







这个模型是KDD Cup 2021 OGB-LSC(Open Graph Benchmark Large-Scale Challenge)图预测赛道第一名: KDD Cup 2021 | 微软亚洲研究院Graphormer模型荣登OGB-LSC图预测赛道榜首
论文地址: https://arxiv.org/abs/2106.05234
论文代码: https://github.com/Microsoft/Graphormer
内容:提出了图上的Transformer,命名为Graphormer,大致实现:在transfomer的注意力分数中,添加了边信息和空间信息。文章还证明了以往模型,如GCN,GIN,GraphSAGE使其子集,因而Graphormer的效果更强。
1 GCN和Transformer
GCN
- 老朋友了,每个节点从邻居节点那聚合信息,然后使用聚合的信息和自己原本的信息进行更新
- 上述是节点级表示,若需要得到图级表示,还需要将整个图的信息用一个读出层进行处理
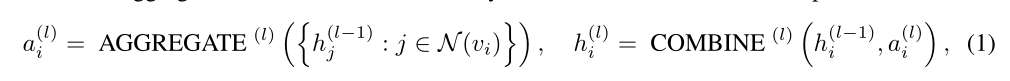

Transformer
- 老老朋友了,不解释

2 Graphormer模型架构
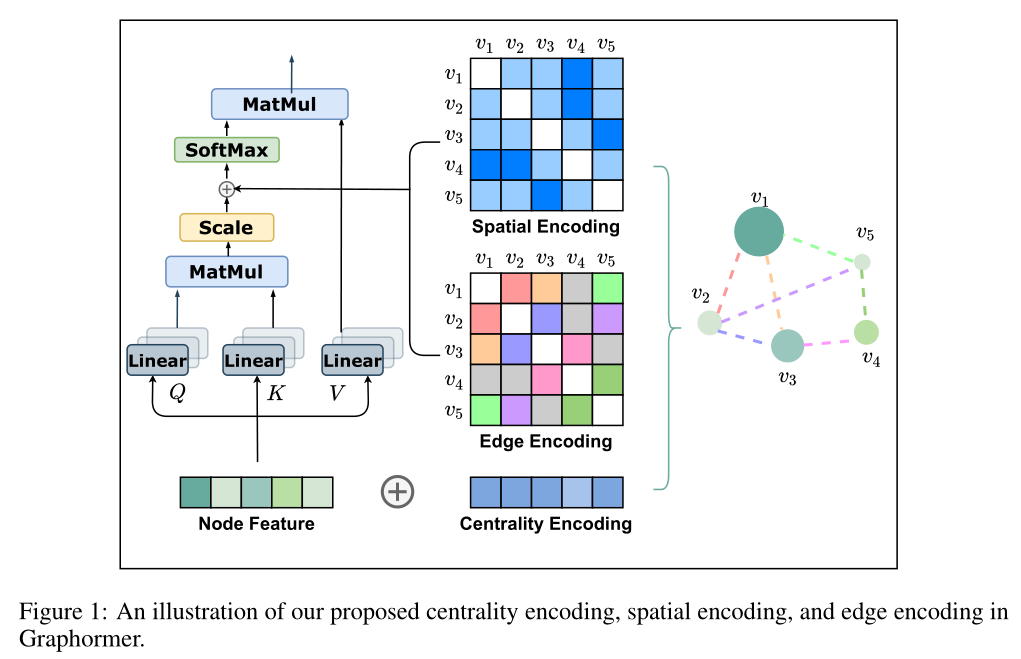
结构编码
- 文中有三种:点度中心性,空间编码和边编码
点度中心性:编码一个节点的重要性
- 因为衡量的是一个节点的重要性,只需要加到节点表征中去就行
- 这不是一个新东西了,类似的概念很多,详见: 图或网络中的中心性:点度中心性、中介中心性、接近中心性、特征向量中心性、PageRank_知行合一,止于至善-CSDN博客_特征向量中心性
- 简单来说,点度中心性的思想是,如果一个节点的邻居节点越多,那么他就重要,计算方法:一个点的点度中心性 = 邻居数 / 总节点数减一(因为一个节点最多就这么多邻居)。例子:

- 图中D与其他6个节点都相连,从点度中心性的角度来看D非常重要,D的点度中心性为6/6=1
- 回到Graphormer,首先计算每个节点的入度和出度,然后将其编码为向量,加到他自己的编码中去
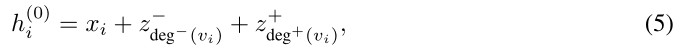
- 嵌入入度和出度的神经网络deg(+代表出度,-代表入度)当然是可以学习到
- h代表节点特征向量,x使是原本的特征向量,两个z使其节点中心性的编码
- 此时,对于一个具体的入度或者出度,其对应的节点中心性的编码都是一致的,这是一个很好的特征
空间编码
- Transformer本身没有处理顺序数据,亦即结构信息的能力。在处理文本的时候手动添加了位置编码。而在图中,需要寻找一种方法处理图的结构信息
- 本文不是将空间位置直接编码在节点中,非欧数据直接编码空间信息到节点也确实不容易。但是处理相对位置信息就比较好想到了。具体来说,计算每一对节点之间的注意力系数的时候,将空间编码加到注意力系数之中。首先找到节点之间的最短路径长度𝜙(𝑣𝑖,𝑣𝑗),如果没有连通,可以将其设置为一个特殊值,比如:𝜙𝑣𝑖,𝑣𝑗=−1

- 然后,与节点中心度一样,还是使用一个可学习的缩放函数,将标量𝜙(𝑣𝑖,𝑣𝑗)进行缩放,然后加到注意力系数A中
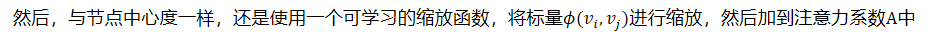
- 将𝜙(𝑣𝑖,𝑣𝑗)用可学习的网络进行缩放,可以让图自适应地调整不同距离的节点重要性。比如,如果b是递减函数,那么模型认为,随着距离增加,节点重要性会逐渐降低

- b在不同层之间是共享的
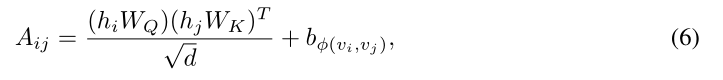
边编码
- 以往有两种方法:1)将边缘特征添加到关联节点的特征中;2)对于每个节点,其相关边的特征将与聚合中的节点特征一起使用。然而,这种使用边特征的方法仅将边信息传播到其关联的节点,这可能不是利用边缘信息表示整个图的有效方法
- 本文的全新方法:首先找到两节点间的最短路径(之一)SP(shortest path),然后将路径中的边的编码,乘以一个权重之后(类似于空间编码中的缩放函数b),加到注意力系数中
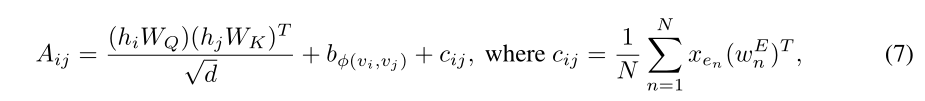
一些实现细节
- 计算多头注意力(MHA)的时候,先层归一化,然后在加上原来的特征,过FFN的时候也是这么处理的。要问为什么,没有为什么,经验表示这更好
- 在图中添加了一个特殊节点[VNode],并于其他所有节点相连。在更新节点的时候,[VNode]就可以聚集所有的节点表示,它的节点特征就是整个图的嵌入。这其实有点像BERT的[CLS]。
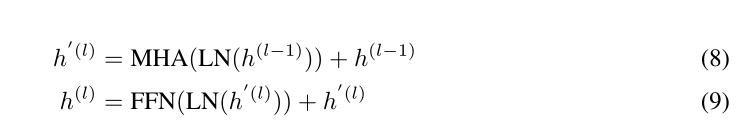

