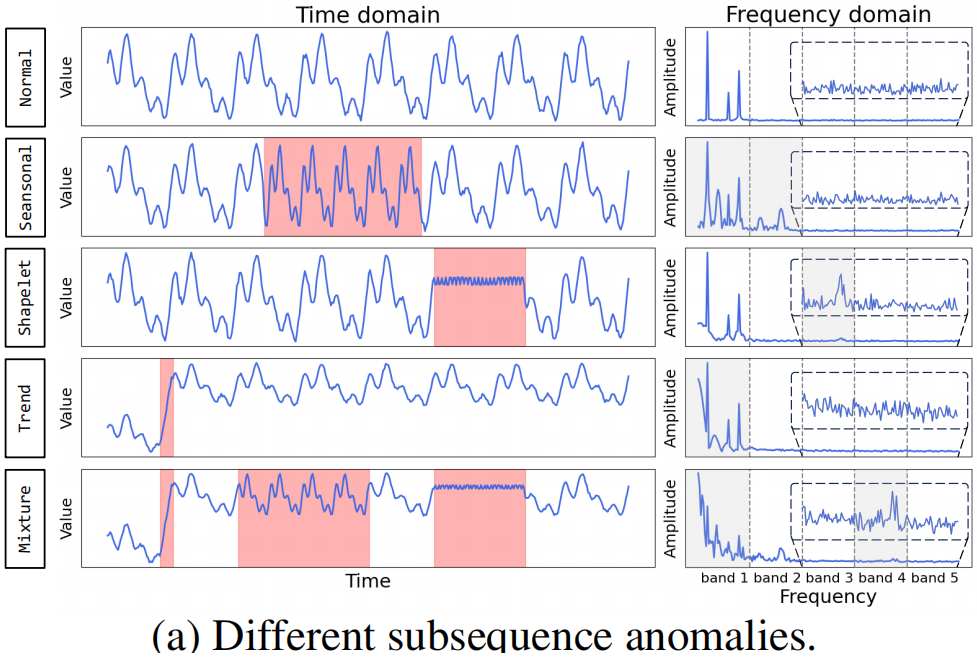
如图 (a) 所示,可以看到季节性 (Seansonal) 异常和趋势性 (Trend) 异常主要体现在低频段上,而形状特征 (Shapelet) 异常和混合性(Mixture) 异常会体现在中高频段上。
传统的基于重构的异常检测方法在频率域中往往以粗粒度建模,导致高频段细节丢失,无法检测到相应的异常。
02、复杂的通道间关系难以灵活建模
在多变量时间序列异常检测任务中,考虑通道之间的关系有助于更好地重构正常模式。
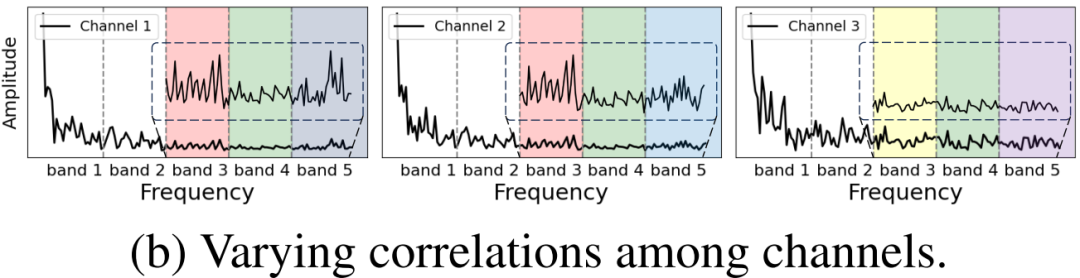
如图 (b) 所示,可以观察到不同频段上通道间关联性的变化。在第三频段上,通道一和通道二相似,但与通道三不同;在第四频段上,所有通道都相似,但在第五频段上又呈现出差异。
然而,常用的通道独立(CI)和通道依赖(CD)策略存在两极分化。
CI 策略强制对不同通道使用相同的模型。尽管这一策略具有一定的鲁棒性,但它忽略了通道之间的潜在交互,可能在未见通道的泛化能力和建模容量上受到限制;
CD 策略则同时考虑所有通道,具有更大的建模容量,但可能受到无关通道噪声的干扰,从而降低模型的鲁棒性。
核心贡献
为了解决多变量时间序列异常检测(MTSAD)问题,论文提出了一个通用框架——CATCH。该框架通过频域分块建模增强了子序列异常检测的能力,并在不同频段上整合了细粒度的自适应通道相关性。
