







原文:Auto-Encoding Variational Bayes
地址:https://arxiv.org/pdf/1312.6114.pdf
1 存在问题
- 变分贝叶斯(VB)方法涉及到对难处理后验的近似的优化,但公共平均场方法需要期望的解析解w.r.t.(with respect to 的缩写。是 关于;谈及,谈到的意思)近似后验,这在一般情况下也是棘手的,因此对于连续潜变量和/或参数具有难解后验分布的有向概率模型进行有效的推理和学习依旧是难解的问题
- 论文的解决方法:变分下界的重新参数化,以得到下界的一个简单可微无偏估计;这个SGVB(随机梯度变分贝叶斯)估计器可以用于几乎任何具有连续潜在变量和/或参数的模型的有效近似后验推断,并且可以直接使用标准的随机梯度上升技术进行优化
- 通过使用SGVB估计器优化识别模型,使推断和学习特别有效,这允许我们执行非常有效的近似后显推断使用简单的祖先采样,这反过来允许我们有效地学习模型参数,不需要对每个数据点使用昂贵的迭代推理方案(如MCMC)。学习的近似后验推理模型也可用于识别、去噪、表示和可视化等任务。当神经网络用于识别模型时,我们得到了变分自编码器
2 方法
- 本节的策略可用于推导具有连续潜在变量的各种有向图形模型的下界估计量(随机目标函数)。
- 有一个每个数据点带有潜在变量的i.i.d.数据集,
- 对(全局)参数执行最大似然(ML)或最大后验(MAP)推断,并对潜在变量进行变分推断。例如,接将这个场景扩展到对全局参数进行变分推断的情况
- 注意,我们的方法可以应用于在线的非平稳设置,例如流数据,但为了简单起见,这里我们假设一个固定数据集
2.1 问题场景
- 考虑由N个连续或离散变量组成的独立同分布样本X=xii=1 N
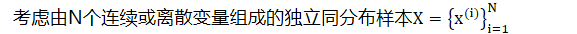
- 假设数据是由一些随机过程产生的,包括一个未观测到的连续随机变量 𝑧
- 该过程由两个步骤组成:
- 一个值 𝑧𝑖从某些先验分布𝑝𝜃∗(𝑧)生成;
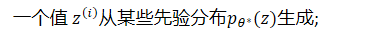
- 一个值𝑥𝑖是从某个条件分布𝑝𝜃∗(𝑥|𝑧)生成的。
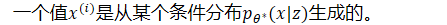
- 一个值 𝑧𝑖从某些先验分布𝑝𝜃∗(𝑧)生成;
- 假定先验𝑝𝜃∗(𝑧)和似然𝑝𝜃∗(𝑥|𝑧)来自分布的参数族𝑝𝜃(𝑧)和𝑝𝜃(𝑥|𝑧),并且它们的概率密度函数pdf几乎在𝜃和𝑧的任何地方都是可微的
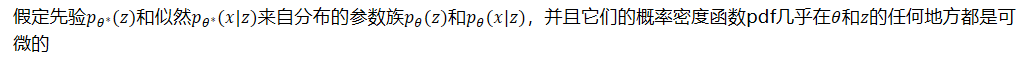
- 不幸的是,这个过程的很多内容都隐藏在我们的视图中:真正的参数𝜃∗以及潜在变量𝑧𝑖的值对我们来说都是未知的
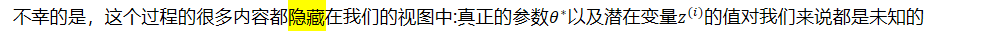
- 非常重要的是,没有对边际或后验概率做一般的简化假设。相反,我们在这里感兴趣的是一个通用算法,甚至在以下情况下有效地工作:
- Intractability(难解):边际似然的积分∫𝑝𝜃𝑧𝑝𝜃𝑥𝑧𝑑𝑧难解,即无法评价或者区分边际似然值,后验密度函数𝑝𝜃(𝑧|𝑥)=𝑝𝜃𝑥𝑧𝑝𝜃𝑧𝑝𝜃𝑥是难解的,所以不能使用EM算法。对于任何合理的平均场VB算法所要求的积分也是棘手的。这些难题相当普遍,并出现在中等复杂似然函数𝑝𝜃𝑥𝑧的情况下,如具有非线性隐层的神经网络

