








作者:Oluwole Alowolodu
翻译:李润嘉
校对:吴金笛
本文约3400字,建议阅读10分钟。
本文使用监督式机器学习技术来预测美国爱荷华州艾姆斯市(Ames, Iowa)的房价。
介绍
该项目旨在使用监督式机器学习技术来预测美国爱荷华州艾姆斯市(Ames, Iowa)的房价。Ames的房屋数据集来自Kaggle,这是谷歌旗下的一个在线平台,它为数据科学家和机器学习科学家提供合作和竞争的机会。Kaggle以提供不同的数据和竞赛为特色,其中便包括由Dean De Cock编辑的Ames房屋数据集。
该数据集包含具有81个特征的测试集和训练集。其中,训练文件包括1460条观测值,测试文件包含1459个观测值。
数据清洗
建模的第一步便是数据探索和数据清洗,旨在理解数据集中的每个特征和模式。将训练集和测试集合并到一起进行统一的数据工程,并对缺失值进行探索。以下是一张热力图,可从中看出数据中的缺失值所处的位置。
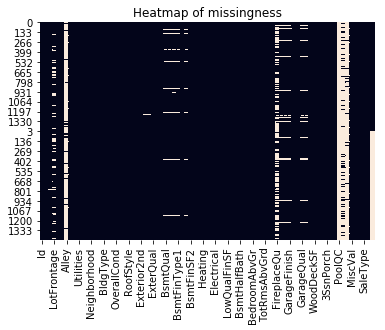
热图为特征缺失,尤其是包含大量缺失值的列提供了线索。通过对组合数据集的进一步分析,提取出每个特征所含缺失值的具体数量。可知共有34列含有缺失值,其中PoolQC,LotFrontage,FireplaceQual,Fence,Alley和MiscFeatures列的缺失值最多。以下是一个条形图,显示了缺失值的分布情况。
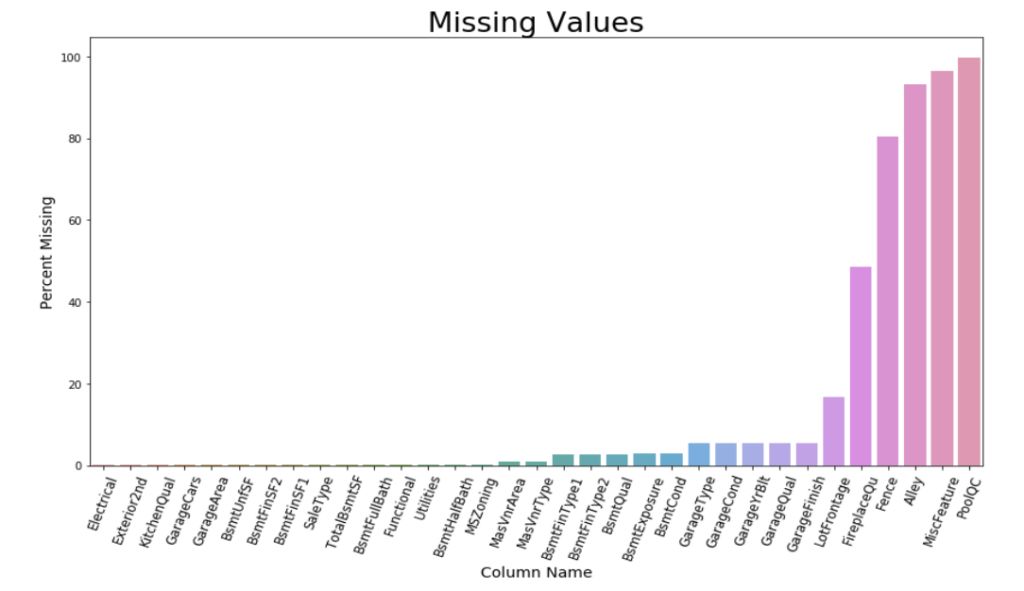
不同的含有缺失变量的特征有不同的估算方式。在估算之前需要考虑以下因素:该特征是分类型特征还是数值型特征,缺失值是随机完全缺失、随机缺失还是非随机缺失。
对于含有随机缺失值的数值型特征,比如 'LotFrontage' ,将使用位于同一区域的房屋的中位数来进行估算。其他含有缺失值的数值型特征大多根据一定的规则进行填充,大部分情况下使用0来填充。对于分类型特征,其中一些似乎含有缺失值,但是空值(NA)实际上意味着这个变量或房子显然缺少这样的特征,例如,'PoolQC' 中的空值意味着该变量没有 'Pool' 这个属性,它应当归为 'No_pool' 。类似的方法可适用于大多数特征。
删除异常值——缺失值估算的下一步是对数据集进行探索,找出可能的异常值。可通过在散点图上可视化每列来完成。
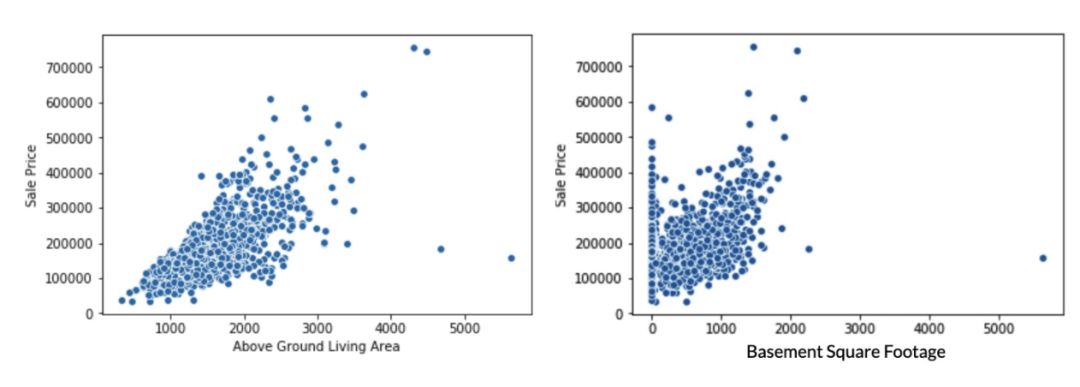
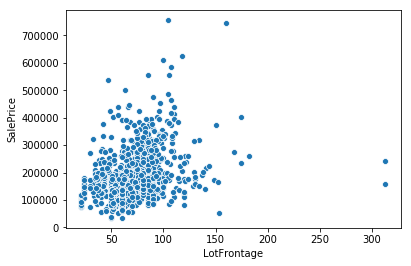
'AboveGroundLivingArea',BasementSquareF
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1291
1291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