研究人员设计了通道融合模块(CFM),以充分利用细粒度的通道相关性。利用双层多目标优化算法,CFM 能够迭代地发现适当的通道相关性,并促进不相关通道的隔离和相关通道的聚类,从而提供了建模容量和稳健性。
最后,研究人员在22个多变量数据集上进行了广泛的实验。结果表明,CATCH 的性能优于最先进的基线方法。
模型框架
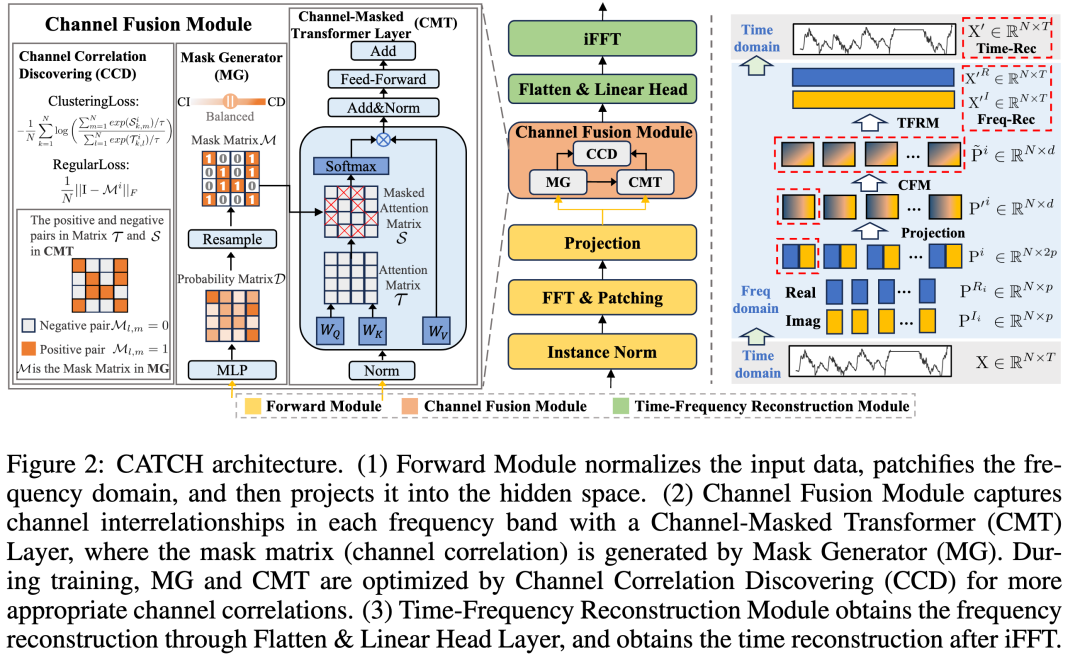
01、整体框架
图2展示了 CATCH 框架的整体架构,它主要由三个主要模块组成:正向模块,通道融合模块(CFM),以及时频重构模块(TFRM)。
输入的多变量时间序列首先通过正向模块,其中包括 Instance Norm 层、FFT & Patching 层、以及 Projection 层。Instance Norm 层减少训练和测试数据之间的分布差异,提升模型泛化能力。FFT & Patching 层将时间序列转换为频域信号,并通过分块操作进行精细建模。
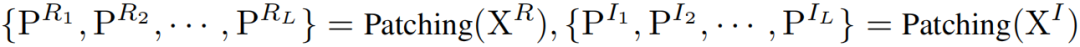
其中 和 分别是实部和虚部的分块。投影层将频率分块投射到高维隐空间:。处理后的时间序列进入通道融合模块 (CFM),以动态建模每个频带的通道相关性:
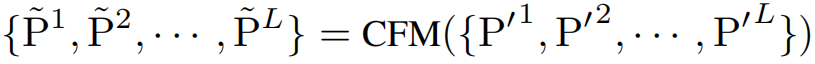
