







25年6月来自北京人形机器人创新中心的论文“SwitchVLA: Execution-Aware Task Switching for Vision-Language-Action Models”。
部署在动态环境中的机器人不仅必须能够遵循多种语言指令,还必须能够灵活地适应用户意图在执行过程中的变化。虽然最近的“视觉-语言-动作”(VLA)模型在多任务学习和指令遵循方面取得了进展,但它们通常假设任务意图是静态的,无法在执行过程中收到新指令时做出响应。这种限制阻碍在动态设置(例如零售或家庭环境)中自然而稳健的交互,因为这些环境中实时意图的变化很常见。SwitchVLA,是一个统一的、执行-觉察的框架,无需外部规划器或额外的特定切换数据即可实现顺畅且反应灵敏的任务切换。任务切换建模为以执行状态和指令上下文为条件的行为调制问题。专家演示被细分为基于时间的接触阶段,使策略能够推断任务进度并相应地调整其行为。然后,通过条件轨迹建模,训练多行为条件策略,使其在不同行为模式下生成灵活的动作块。
任务切换与交互式执行。近期的研究探索了交互式执行,并越来越关注任务切换,可分为模块化系统和基于学习的方法。模块化系统采用规划器、分层策略或反馈回路 [12、13、28、14、15、29],但通常依赖于手动设计的回滚、前进或恢复策略,从而限制可扩展性以及与端到端 VLA 模型的集成。它们通常假设任务在发出新指令之前完成。例如,ReKep [14] 专注于高级交互,但存在延迟问题;YAY Robot [30] 支持上下文-觉察校正,但将回滚限制在脚本演示中;Hi Robot [16] 支持多行为学习,但需要复杂的、针对特定行为的训练。基于学习的方法 [17、31、18] 支持模型驱动的交互,但依赖于额外的专用数据。 RACER [17] 依靠精心挑选的故障数据集,在高层引入故障-觉察恢复,而 ADC [18] 则通过额外的演示来增强学习。
虽然大多数现有方法侧重于高层规划,但它们往往忽略动态执行和实时任务自适应的挑战。相比之下,本文工作针对 VLA 模型的低层执行,提出一种统一的策略,能够在执行过程中实现平滑、响应式和自适应的任务切换,而无需额外的演示。
SwitchVLA 是一个统一的学习框架,用于在“视觉-语言-动作”(VLA)设置下生成动态任务可切换动作。其方法并非将任务切换视为一个复杂的重规划问题,而是将其视为一个条件行为预测挑战,其中动作动态会根据不断变化的任务意图和执行反馈进行调整。
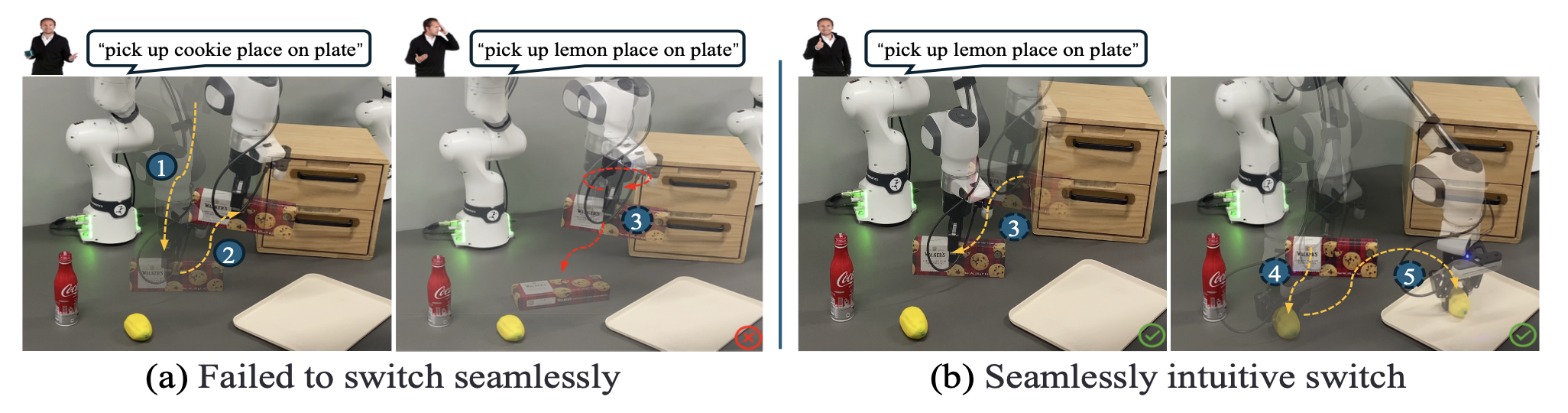
如图所示:(a) 过程 1 和 2 展示了正常的任务执行。当用户改变主意时(例如,“拿起柠檬放在盘子上”),传统的 VLA 模型无法调整其规划,导致不稳定的行为,例如振荡或掉落物品,如过程 3 所示。(b) 更自然的反应是归还之前持有的物品(例如,在过程 3 中放下饼干盒,然后在过程 4 和 5 中拿起柠檬并将其放在盘子上)。