- 大数据集:我们有太多的数据,批处理优化成本太高;我们希望使用小批量甚至单个数据点进行参数更新。基于采样的解决方案,例如蒙特卡罗EM,通常太慢,因为它涉及到每个数据点昂贵的采样循环
- Intractability(难解):边际似然的积分∫𝑝𝜃𝑧𝑝𝜃𝑥𝑧𝑑𝑧难解,即无法评价或者区分边际似然值,后验密度函数𝑝𝜃(𝑧|𝑥)=𝑝𝜃𝑥𝑧𝑝𝜃𝑧𝑝𝜃𝑥是难解的,所以不能使用EM算法。对于任何合理的平均场VB算法所要求的积分也是棘手的。这些难题相当普遍,并出现在中等复杂似然函数𝑝𝜃𝑥𝑧的情况下,如具有非线性隐层的神经网络
- 对于上述场景中三个相关问题,我们感兴趣并提出解决方案:
- 对参数𝜃进行有效的近似ML或MAP估计。参数本身也可以是有趣的,例如,如果我们分析某些自然过程。它们还允许我们模拟隐藏的随机过程,并生成与真实数据相似的人工数据

- 对给定一个观测值𝑥的参数𝜃的潜在变量𝑧的有效近似后验推断。这对于编码或数据表示任务很有用。
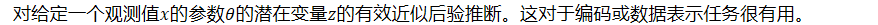
- 变量x的有效近似边际推理。这使得我们能够在需要先验x的情况下执行各种推理任务。计算机视觉中常见的应用包括图像去噪、着色和超分辨率
- 对参数𝜃进行有效的近似ML或MAP估计。参数本身也可以是有趣的,例如,如果我们分析某些自然过程。它们还允许我们模拟隐藏的随机过程,并生成与真实数据相似的人工数据
- 为了解决上述问题,我们引入一个识别模型𝑞𝜑(𝑧|𝑥):一个难以解决的真后验𝜃(𝑧|𝑥)的近似。注意,与平均场变分推断中的近似后验值相比,它不一定是阶乘,它的参数𝜑也不是从某种封闭形式的期望中计算出来的。取而代之的是,我们将介绍一种学习识别模型参数𝜑和生成模型参数𝜃的方法

- 从编码理论的角度来看,未观察到的变量z可以解释为一个潜在的表示或编码(code)。因此,在本文中,我们也将识别模型𝑞𝜑(𝑧|𝑥)作为一个概率编码器,因为给定一个数据点𝑥,它产生一个分布(例如,一个高斯分布)超过可能产生𝑥数据点的代码𝑧的值。类似地,我们将把𝑝𝜃(𝑥|𝑧)称为概率解码器,因为给定一个代码𝑧,它产生一个关于𝑥可能对应值的分布

2.2 变分约束
- 边际似然由单个数据点𝑙𝑜𝑔𝑝𝜃(𝑥1···𝑥𝑁) =𝑖=1𝑁𝑙𝑜𝑔𝑝𝜃(𝑥𝑖)的边际似然和组成,每一个都可以重写为
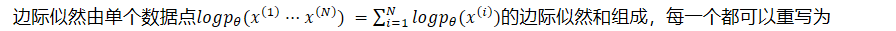
- 第一个RHS项是后验近似的KL散度。由于KL散度是非负的,第二个RHS项𝐿(𝜃,𝜑;𝑥𝑖)称为数据点𝑖的边际似然的(变分)下界,可表示为(RHS right hand side 表达式的右边 LHS left hand side 表达式的左边)

- 也可以写为
- 我们要微分和优化下界𝐿(𝜃,𝜑;𝑥𝑖)。变分参数𝜑和生成参数𝜃。然而,下界𝜑的梯度是一个问题,通常的(朴素的)蒙特卡罗梯度估计这类问题是


- 这个梯度估计器显示出非常高的方差(参见例[BJP12]),并且对我们的目的是不切实际的
2.3 SGVB估计器和AEVB算法
- 在这一节中,我们将介绍与参数相对应的下界及其导数的一个实用估计量。我们假设一个近似的后验𝑞𝜑(𝑧|𝑥),但请注意,该技术也可以应用于𝑞𝜑(𝑧),也就是说,我们不以𝑥为条件。在附录中给出了在参数上推断后验的完全变分贝叶斯方法。