本文利用时频重建模块 (TFRM) 重建所有频谱的实部和虚部分块,并同时获得它们的时间重建结果:
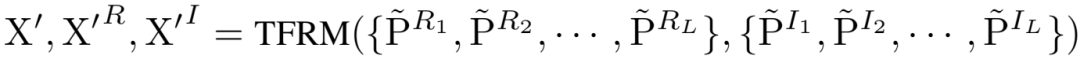
其中,是时域重建结果, 和是频域重建结果。
02、通道融合模块(CFM)
掩码生成器 (Mask Generator):通过生成二值掩码矩阵来感知每个频带的通道关联,通过生成相应的掩码来隔离无关通道的负面影响。
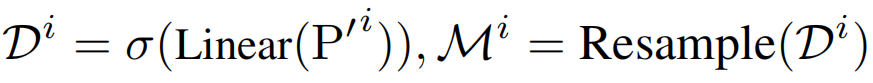
通道掩码 Transformer 层 (CMT):在掩码生成器输出频带掩码矩阵后,本文利用 Transformer 层进一步捕捉细粒度的通道相关性。在每个注意力模块前应用层归一化,以减轻频率成分幅度较大的过度关注现象。
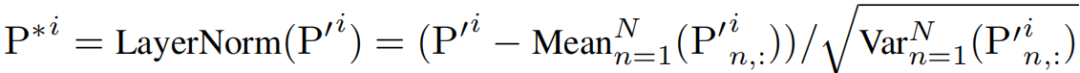
使用掩码注意力机制进一步建模相关通道之间的细粒度关系,并通过计算方式结合掩码矩阵,保持梯度传播。
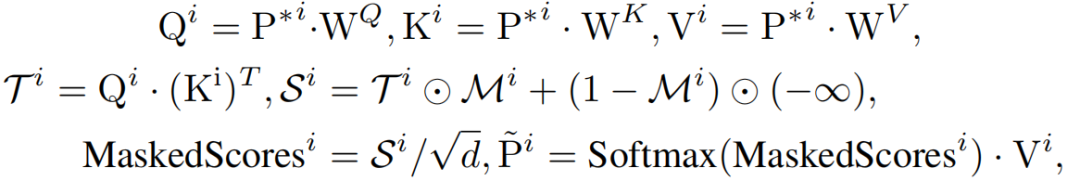
通道相关性发现 (CCD):为了优化掩码生成器,本文设计了两个损失函数来增强通道相关性。第一个是 ClusteringLoss,认为掩码生成器生成的通道间关联是局部最优的,并且依据这种关联制定相关通道和无关通道,从而采用类似对比学习 InfoNCE 损失函数的方法,鼓励注意力机制对相关通道进行聚类(反映在更高的注意力机制上);第二个是 RegularLoss,用于限制相关通道的数量,防止掩码生成器输出恒1矩阵。