问题表述
标准 VLA 执行。给定机器人的专家轨迹 τ = {(l|o_t, q_t)},其中 l 是该轨迹的任务语言指令,o_t 和 q_t 分别表示时间 t 时的视觉观察和机器人状态(例如关节角度)。目标是学习一个策略,以行为一致的方式映射 (l|o_t, q_t) → a_t+1,其中 a_t+1 表示机器人在时间 t + 1 时的动作。
任务切换。在实际部署中,机器人可能在执行过程中的任意时间接收新的任务指令 l′。这种动态输入会引入分布外的观察-指令对 (l′|o_t, q_t),对泛化带来重大挑战。确定两个核心子问题:(i) 指令接地——将策略与最新指令 l′ 对齐;(ii) 执行-觉察的切换——使用执行反馈(例如物理接触)来决定是前进、回滚还是切换到新的行为模式。
为了应对任务切换中的这些挑战,引入两个辅助监督信号——接触状态和行为模式——作为任务阶段和执行反馈的关键潜在指标。
指令-觉察控制的监督信号
接触状态。接触状态指示机器人与物体之间的物理交互。其定义为一个二元变量 c_t ∈ {0, 1},其中 0 表示无接触,1 表示接触。它可以通过以下方式推断:触觉感知、夹持器打开/关闭信号、启发式运动或力阈值,或使用预训练模型进行视觉语言解析。这种二元状态会随着时间的推移而演变,并指导任务阶段的进展,从而指导系统的下一步行动策略。
行为模式。将时间步 t 的行为模式定义为 b_t ∈ {0:forward,1:rollback,2:advance},每个值对应一个不同的行为策略:前进(b_t = 0)继续标准执行;回滚(b_t = 1)在接触过程中检测到意图不匹配时撤消之前的操作;推进(b_t = 2)在指令更新且不存在物理交互时转换到新的子任务。
接触状态和行为模式的标签,可以通过相位对齐的演示进行弱监督,也可以通过从执行反馈中自动解析的行为启发式方法得出。接触状态 c_t 和行为模式 b_t 共同提供关键的监督信号,以应对任务切换挑战。接触状态提供实时执行反馈以检测交互阶段,而行为模式则编码高级任务意图——是前进、回滚还是推进。这些信号调节策略,使其自适应地与更新的指令保持一致,并在动态执行下做出连贯的响应。
架构概述
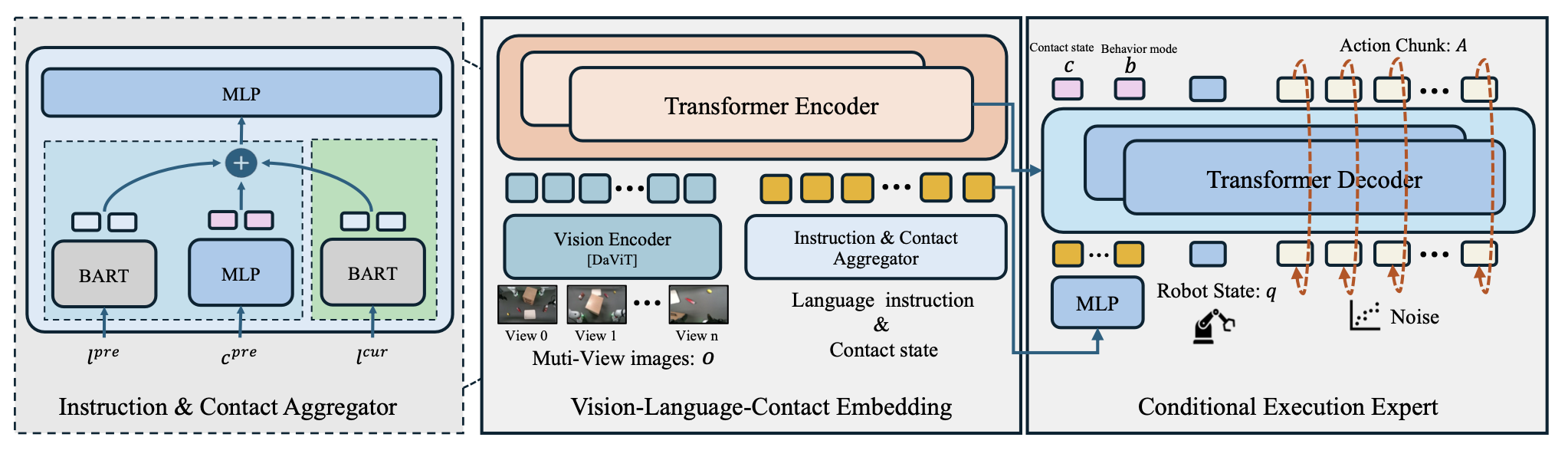
SwitchVLA 构建一个统一的架构,用于实现鲁棒且指令一致的任务执行,如图所示。该架构包含两个核心组件:(i) 视觉-语言-接触 (VLC) 嵌入模块,将视觉、语言和接触线索编码为统一的表示形式。(ii) 条件执行专家,根据当前多模态嵌入解码行为-觉察动作。其基于 Florence 2 [32] 构建 SwitchVLA。
VLC 嵌入模块
为了以时间和语义丰富的方式表示执行上下文,视觉-语言-接触 (VLC) 嵌入模块将多视角 RGB 观测、接触-觉察执行线索和成对的任务指令融合成一个统一的 token 序列。该嵌入作为下游行为选择的核心状态表示。
