






本文为《Steven M. Kay, Fundamentals of Statistical Signal Processing:Estimation Theory》一书的第3章。
上一章我们谈到什么是最小方差无偏估计,即估计一方面是无偏的(估计值的均值为真值),同时又满足最小方差准则。这一章,我们讨论无偏估计方差的一种下限,即CRLB。
文章目录
3.1 简介
在实际中,如果能够为无偏估计的方差确定一个下限,将是非常有帮助的。在最好的情况下,如果该估计对于未知参数的所有取值都能达到下限。我们就可以据此推断这个估计是MVU估计。在最坏的情况下,它可以提供用来比较无偏估计性能的基准。进一步,它也提醒我们找到方差小于下限的无偏估计是不可能的,这在信号处理可用性研究中经常是有用的。
尽管存在很多这样的方差限[1,2,3],Cramer-Rao(CRLB)限要容易确定得多。此外,该定理让我们可以立即确定达到下限的估计是否存在。如果这样的估计不存在,也不会一无所获,因为我们可以找到近似达到下限的估计,正如第7章要介绍的。由于这些原因,这里我们主要讨论CRLB。
3.2 总结
式(3.6)给出了标量参数的CRLB。如果式(3.7)条件满足,则下限可达,且很容易找到达到下限的估计。式(3.12)给出了确定CRLB的另外一种方法。对于WGN中具有一个未知参量的信号,式(3.14)给出了一种简便方法来计算下限。一般来说,即使存在 θ \theta θ的有效估计, θ \theta θ某个函数的有效估计也不一定存在(除非函数是线性的)。用式(3.20)和(3.21)可以确定向量参数的CRLB。与标量情况相似,如果式(3.25)中条件满足,则下限可达,且很容易找到达到下限的估计。对于向量参数的函数,式(3.30)给出了其下限。式(3.31)给出了多维变量高斯PDF的Fisher信息矩阵(用来确定向量CRLB)的通用公式。最后,如果数据集来自WSS高斯随机过程,式(3.34)给出了依赖于PSD的近似CRLB。它是渐近有效的,或当数据记录长度变大时可用。
3.3 估计精度考虑
在讨论CRLB定理之前,揭开哪些隐藏因素能够决定参数估计性能好坏,是值得的。由于我们所有的信息都是在观测数据及其PDF中具体表现的,因此估计精度取决于PDF一点也不奇怪。例如,如果PDF只与参数弱相关,甚至在极端情况下,完全无关,我们就没法期待估计是准确的。一般来说,PDF受未知参数的影响越大,我们的估计就越好。
观测数据的PDF,会影响观测精度。
【例3.1】依赖于未知参数的PDF
如果观测到单个样本为
x
[
0
]
=
A
+
w
[
0
]
x[0]=A+w[0]
x[0]=A+w[0]其中
w
[
0
]
∼
N
(
0
,
σ
2
)
w[0]\sim {\mathcal N}(0,\sigma^2)
w[0]∼N(0,σ2),并且想要估计
A
A
A,我们预计如果
σ
2
\sigma^2
σ2小的话,可以得到更好的估计。事实上,一个无偏估计是
A
^
=
x
[
0
]
\hat A=x[0]
A^=x[0]。方差当然就是
σ
2
\sigma^2
σ2,因此当
σ
2
\sigma^2
σ2减小时,估计精度提升。看待这个问题的另外一个角度如图3.1所示,图中给出了两种不同方差时的PDF,即
p
i
(
x
[
0
]
;
A
)
=
1
2
π
σ
i
2
exp
[
−
1
2
σ
i
2
(
x
[
0
]
−
A
)
2
]
i
=
0
,
1
(3.1)
\tag{3.1} p_i(x[0];A)=\frac{1}{\sqrt{2\pi \sigma_i^2}}\exp\left[ -\frac{1}{2\sigma_i^2}(x[0]-A)^2 \right]\quad i=0,1
pi(x[0];A)=2πσi21exp[−2σi21(x[0]−A)2]i=0,1(3.1)
在给定
x
[
0
]
x[0]
x[0]情况下,PDF与未知参数
A
A
A的关系如图3.1所示。如果
σ
1
2
<
σ
2
2
\sigma_1^2<\sigma_2^2
σ12<σ22,则我们基于
p
1
(
x
[
0
]
;
A
)
p_1(x[0];A)
