







方差
方差的大小描述一个变量的信息量,对于模型来说方差越小越稳定,但是对于数据来说,我们自然是希望数据的方差大,方差越大表示数据越丰富,维度越多
协方差
协方差描述两个变量的相关程度,同向变化时协方差为正,反向变化时协方差为负,而相关系数也是描述两个变量的相关程度,只是相关系数对结果相当于做了归一化处理,协方差的值范围是负无穷到正无穷,而相关系数值范围是在负一到正一之间
数据降维作用
1、减少存储空间
2、低维数据减少模型训练用时
3、一些算法在高维表现不佳,降维提高算法可用性
4、删除冗余数据
5、有助于数据的可视化
PCA
PCA本质上是将方差最大的方向作为第一维特征,方差描述的是数据的离散程度,方差最大的方向即是能最大程度上保留数据的各种特征,接下来第二维特征既选择与第一维特征正交的特征,第三维特征既是和第一维和第二维正交的特征.
将N维特征映射到K维上(K<N),这k维是全新的正交特征,是重新构造出来的k维特征,而不是简单的从n维特征中去除其余n-k维特征
PCA 实现
设现在有n条d维的数据,d表示数据特征数
(1) 将原始数据按列组成n行d列矩阵X
(2) 将X的每一列进行零均值化,即将这一列的数据都减去这一列的均值,目的:防止因为某一维特征数据过大对协方差矩阵的计算有较大的影响
(3) 求出2中零均值化后矩阵的协方差矩阵

C
是
[
d
×
d
]
维的矩阵
按特征值排序
.
取前
k
行
得到矩阵
P
[
d
×
k
]
[
n
×
d
]
×
[
d
×
k
]
=
[
n
×
k
]
相当于把数据从
d
维降低到了
k
维
C 是[d\times d]维的矩阵\\ 按特征值排序.取前k 行\\ 得到矩阵 P[d\times k]\\ [ n \times d ]\times[d \times k]=[n\times k]\\ 相当于把数据从 d 维降低到了 k 维
C是[d×d]维的矩阵按特征值排序.取前k行得到矩阵P[d×k][n×d]×[d×k]=[n×k]相当于把数据从d维降低到了k维
(4) 求出协方差矩阵的特征值和对应的特征向量
(5) 将特征向量按照对应的特征值大小从大到小排列成矩阵,取前k行组成矩阵P,而选择的k特征个数可以利用对前K个大的特征值求和来判断占了整个特征值和的比例来看对原始数据特征保留的程度
(6) Y = XP 即是降维到k为维后的数据
EVD
特征值分解,特征值分解的矩阵必须是方阵,特征值分解的目的:提取这个矩阵最重要的特征,特征值表示这个特征有多重要,特征向量即表示这个特征是什么,可以理解是这个变化最主要的方向

对方阵A进行特征值分解,则Q是由A的特征向量构成的矩阵,Q中的矩阵都是正交的,Σ是对角阵,对角线上的元素既是方阵A的特征值
这个线代学过
SVD
SVD可以看成是对PCA主特征向量的一种解法.
特征值分解只能够对于方阵提取重要特征,奇异值分解可以对于任意矩阵

U是左奇异矩阵,V是右奇异矩阵,均是正交矩阵,Σ是对角阵,除对角线元素外都是0,对角线元素是奇异值,在大多数情况下,前10%甚至前1%的奇异值的和便占据了全部奇异值之和的99%以上了,因此当利用奇异值分解对数据进行压缩时,我们可以用前r个大的奇异值来近似描述矩阵:

我们可以直接通过SVD完成对X降维到Z,看下面SVD分解:

同理我们也可以按照下面方式对数据的行进行压缩:

FA
因子分析法是数据降维的一种方法,因子分析法目的是找到原始变量的公共因子,然后用公共因子的线性组合来表示原始变量,举个例子:观察一个学生,统计出很多原始变量:代数、几何、语文、英语等各科的成绩,每天作业时间,每天笔记的量等等,通过这些现象寻找本质的因子,如公共因子有:逻辑因子、记忆因子、计算因子、表达因子
边缘高斯分布的协方差和均值
前验知识:在混合多元高斯分布中,如何求边缘高斯分布、条件高斯分布
联合多元随机变量x=[x1,x2] 的边缘高斯分布和条件高斯分布,其中x1属于Rr,x2属于Rm,则x属于Rr+m,则假设多元随机变量x服从均值为u,方差为Σ的高斯分布,可以得到x的符合的高斯分布形式为:

x1、x2称为联合多元高斯分布,则x1、x2的边缘高斯分布为:

