







来源:专知
本文约1000字,建议阅读5分钟我们提出了一种通过显式的基向量重分配(basis reallocation)来防止模态坍塌的算法,同时具备处理模态缺失问题的能力。
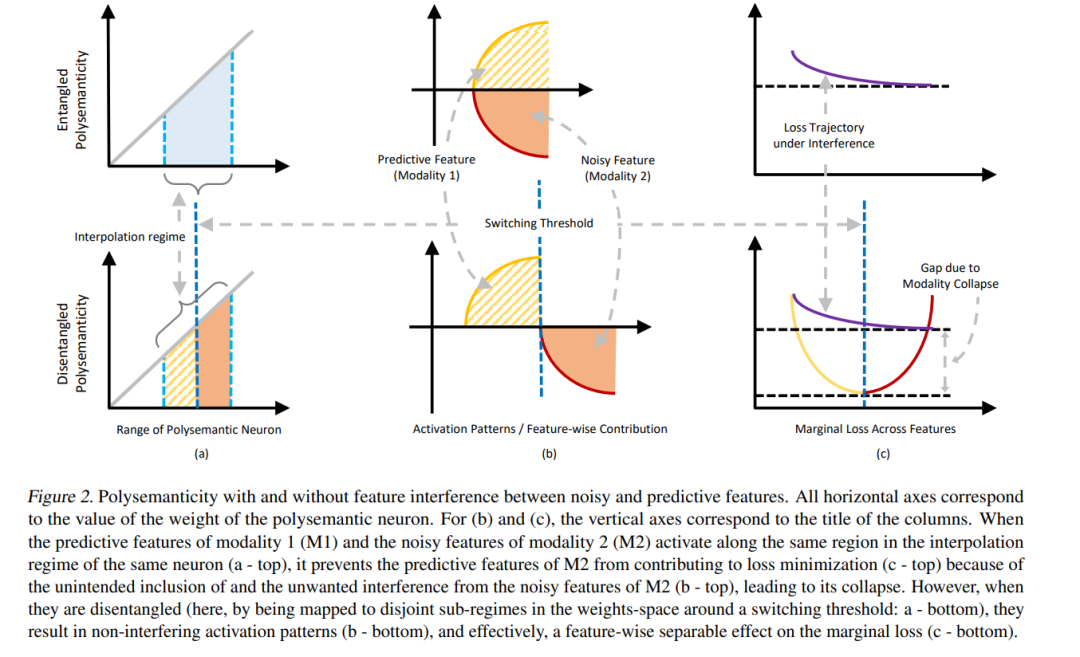
我们旨在对模态坍塌(modality collapse)这一近期观察到的经验现象进行基础性的理解。该现象指的是,在多模态融合任务中训练的模型倾向于依赖部分模态,而忽略其他模态。
我们发现,模态坍塌发生在以下情境中:某一模态中的噪声特征通过融合模块中的共享神经元,与另一模态中的预测性特征纠缠在一起,从而掩盖了前者模态中预测性特征的正向贡献,最终导致该模态在表示空间中“坍塌”。
我们进一步证明,跨模态知识蒸馏(crossmodal knowledge distillation)能够隐式地解耦这些纠缠表示:通过在学生模型编码器中释放秩瓶颈,从而对融合头输出进行去噪,而不会削弱任何一个模态的预测性特征。
基于上述发现,我们提出了一种通过显式的基向量重分配(basis reallocation)来防止模态坍塌的算法,同时具备处理模态缺失问题的能力。
我们在多个多模态基准任务上进行了大量实证实验,验证了上述理论结论。
项目主页:https://abhrac.github.io/mmcollapse/
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