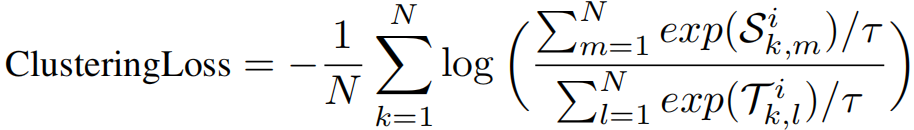
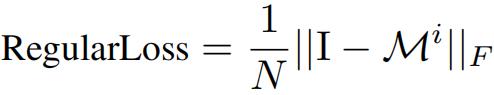
03、时间-频率重建模块(TFRM)
TFRM 包含两个部分:Flatten&Linear Head层,iFFT 层。在 CFM 完全提取细粒度通道相关性后,TFRM 将分块表示展平 (Flatten),并分别为实部和虚部块通过 Linear Head 实现频域重建,并最终通过 iFFT 获取时域重建。

本文在时域和频域中均采用重建损失函数,分别增强逐点和子序列建模能力。时间和频率域的重建损失函数为:
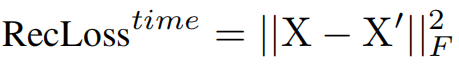
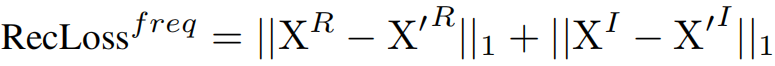
04、联合双重优化
总损失 主要由时域重构损失和频域重构损失,通道相关性发现机制 (CCD) 中的 ClusteringLoss 和 RegularLoss 组成。
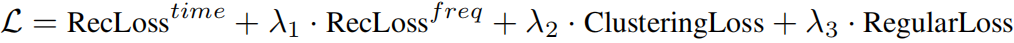
