







我们在训练单通道图像,即灰度图(如医学影像数据)时,常会使用预训练模型进行训练。
但是一般的预训练模型是以ImageNet数据集预训练的,训练的对象是三通道的彩色图片。
这需要对模型的参数进行修改,让第一个卷积层的参数从3通道卷积改成1通道卷积。
(比如下图是将三通道改成单通道后卷积层的变化)

我们知道灰度图是三通道图各个通道的加权平均,所以我们可以假设改成单通道后,将3个通道对应的卷积矩阵对应位置相加(sum)得到1通道的卷积矩阵,再去卷积灰度图,这样几乎不折损对图像的特征提取能力。
下面以Resnet50预训练模型为例来修改第1个卷积层的参数,使其能用于单通道图片的训练。
1.导出模型参数,修改参数
Pytorch中修改模型的参数,如果涉及网络结构的变化,需要先修改网络结构再赋予参数值。
即导出预训练模型参数→修改预训练模型参数→修改模型的网络结构→导回修改后的模型
from torchvision.models import resnet50
net = resnet50(pretrained=True)
print(net.conv1) # 查看第一个卷积层的结构
weights = net.state_dict() # state_dict()以 有序字典 罗列参数
print(weights.keys()) # 查看参数的key
weights['conv1.weight'].shape # 根据key取到参数,查看形状

修改模型参数
weights['conv1.weight'] = weights['conv1.weight'].sum(1, keepdim=True) # 修改第一个卷积层的参数,从3通道卷积改成1通道卷积
weights['conv1.weight'].shape # 查看修改后的形状

2.修改模型结构,导回参数
import torch.nn as nn
# 修改第一个卷积层的结构
net.conv1 = nn.Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
# 导入修改后的参数
net.load_state_dict(weights)
net
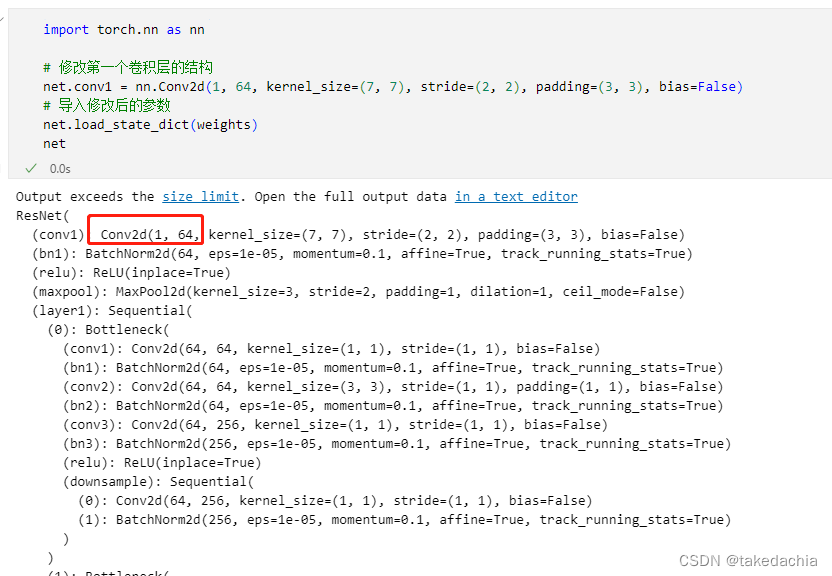
修改成功!
接下去就可以用你自己的灰度图数据集来微调这个预训练模型了。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