- 在2.4节所述的某些温和条件下,对于选定的近似后验𝑞𝜑(𝑧|𝑥),我们可以使用(辅助)噪声变量𝜖的可微变换𝑔𝜑(𝜖,𝑥)重新参数化随机变量𝑧 ~ 𝑞𝜑𝑧𝑥
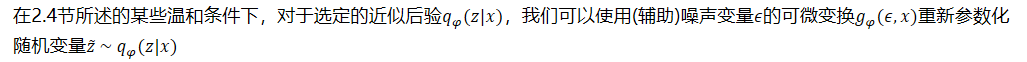
- 参阅2.4节,了解选择这样一个合适的分布𝑝(𝜖)和函数𝑔𝜑(𝜖,𝑔𝜑(𝜖,的一般策略。我们现在可以形成某函数𝑓(𝑧)w.r.t的期望的蒙特卡罗估计。qφ(z | x)如下:

- 我们将这种技术应用于变分下界(eq.(2)),得到我们的通用随机梯度变分贝叶斯(SGVB)估计量
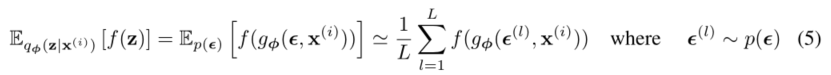
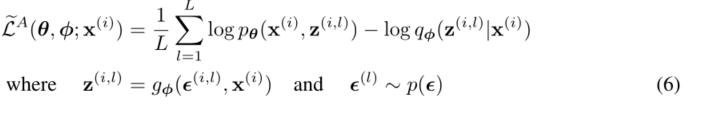
- 通常,等式(3)的KL-散度𝐷𝐾𝐿(𝑞𝜑(𝑧|𝑥𝑖)||𝑝𝜃(𝑍)可以解析地积分(见附录B),使得只有预期的重构误差𝐸𝑞𝜑(𝑧|𝑥𝑖)[log𝑝𝜃(𝑥𝑖|𝑧)]需要通过抽样进行估计。然后,KL散度项可以被解释为正则化𝜑,鼓励近似后验接近先验𝜃(𝑍)。这产生了SGVB估计𝐿𝐵𝜃,𝜑;𝑥𝑖∼ 𝐿(𝜃,𝐿𝐵𝜃,𝜑;𝑥𝑖∼ 𝐿(𝜃,的第二版本,对应于等式(3),其方差通常小于通用估计量:

- 给定来自具有N个数据点的数据集X的多个数据点,我们可以基于小批量构造整个数据集的边际似然下界的估计器:
- XM ={xi}i=1M是从具有N个数据点的完整数据集X中随机抽取的M个数据点的样本。在我们的实验中,我们发现,只要小批量大小M足够大,例如M=100,每个数据点的样本数量L∇θ,φL(θ;XM ),并且所得到的梯度可以与随机优化方法(如SGD或Adagard[dhs10])结合使用。有关计算随机梯度的基本方法,请参见算法1。

- 当查看在等式(7)中给出的目标函数时,与自动编码器的联系变得清晰。第一项是(近似后验距先验的KL散度)作为正则化,而第二项是预期的负重建误差。函数𝑔𝜑(⋅)被选择为将数据点𝑥𝑖和随机噪声向量𝜖𝑙映射到该数据点的近似后验的样本:𝑧𝑖,𝑙=𝑔𝜑(𝜖𝑙,𝑥𝑖)其中𝑧𝑖,𝑙∼qφ (z|𝑥𝑖)。随后,样本𝑧𝑖,𝑙被输入到函数𝑙𝑜𝑔𝑝𝜃(𝑥𝑖|z𝑖,𝑙),其等于生成模型给定z𝑖,𝑙的数据点𝑥𝑖的概率密度(或质量)。用自动编码器的话来说,这个术语是负重建误差(negative reconstruction error)

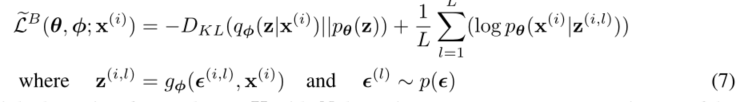
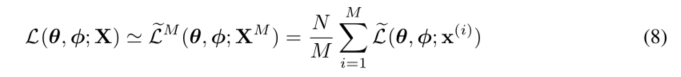