3.3节具体说明了Graphormer是很多其他GNN的超集,感兴趣可以看看
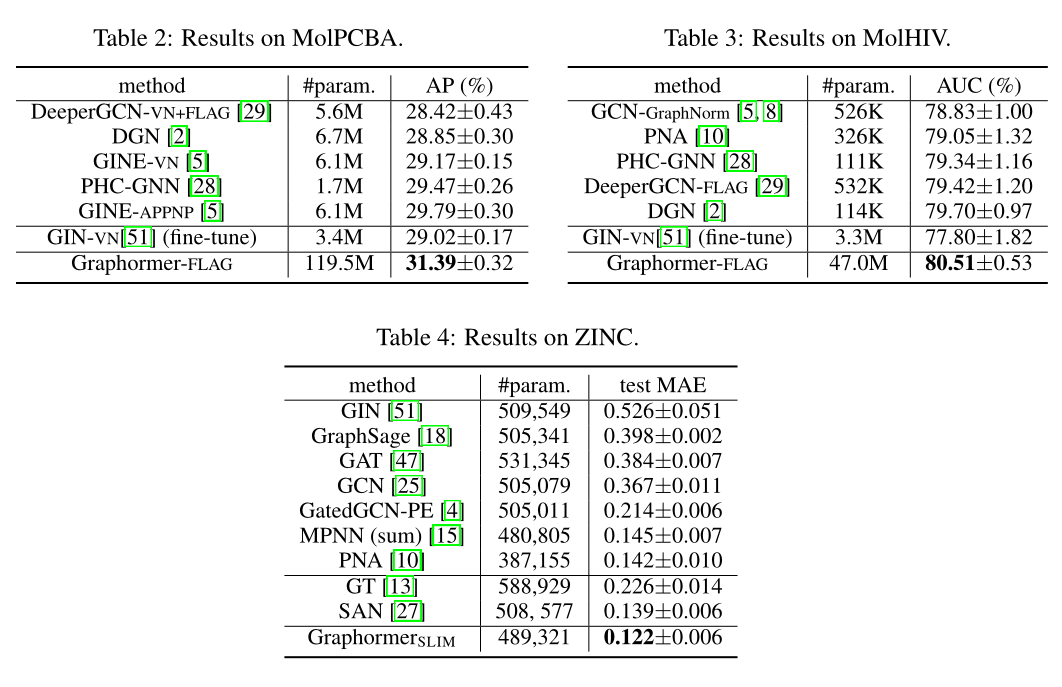
3 实验结果

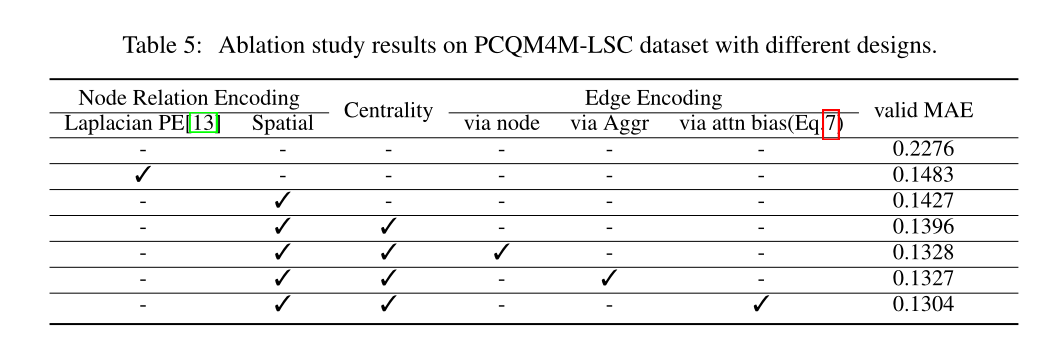
4 感想
- Transformer转移到图中最麻烦的一个问题就是空间编码,本文没有使用绝对空间编码,甚至没有显式地将空间编码表现出来,而是直接加在注意力系数中了,不得不说是个很好的思路。
- 既NLP,CV和语音处理,Transformer转到GNN的文章也渐渐多了起来,现实说明Transformer的统治力还是极其恐怖的。但是,与其他几个模型做对比就可以发现,虽然Graphormer取得了SOTA的结果,但是参数量基本都是好几翻。可能是模型过参数化太严重了,可能是通过这种归纳偏差,得到的效果基本就到顶了。无论如何,这是一个值得探讨的问题。















 543
543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