视觉编码器。采用基于 DaViT 的 [33] 主干网络,将多视角 RGB 观测值编码为稠密的空间 token,并进行投影以实现稳健的视觉基础。
指令和接触聚合器。通过整合历史和当前上下文信息,形成丰富的条件信号,从而实现行为-觉察动作的生成。具体而言,先前指令 lpre 和接触状态 cpre 反映过去的意图和交互历史,而当前指令 lcur 则根据新的任务指令更新语义目标。这些标记使用 BART 进行语言嵌入,并使用 MLP 进行接触编码,然后连接起来形成条件输入 token序列。
轨迹解析和接触标注。在实现中,采用视觉-语言轨迹解析方法:预训练的 VLM 基于腕部摄像头观测值将演示分割成粗略的、接触感知的阶段(如图所示),并结合抓手的开合信号以增强阶段边界的可靠性。这些轻量级标注丰富了 token 化的输入,而无需修改核心学习流程。

Transformer 融合。所有 tokens 都使用 Transformer 编码器-解码器 [34, 32] 进行融合,从而产生时间和语义丰富的嵌入。
条件执行专家
条件执行专家模块充当结构化动作解码器,将实时接触信号与高级行为意图相结合,以支持自适应且时间一致的动作生成。它同时预测每个时间步的三个同步输出:接触状态c_t∈{0, 1},反映机器人是否与环境进行物理交互;行为模式b_t∈{0, 1, 2},指示当前操作意图:正向执行、回滚先前步骤或前进到新的子任务;以及动作块A_t = {a_t+k},指定跨越接下来 K 个时间步的一系列低级动作。
结构化预测设计有助于实现接触感知行为自适应,并基于交互信号实现可靠的模式切换。它还支持对正向、回滚和前进动作进行显式行为推理,并通过联合解码多步动作块实现平滑的时间过渡,从而减少抖动并增强执行一致性。
训练与推理
使用特定行为条件进行训练
给定带标签的专家轨迹 τ_i = {(li|oi_t, ai_t, ci_t, bi_t)},设计特定行为的监督机制,以鼓励模型根据任务指令和物理交互信号调整其动作生成,如图所示。行为定义如下:
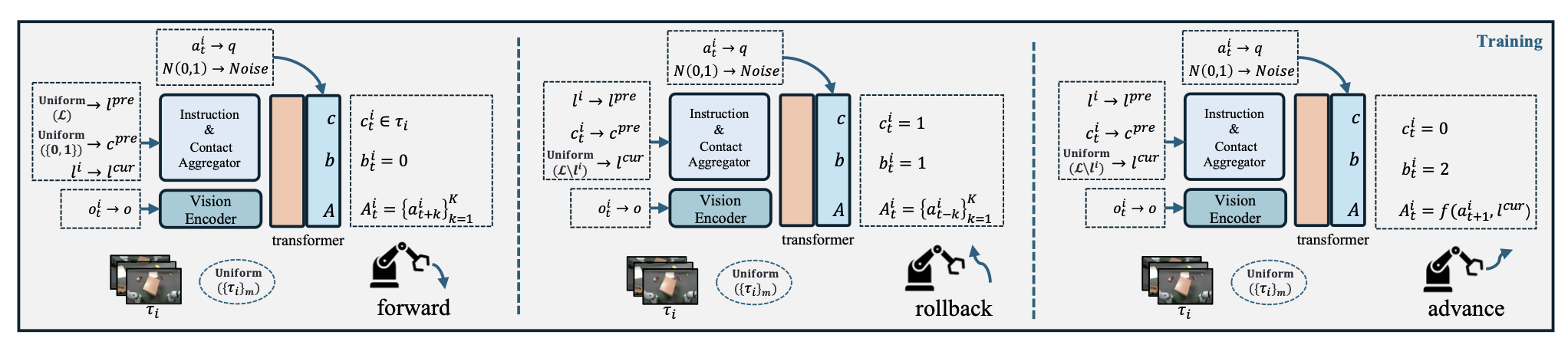
• 前向 (b_t = 0):预测匹配指令 lcur = li 的未来动作块 {ai_t+1 , … , ai_t+K }。通过在训练期间随机采样不同的 lpre 和 cpre 来增强对先前上下文的鲁棒性。
• 回滚 (b_t = 1):当呈现不匹配的指令 lcur ̸= li 且主动接触 ci_t = 1 时,生成反向动作 {ai_t−1 , …ai_t-K} 。这有助于模型通过物理反馈从语义不匹配中优雅地恢复。
• 前进(b_t = 2):在当前动作 ai_t 和规范起始姿势 anormal_0 之间的关节空间中进行线性插值,anormal_0 定义为指令 lcur 初始轨迹的平均值。此插值用 f(ai_t ,lcur) 表示,从而能够在无接触的假设下快速切换子任务。