2.4 重新参数化技巧
- 为了解决我们的问题,我们调用了另一种从𝑞𝜑(𝑧|𝑥)生成样本的方法。基本的参数化技巧非常简单。设𝑧为连续随机变量,𝑧∼𝑞𝜑(𝑧|𝑥)为某条件分布。因此,通常可以将随机变量z表示为确定性变量𝑧=𝑔𝜑(𝜖,𝑧=𝑔𝜑(𝜖,,其中𝜖是具有独立边际的辅助变量𝑝(𝜖),𝑔𝜑(⋅)是由𝜑参数化的某个向量值函数。

- 这种重新参数化对于我们的情况是有用的,因为它可以用来重写期望w.r.t.𝑞𝜑(𝑧|𝑥),使得期望的蒙特卡罗估计是可微的w.r.t.𝜑。下面是一个证明.给定确定性映射𝑧=𝑔𝜑 (𝜖,𝑥)可知:𝑞𝜑𝑧𝑥Πidzi=𝑝𝜖Πidϵi因此:
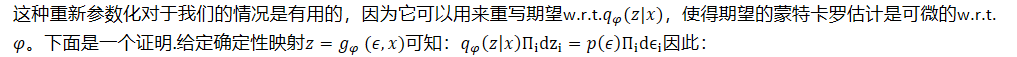
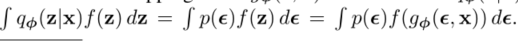
- 请注意,对于无穷小,我们使用记号约定𝑑𝑧=𝛱𝑖dzi

- 由此可以构造一个可微估计器:
- 在第2.3节中,我们应用这个技巧得到了变分下界的一个可微估计。
- 例如,以单变量高斯情况为例:
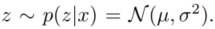
- 在这种情况下,有效的重新参数化是𝑧=𝜇+𝜎𝜖,其中𝜖是辅助噪声变量𝜖∼𝑁(0,1),因此
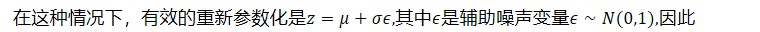
- 对于哪些𝑞𝜑(𝑧|𝑥),我们可以选择这样的可微变换𝑔𝜑(⋅)和辅助变量𝜖∼𝑝(𝜖)三种基本方法是:
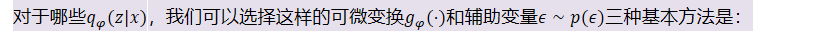
- 易驾驭的反向CDF。在这种情况下,设𝜖∼𝑈(0,1),使𝑔𝜑 (𝜖 ,𝑥)是𝑞𝜑(𝑧|𝑥)的逆CDF。例如:指数分布、柯西分布、Logistic分布、瑞利分布、帕累托分布、威布尔分布、倒数分布、冈培兹分布、冈贝尔分布和厄朗分布。

- 类似于高斯的例子,对于任何“location-scale”分布族,我们可以选择标准分布(location=0,scale=1)作为辅助变量𝜖,使𝑔(⋅)=𝑙𝑜𝑐𝑎𝑡𝑖𝑜𝑛+𝑠𝑐𝑎𝑙𝑒·𝜖。例如:拉普拉斯分布、椭圆分布、学生t分布、Logistic分布、均匀分布、三角形分布和高斯分布。

- 合成:通常可以将随机变量表示为辅助变量的不同变换。示例:log-正态(正态分布变量的指数)、Gamma(指数分布变量的和)、Dirichlet(Gamma变量的加权和)、Beta分布、X平方分布和F分布
- 易驾驭的反向CDF。在这种情况下,设𝜖∼𝑈(0,1),使𝑔𝜑 (𝜖 ,𝑥)是𝑞𝜑(𝑧|𝑥)的逆CDF。例如:指数分布、柯西分布、Logistic分布、瑞利分布、帕累托分布、威布尔分布、倒数分布、冈培兹分布、冈贝尔分布和厄朗分布。
- 当所有这三种方法都失败时,可以很好地近似逆CDF,所需计算的时间复杂度与PDF相当
3 示例:变分自动编码器 Variational Auto-Encoder
- 在本节中,我们将给出一个例子,其中我们将神经网络用于概率编码器𝑞𝜑(𝑧|𝑥)(近似于生成模型𝑝𝜃(𝑥,𝑝𝜃(𝑥,的后验),并且参数𝜑和𝜃与AEVB算法一起被优化