p1(x[0];A)可以更准确地估计A。从图3.1我们可以理解这个结果。如果
x
[
0
]
=
3
x[0]=3
x[0]=3且
σ
1
=
1
3
\sigma_1=\frac{1}{3}
σ1=31,则如图3.1(a)所示,出现
A
>
4
A>4
A>4的可能性很小。为了看得更清楚,当
A
A
A的值给定,我们确定
x
[
0
]
x[0]
x[0]落到区间
[
x
[
0
]
−
δ
/
2
,
x
[
0
]
+
δ
/
2
]
=
[
3
−
δ
/
2
,
3
+
δ
/
2
]
[x[0]-\delta/2,x[0]+\delta/2]=[3-\delta/2,3+\delta/2]
[x[0]−δ/2,x[0]+δ/2]=[3−δ/2,3+δ/2]的概率为
P
r
{
3
−
δ
2
≤
x
[
0
]
≤
3
+
δ
2
}
=
∫
3
−
δ
2
3
+
δ
2
p
i
(
u
;
A
)
d
u
{\rm Pr}\left \{ 3-\frac{\delta}{2}\le x[0]\le 3+\frac{\delta}{2} \right\}=\int_{ 3-\frac{\delta}{2}}^{ 3+\frac{\delta}{2}} p_i(u;A)du
Pr{3−2δ≤x[0]≤3+2δ}=∫3−2δ3+2δpi(u;A)du当
δ
\delta
δ取值很小时,有概率为
p
i
(
x
[
0
]
=
3
;
A
)
δ
p_i(x[0]=3;A)\delta
pi(x[0]=3;A)δ。可以求得,
A
A
A分别为3和4时,有
p
i
(
x
[
0
]
=
3
;
A
=
3
)
δ
=
1.20
δ
p_i(x[0]=3;A=3)\delta=1.20\delta
pi(x[0]=3;A=3)δ=1.20δ和
p
i
(
x
[
0
]
=
3
;
A
=
4
)
δ
=
0.01
δ
p_i(x[0]=3;A=4)\delta=0.01\delta
pi(x[0]=3;A=4)δ=0.01δ。显然当
A
=
4
A=4
A=4时,
x
[
0
]
x[0]
x[0]落到3附近小区域的概率,与
A
=
3
A=3
A=3时相对更小,因此可以不用考虑
A
>
4
A>4
A>4的情况。可能有人会认为区间
3
±
3
σ
1
=
[
2
,
4
]
3\pm3\sigma_1=[2,4]
3±3σ1=[2,4]中A的值是可能的候选者。对于图3.1b中的PDF来说,它对于
A
A
A的依赖性更弱,这里我们的可能候选区域就要宽的多,为
[
0
,
6
]
[0,6]
[0,6]。
这个例子中,(b)中的方差更大,因而更发散,对均值的依赖性更弱,因此数据也就需要取得范围更大。如果也只有 [ 2 , 4 ] [2,4] [2,4]区域中的数据,显然会有问题。

如果把PDF看作未知参数的函数(其中
x
\bf x
x是固定的),则其被称作似然函数。图3.1中给出了两个似然函数的例子。直观来看,似然函数的“尖锐程度”决定了我们能够在多大程度上精确估计未知参数。为了量化这个概念,我们观察到,可以用似然函数在其峰值处对数的二阶导数的负值,来有效测量锐度,即对数似然函数的曲率。在【例3.1】中,我们考虑PDF的自然对数为
ln
p
(
x
[
0
]
;
A
)
=
−
ln
2
π
σ
2
−
1
2
σ
2
(
x
[
0
]
−
A
)
2
,
\ln p(x[0];A)=-\ln\sqrt{2\pi \sigma^2}-\frac{1}{2\sigma^2}(x[0]-A)^2,
lnp(x[0];A)=−ln2πσ2−2σ21(x[0]−A)2,因此一次导数为
∂
ln
p
(
x
[
0
]
;
A
)
∂
A
=
1
σ
2
(
x
[
0
]
−
A
)
,
(3.2)
\tag{3.2} \frac{\partial \ln p(x[0];A)}{\partial A}=\frac{1}{\sigma^2}(x[0]-A),
∂A∂lnp(x[0];A)=σ21(x[0]−A),(3.2)其二次导数的负值为
−
∂
2
ln
p
(
x
[
0
]
;
A
)
∂
A
2
=
1
σ
2
.