动作序列使用流匹配损失 [9] 进行优化,这有助于生成平滑且动态可行的轨迹。接触状态 ci_t 和行为模式 bi_t 通过标准分类目标进行监督,确保对环境交互和高级意图的准确感知。
条件切换推理
在执行过程中,该策略基于三个关键输入:当前视觉观察 o_t、一对指令 (lpre, lcur) 以及先前传播的接触状态 cpre。在每个时间步,模型联合预测 (i) 新的接触状态 c_t(在下一步中用作 cpre)、(ii) 行为模式 b_t ∈ {0, 1, 2} 以及 (iii) 相应的动作块 A_t。
每个动作块执行完成后,模型更新 lpre ← lcur,并将预测的接触状态 c_t 传播到下一步。新的指令可以在任何时间步发出,模型会根据该指令重新评估 b_t 并动态调整行为。
根据预测的行为模式,系统执行以下策略之一:前向 (b_t = 0):根据当前目标继续标准动作预测;回滚 (b_t = 1):撤销先前的动作以从主动接触下的错误中恢复; 前进 (b_t = 2):跳转到新的子目标,同时将历史指令更新为 lpre ← lcur。
这种条件切换机制能够实现实时、上下文-觉察的任务转换,将语义意图与物理交互相结合,从而支持稳健且自适应的任务执行。
任务协议
任务切换发生在任务 A 的执行因收到任务 B 的新指令而中断时。基于此,进行两种类型的任务切换实验:成对评估和长序列评估。为了全面评估模型的功能,在成对实验中,在不同的执行阶段发送新指令:早期(接触前)、中期(接触中)和后期(操作后)。对于长序列实验,专注于中期切换,因为它可以更严格地评估方法的性能。只有当任务 A 顺利进入其指定的执行阶段,并且触发新指令后,任务 A 的行为符合预期,并且随后任务 B 完成时,任务切换才被视为成功。失败条件包括无法将物体(例如由于掉落)放置在目标位置、不遵循新指令或执行意外停止。每个评估重复 12 次试验,并对结果取平均值以确保统计可靠性。
模拟实验设置
在 LIBERO [35] 平台上使用 LIBERO-Goal 套件进行实验,该套件强调在单一表格操作环境中的任务多样性。选择 8 个任务进行多任务训练,每个任务包含 50 条专家轨迹。对于成对评估,从该集合中抽取 9 个具有代表性的任务组合;对于长序列评估,选择 6 个连续任务来评估顺序任务切换的性能。预测绝对关节空间,以确保正确的前进计算。
真实世界实验设置
真实世界实验在两个双臂 Franka Emika Panda 机器人工作站上进行,每个工作站执行四项独特的任务。数据收集通过人机遥控演示进行,涵盖推动、打开和拾取放置等基础技能。每个任务包含 200 条轨迹,由两个腕式摄像头、一个第三人称 RGB 摄像头以及机器人的本体感受状态记录。为了进行评估,物体被随机放置在预先定义的工作空间区域内。

















 1830
1830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