- 设先验超越潜变量为中心各向同性多元高斯𝑝𝜃(𝑍)=𝑁(𝑧, 𝑝𝜃(𝑍)=𝑁(𝑧, 。请注意,在这种情况下,前者缺少参数。我们设𝑝𝜃(𝑥|𝑧)为多元高斯分布(实值数据)或伯努利分布(二进制数据),其分布参数由多层线性规划(具有单一隐层的完全连通神经网络,见附录C)计算得出。注意,在这种情况下,真正的后验𝑝𝜃(𝑧|𝑥)是难以处理的。虽然形式𝑞𝜑(𝑧|𝑥)有很大的自由度,但我们将假设真实的(但难以处理的)后验概率采用近似高斯形式,并具有近似对角线协方差。在这种情况下,我们可以使变分近似后验为具有对角协方差结构的多元高斯

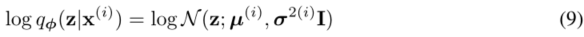
- 请注意,这只是一个(简化)选择,而不是方法的限制
- 在近似后验中的平均数和标准差,µ𝑖和𝜎𝑖是编码MLP的输出,即数据点𝑥𝑖的非线性函数和变参数𝜑(见附录C)。

- 如第2.4节所述,我们从后验取样
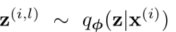
- 使用

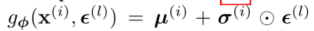
- 其中𝜖𝑖∼𝑁0,1
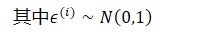
- 在这个模型中,𝑝𝜃(𝑍)(先验)和𝑞𝜑(𝑧|𝑥)都是高斯的;在这种情况下,我们可以使用eq(7)的估计量。可无须估计而计算和微分KL散度的地方(见附录B)。此模型和数据点xi的最终估计值为:

- 如上所述和附录C中所解释的,解码术语𝑙𝑜𝑔𝑝𝜃(𝑥𝑖|𝑧𝑖,𝑙)是伯努利或高斯MLP,这取决于我们建模的数据类型。
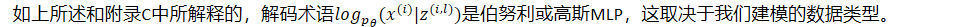
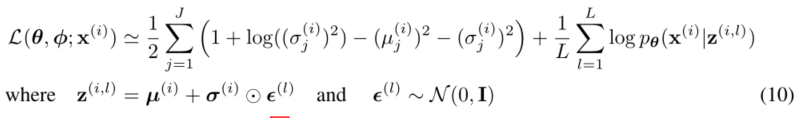
4 相关工作
- 据我们所知,唤醒-睡眠算法[HDFN95]是文献中唯一一种适用于同一类连续潜变量模型的在线学习方法。与我们的方法一样,唤醒-睡眠算法采用了近似真实后验的识别模型。唤醒-睡眠算法的一个缺点是它需要同时优化两个目标函数,这两个目标函数一起并不对应于边缘似然(范围)的优化。唤醒睡眠的一个优点是,它也适用于具有离散潜变量的模型。唤醒睡眠与每个数据点的AEVB具有相同的计算复杂度。
- 随机变分推理[HBWP13]最近受到越来越多的关注。最近,[BJP12]引入了一种控制变量格式来降低第2.1节中讨论的NA?ı梯度估计的高方差,并将其应用于后验的指数族近似。在[RGB13]中,引入了一些通用的方法,即控制变量方案,以降低原始梯度估计器的方差。在[SK13]中,在学习指数族近似分布的自然参数的随机变分推理算法的一个有效版本中,使用了与本文类似的重新参数化。
- AEVB算法揭示了有向概率模型(用变分目标训练)和自动编码器之间的联系。线性自动编码器和一类生成性线性高斯模型之间的联系早已为人所知。文献[98]证明了PCA对应于先验𝑝(𝑍)=𝑁(0,𝐈),条件分布𝑝(𝑥|𝑧)=𝑁(𝒙;𝑾𝑧,𝜖𝐈)的线性高斯模型的一种特殊情况的极大似然解,特别是无穷小𝜖