本文设计了一种新的联合双层训练过程,迭代优化掩码生成器 (Mask Generator) 和模型参数,每次优化掩码生成器后,其为不同频段生成局部最优的通道关联(掩码),基于这种关联,依据通道相关性发现机制 (CCD) 中的 ClusteringLoss 和 RegularLoss,进一步优化模型参数,促进 CMT 层去捕获相关通道间的关系。同时,RegularLoss 保证了发现的通道关联介于 CI 到 CD 之间,兼备了 CI 和 CD 的优势,在下游任务上取得更高的精度。

05、异常得分计算
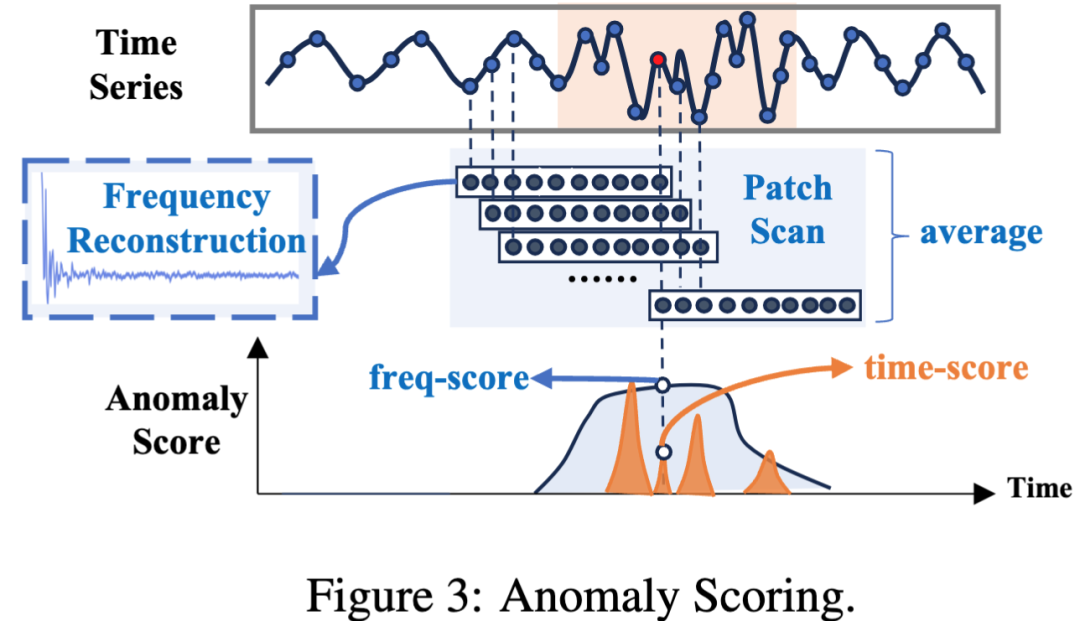
本文通过滑动窗口覆盖分析了每个时域上的点可能处于的子序列异常,并在频域上计算这些滑动窗口的异常得分,取均值得到频域异常分数(freq-score)综合评判该点是否处于子序列异常中,同时也计算了每个点的时域异常分数(time-score)来评判该点是否存在点异常。最终的异常分数是两者的加权和,从而兼具了检测点异常和子序列异常的能力:
实验结果
整体性能
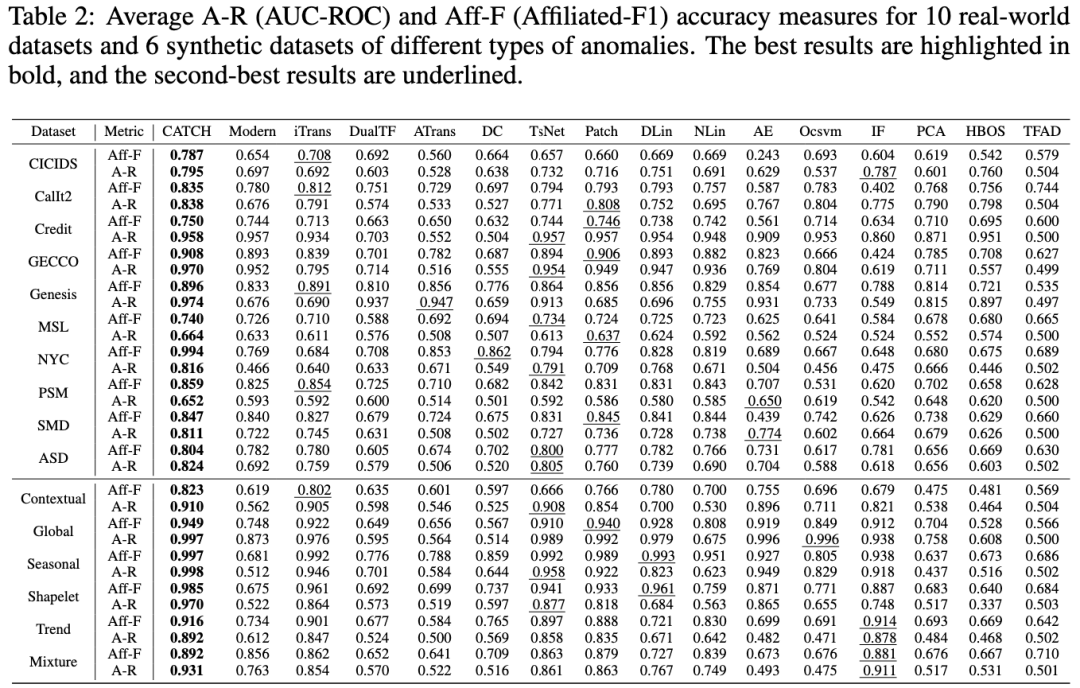
CATCH 在10个真实数据集和12个合成数据集均领先于当前最先进模型。
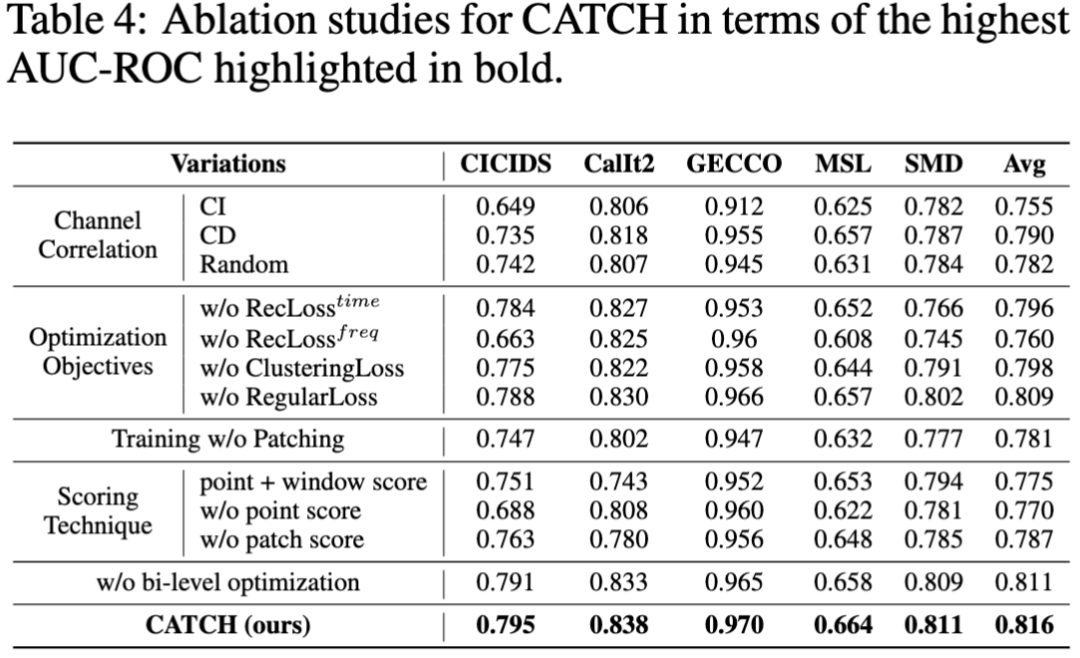
消融实验
文中进一步提供了一系列消融实验来验证模型框架设计的合理性。实验表明,CATCH 的设计在提升异常检测效果上是有效的。
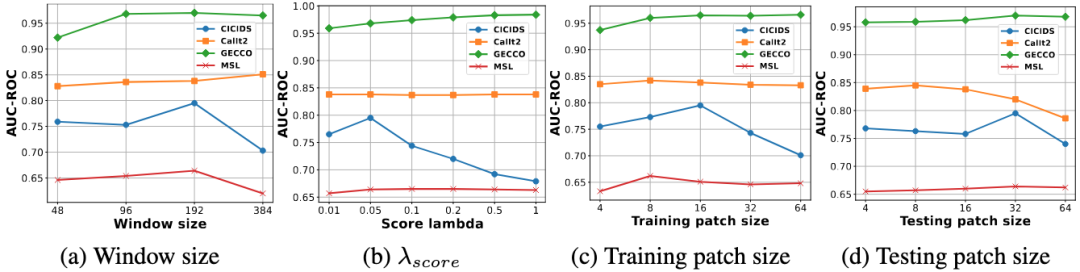
参数敏感性分析