我们可以通过推导x的协方差分布得到x1、x2的协方差分布:

这样我们便能够通过x得到x1和x2的边缘分布,即x1、x2边缘高斯分布满足:

条件高斯分布的协方差和均值
同时我们也可以得出给定x2情况下x1的 条件高斯分布:

则条件高斯分布的均值和协方差分别是:

在下述的因子分析法建模中便用到了这里的边缘高斯分布和条件高斯分布
我记得之前线代学过,都忘了…
找到了原始数据x的低维公共因子z的线性组合便完成了数据降维
因子分析法目的便是用z代替x,那么如何求出x、z公式中的参数u、⋀、ψ,这里便用到了之前介绍的联合多元高斯分布的边缘高斯分布和条件高斯分布,这里我们把x、z看成联合多元高斯分布:

因此我们可以得到变量x的边缘高斯分布为:

因此利用最大似然法优化目标函数为:

通过最大化上式,我们便可求得参数u、⋀、ψ,上式因为含有隐变量z无法直接求解,对于含有隐变量z的最大似然函数可通过EM算法求解
EM算法首先E-Step:

根据条件高斯分布可得:

其中:

于是便可得到:

M-step优化目标函数,其中z满足高斯分布的连续变量,因此:

这样再对各个参数求偏导,然后不断迭代E步和M步求得参数 u、⋀、ψ
ICA
详细推导:https://www.cnblogs.com/jerrylead/archive/2011/04/19/2021071.html
教程:https://blog.csdn.net/lizhe_dashuju/article/details/50263339
原理:http://skyhigh233.com/blog/2017/04/01/ica-math/
ICA又称盲源分离(Blind source separation, BSS)
ICA 在类脑研究中非常重要!
先用一张图客观理解一下ICA降维方法,在下图中
(1) 图表示的是主成分分析PCA对特征方向的选取
(2) 图表示的是独立成分分析ICA对特征方向选取

显然 ICA 比 PCA 厉害
它假设观察到的随机信号x服从模型[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F59vkkAT-1611547461353)(https://www.zhihu.com/equation?tex=\mathbf{x}%3D\mathbf{A}\mathbf{s})],其中s为未知源信号,其分量相互独立,A为一未知混合矩阵。ICA的目的是通过且仅通过观察x来估计混合矩阵A以及源信号s。
理论背景
在深入研究方法的复杂性之前,让我们考虑以下情况:一个音乐乐团在音乐会上演奏,你想尽可能产生较少的噪音来获取最干净的信号,但这是一项非常困难的事情。明智地,你在音乐厅,舞台和一排排座位上放置并牢固地安装了几个麦克风。此外,你可以安全地假设舞台上的所有演奏者在演唱会期间都是静止的(你不希望他们在演奏时站起来走动),每个乐器组都会播放他们自己的旋律。在一个激动人心的夜晚之后,每个麦克风都会捕获混合原始信号的录音,实际上您将拥有与麦克风一样多的信号混合。由于麦克风放置在音乐厅,混合信号在不同的麦克风上略有不同。现在你的最终目标是将混合信号分离提取或重建“纯信号”。虽然乐器组演奏的不同旋律当然应该保留,但是应该消除来自观众的声音噪音或者其它的一些环境噪声。
模型示意图:

该模型可以以简单的方式转移到EEG记录上,从脑电图电极记录的通道信号(由微伏振幅的时间序列表示)可以被认为是一组脑信号的混合信号,据推测这些混合信号通过皮层和皮质下区域中的神经元簇的同步产生,触发远场电位。虽然神经元本身局部是静止的并且不移动,但是激活模式基于体积传导的原理混合和合并,传播通过皮层,颅骨和组织的所有层,并且最终存在于任何头皮部位。同样,分析的理想结果是混合信号分离开逐步分析。