最近关于自动编码器的相关工作[VLL+10]表明,非正则化自动编码器的训练准则对应于输入X和潜在表示Z.最大化(w.r.t.)之间互信息的下界的最大化(参见Infomax原理[Lin89])。互信息的参数)等价于最大化条件熵,该条件熵的下限是在自动编码模型[VLL+10]下数据的期望对数似然,即负重构误差。然而,众所周知,这种重建标准本身并不足以学习有用的表示[BCV13]。已经提出了正则化技术来使自动编码器学习有用的表示,例如去噪、压缩和稀疏自动编码器变体[BCV13]。SGVB目标包含由变分界规定的正则化项(例如,等式)。(10),缺少学习有用表示所需的通常讨厌的正则化超参数。相关的还有编解码器架构,比如预测稀疏分解(PSD)[KRL08],我们从中得到了一些启示。同样相关的还有最近引入的生成性随机网络[BTL13],其中有噪音的自动编码器学习从数据分布中采样的马尔可夫链的转移算子。在[SL10]中,识别模型被用于深度Boltzmann机器的有效学习。这些方法要么针对非规范化模型(即像Boltzmann机器这样的无向模型),要么局限于稀疏编码模型,与我们提出的学习一般类有向概率模型的算法形成对比。
- 最近提出的DUN方法[GMW13]也使用自动编码结构学习有向概率模型,但是他们的方法适用于二进制潜在变量。最近,[RMW14]还使用本文描述的重新参数化技巧在自动编码器、有向概率模型和随机变分推理之间建立了联系。他们的工作是独立于我们开发的,为AEVB提供了一个额外的视角。
5 实验
- 我们训练了MNIST和Frey人脸数据集的图像生成模型,并在变分下界和估计的边缘似然方面对学习算法进行了比较。
- 使用了第3节中的生成模型(编码器)和变分近似(解码器),其中所描述的编码器和解码器具有相等数量的隐藏单元。由于Frey面部数据是连续的,我们使用具有高斯输出的解码器,与编码器相同,除了在解码器输出处使用S型激活函数将平均值限制在区间(0,1)之外。注意,对于隐藏单元,我们指的是编码器和解码器的神经网络的隐藏层。
- 参数更新使用随机梯度上升,其中梯度计算通过微分下限估计𝛻𝜃, 𝜑 𝐿(𝜃,𝜑;𝑋)(参见算法1),加上对应于先验𝑝(𝜃)=𝑁(0,𝐼)的小重量衰减项。此目标的优化等效于近似地图估计,其中似然梯度由下限的梯度近似。