通过参数敏感性实验,得出以下观察结论:
(1) 模型的窗口大小一般设置为96或者192即可。
(2) 较为稳定,基本处于0.01到0.1的范围内。
(3) Patch size 一般而言也较为稳定,仅从性能角度来看,可能需要根据某些数据集的模式进行针对性调整。
总结
本文提出了一种新型框架 CATCH,能够同时检测点异常和子序列异常。总结来说,它通过对频域划分 patch 处理,提供细粒度建模,灵活地感知并发现适当的通道相关性,利用双层优化算法优化注意力机制,从而提升其鲁棒性和建模容量。这些创新机制共同赋能 CATCH 精确检测点异常和子序列异常。在真实和合成数据集上的综合实验表明,CATCH 实现了最先进的性能。
*决策智能实验室依托华东师范大学,数据科学与工程学院,具有一支国际化,高水平导师团队,一人入选国家级领军人才,两人入选国家级青年人才。主要研究方向涵盖人工智能、机器学习和数据管理。通过对复杂异构数据(例如时间序列、时空数据、图、图像和分子结构等)进行高精度、高效率、自动的、高鲁棒性、可解释的分析和管理,助力不同行业的数字化转型和不同应用领域的决策支持。
编辑:于腾凯
校对:林亦霖
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 376
376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