在示例中,目标是从记录的混合信号中提取统计上的“纯信号”,以便允许选择要保留的信号和丢弃信号。确切地说,这可以通过独立成分分析来完成(ICA; Makeig et al. 1996)。该技术已被公认为减轻伪影和分析头皮和颅内脑电图记录中统计独立皮质过程的有力工具。特别是在EEG数据记录使用有限的电极中,记录诸如眨眼或肌肉活动的伪迹时(例如在患者组,儿童或受试者自由移动的移动EEG实验中),ICA可能优于伪影阈值去伪。
ICA使用要求:
满足以下要求,ICA从信号混合信号中提取纯信号(详见 Jung et al. 1998):
1.由ICA提取的纯信号的特征在于它们的时间过程(神经激活模式),其在统计上独立于任何其它信号。事实上,这些激活是独立的成分(IC)。
2.纯信号(神经元簇)的发生以及记录位置(电极)在整个记录过程中是静止的。因此,成分朝向记录位置的地形位置是固定的。
3.混合是线性的,传播延迟可以忽略不计。
4.各个IC激活的概率分布不是精确的高斯分布。
除此之外,ICA没有对数据提出任何进一步的要求。事实上,它完全不知道信号的性质,这就是为什么ICA通常被称为盲源分离算法(Hyvärinen and Oja 2000)。请记住,IC成分纯粹是统计属性,因此它们不会将1:1映射到生理过程。在EEG / MEG数据的背景下,可以基于它们的时间过程(和地形分布)来检查所提取的IC成分,并且可以去除表示噪声,伪迹或其它非大脑过程的IC。然后,校正的一组独立分量反向逆算,这就可以在电极上修改原始信号,将其中的伪迹信号进行校正。
ICA的算法基础
ICA的数学基础,其中包括矩阵运算。通常,我们从电极上记录的时间上的混合信号开始。电极数据可以表示为2-D矩阵,其中行表示通道,列表示采样点。矩阵中的值是每个通道和采样点的记录电压幅值。我们称这个矩阵为x。我们现在可以生成解混矩阵W(ICA矩阵),当与数据矩阵x相乘时,将混合数据x转换为IC激活a。
Wx = a
矩阵a的每一行代表一个成分,每列代表一个采样点。成分a的激活可以表征为加权通道激活的线性和。

图1:使用六个EEG通道进行ICA解混和反演的示意流程图,产生六个独立的成分,每个成分都具有特定的IC激活和地形
实例

s=2时的原始信号
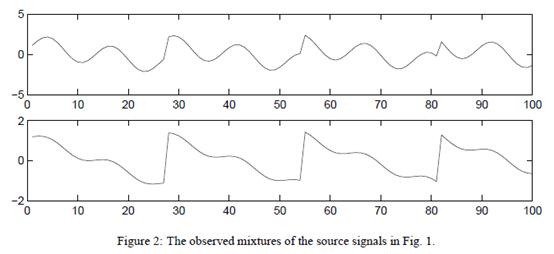
观察到的x信号

使用ICA还原后的s信号
从矩阵表示可以看出,你可以随时提取最多与电极一样多的成分(Makeig等,1997),因为来自N的混合信号电极被分解成N个分量的线性加权和。因此,ICA可以表征为完整的分解技术。这意味着可以通过将IC激活矩阵a乘以逆矩阵来反演解混合处理。ICA的计算目标是找到一个解混矩阵W,以便实现所有成分的最大时间独立性 。事实上,找到W是计算中最耗时的部分,在BrainVision Analyzer中提供的ICA组件可进行数据的计算。
Analyzer中实现ICA
在进行ICA算法时,一般建议是在过滤数据后进行。在Ocular Correction ICA的组件中,Analyzer中已经列出了最佳数据预处理步骤和建议,以确定应该使用多少通道和采样点进行有效的ICA分解。这些数据点应标记为“错误间隔”,因为ICA忽略了标记为“错误间隔”的数据部分。为ICA选择的数据应包括要分解的相关信息内容(例如EMG,EOG,ECG伪影)。因此,我建议使用更长,更有代表性的数据间隔甚至整个数据(前提是它可以提供内存约束)。而且,为了可视化IC拓扑图(表示逆矩阵W -1的列),应该存在电极位置。当使用具有未知位置的通道(Radius,Theta,Phi = [0,0,0])时,IC拓扑将保持为空,并且可以仅基于IC激活(矩阵a的行)来完成计算。一旦您的数据满足这些要求,您就可以通过转换ICA和反向ICA完成ICA解混,IC检查和选择以及反演的顺序(图2)。下面将更详细地描述每个变换内的步骤。

图2:转换步骤ICA和反向ICA
ICA算法将通道数据解混合成时间上最大独立分量的计算部分。你可以在Transformations > Frequency and Component Analysis > ICA下找到ICA按钮。根据转换对话框中设置的其余选项,Analyzer完成以下计算步骤。
求解
















 1831
1831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