- 我们比较了AEVB和唤醒睡眠算法[HDFN95]的性能。我们对唤醒-睡眠算法和可变自动编码器使用相同的编码器(也称为识别模型)。所有参数,包括变分参数和生成参数,都是通过随机抽样从N(0,0.01)中初始化的,并使用MAP准则进行联合随机优化。步长采用Adagrad[DHS10]进行调整;Adagrad全局步长参数根据最初几次迭代中训练集的性能从{0.01,0.02,0.1}中选择。使用大小为M=100的小批次,每个数据点L=1个样本。
- 似然下限
- 我们训练了生成模型(解码器)和相应的编码器(也称为。识别模型)在MNIST的情况下有500个隐藏单元,在Frey人脸数据集的情况下有200个隐藏单元(为了防止过度拟合,因为这是一个小得多的数据集)。隐藏单元数的选择是基于先前关于自动编码器的文献,不同算法的相对性能对这些选择不是非常敏感。图2显示了比较下限时的结果。有趣的是,多余的潜变量并没有导致过拟合,这是由变分界的正则化性质解释的。
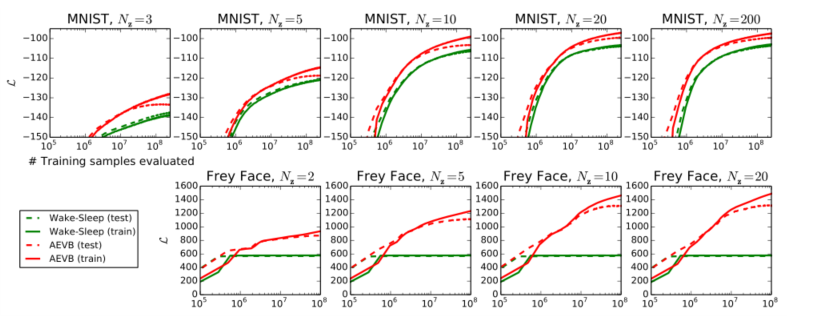
- 图2:对于不同维度的潜在空间(NZ),在优化下限方面,我们的AEVB方法与唤醒-睡眠算法进行了比较。我们的方法收敛速度快得多,并且在所有的实验中都得到了更好的解。有趣的是,更多的潜在变量并不会导致更多的过拟合,这可以用下限的正则化效应来解释。垂直轴:每个数据点的估计平均变分下限。估计符方差很小(<1)并被省略。水平轴:评估的训练点数量。在英特尔至强CPU有效运行速度为40GFLOPS的情况下,每百万个训练样本的计算时间约为20-40分钟。
- 边际似然
- 对于非常低维的潜在空间,可以使用MCMC估计器来估计所学习的生成模型的边际似然。有关边际似然估计器的更多信息请参见附录。对于编码器和解码器,我们再次使用神经网络,这一次有100个隐藏单元和3个潜在变量;对于更高维的潜在空间,估计变得不可靠。同样,我们使用了MNIST数据集。AEVB和觉醒睡眠方法与使用混合蒙特卡罗(HMC)[DKPR87]采样器的蒙特卡罗EM(MCEM)进行了比较;详细信息见附录。在训练集规模较小和较大的情况下,比较了这三种算法的收敛速度。结果如图3所示。
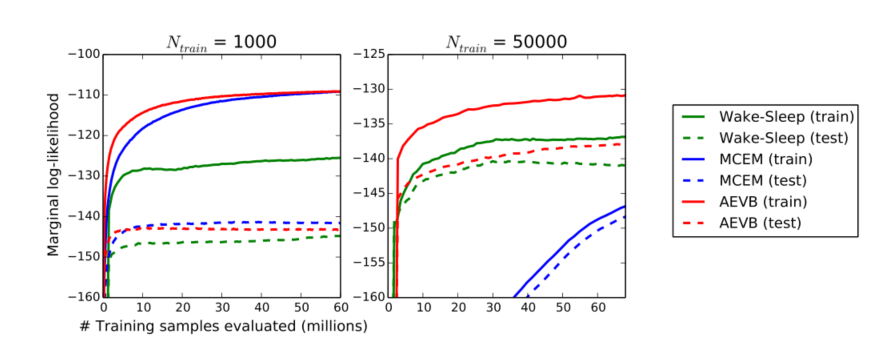
- 对于不同数量的训练点,AEVB与唤醒-睡眠算法和蒙特卡罗EM在估计的边际似然方面进行了比较。Monte Carlo EM不是在线算法,并且(与AEVB和唤醒休眠方法不同)不能有效地应用于完整的MNIST数据集
- 高维数据的可视化:如果我们选择低维潜在空间(例如2D),我们可以使用学习到的编码器(识别模型)将高维数据投影到低维流形上。关于MNIST和Frey人脸数据集的2D潜在流形的可视化,请参见附录A。

- 用AEVB学习的具有二维潜在空间的生成模型的学习数据流形的可视化。由于潜在空间的先验是高斯的,通过高斯的逆CDF变换单位正方形上的线性坐标,从而产生潜在变量z的值。对于这些值z中的每一个,我们绘制了相应的生成pθ(x|z)和学习参数θ。

- 从MNIST的学习生成模型中随机抽取不同维度的潜在空间样本
6 结论
- 我们引入了一种新的变分下界估计--随机梯度VB(SGVB),用于对连续潜变量进行有效的近似推断。所提出的估计器可以用标准的随机梯度法直接微分和优化。在身份证的情况下。我们介绍了一种高效的推理和学习算法,自动编码VB(AEVB),它使用SGVB估计器学习近似推理模型。理论上的优势体现在实验结果上。
7 未来工作
- 由于SGVB估计器和AEVB算法几乎可以应用于任何具有连续潜变量的推理和学习问题,因此有很多未来的发展方向:(I)利用与AEVB联合训练的用于编码器和解码器的深层神经网络(例如卷积网络)来学习分层生成结构;(Ii)时间序列模型(即动态贝叶斯网络);(Iii)SGVB在全局参数中的应用;(Iv)具有潜变量的监督模型,用于学习复杂的噪声分布。















 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