(3.3)
\tag{3.3} -\frac{\partial^2 \ln p(x[0];A)}{\partial A^2}=\frac{1}{\sigma^2}.
−∂A2∂2lnp(x[0];A)=σ21.(3.3)随着
σ
2
\sigma^2
σ2减小,曲率增大。由于我们已知估计
A
^
=
x
[
0
]
\hat A=x[0]
A^=x[0]的方差为
σ
2
\sigma^2
σ2,因此对于这个例子,有
v
a
r
(
A
^
)
=
1
−
∂
2
ln
p
(
x
[
0
]
;
A
)
∂
A
2
(3.4)
\tag{3.4} {\rm var}(\hat { A})=\frac{1}{-\frac{\partial^2 \ln p(x[0];A)}{\partial A^2}}
var(A^)=−∂A2∂2lnp(x[0];A)1(3.4)即曲率增加,方差减小。尽管在这个例子里,二次导数与
x
[
0
]
x[0]
x[0]无关,通常二次导数是与其相关的。因此,对于曲率更恰当的定义是
−
E
[
∂
2
ln
p
(
x
[
0
]
;
A
)
∂
A
2
]
,
(3.5)
\tag{3.5} -{\rm E}\left[ \frac{\partial^2 \ln p(x[0];A)}{\partial A^2}\right],
−E[∂A2∂2lnp(x[0];A)],(3.5)用来表示对数似然函数的平均曲率。关于
p
(
x
[
0
]
;
A
)
p(x[0];A)
p(x[0];A)取期望,可以得到只与
A
A
A有关的函数。期望说明了这样一个事实,依赖于
x
[
0
]
x[0]
x[0]的似然函数,本身是个随机变量。(3.5)的值越大,估计器的方差越小。
(测试数据)对数似然函数的曲率越大,则估计的方差越小。
3.4 Cramer-Rao下限
下面我们先来看【定理3.1:标量参数的CRLB】,给出它的证明(附录3A),随后看几个例子。
【定理3.1:标量参数的CRLB】假设概率密度函数满足正则条件
E
[
∂
ln
p
(
x
;
θ
)
∂
θ
]
=
0
,
{\rm E}\left[\frac{\partial \ln p({\bf x};\theta)}{\partial \theta}\right]=0,
E[∂θ∂lnp(x;θ)]=0,
例如, x [ n ] = θ + w [ n ] x[n]=\theta+w[n] x[n]=θ+w[n],其中的 N N N个样本 { x [ 1 ] , x [ 2 ] , … x [ N ] } \{x[1],x[2],\ldots x[N]\} {x[1],x[2],…x[N]},构成观测数据向量 x \bf x x,因此有概率密度函数为 p ( x ; θ ) p({\bf x};\theta) p(x;θ)。上面式子中对 p ( x ; θ ) p({\bf x};\theta) p(x;θ)求期望。
则任何无偏估计
θ
^
\hat \theta
θ^都满足
v
a
r
(
θ
^
)
≥
1
−
E
[
∂
2
ln
p
(
x
;
θ
)
∂
θ
2
]
.
(3.6)
\tag{3.6} {\rm var}(\hat \theta)\ge \frac{1}{-{\rm E}\left[\frac{\partial^2\ln p({\bf x};\theta)}{\partial \theta^2} \right]}.
var(θ^)≥−E[∂θ2∂2lnp(x;θ)]1.(3.6)进一步,当且仅当
∂
ln
p
(
x
;
θ
)
∂
θ
=
I
(
θ
)
[
g
(
x
)
−
θ
]
,
(3.7)
\tag{3.7} \frac{\partial \ln p({\bf x};\theta) }{\partial \theta}=I(\theta)[g({\bf x})-\theta],
∂θ∂lnp(x;θ)=I(θ)[g(x)−θ],(3.7)有可能找到在所有
θ
\theta
θ值上达到(3.6)的界的无偏估计,这里
g
(
⋅
)
g(\cdot)
g(⋅)和
I
(
⋅
)
I(\cdot)
I(⋅)为某个函数。此时,该估计
θ
^
=
g
(
x
)
\hat \theta=g({\bf x})
θ^=g(x)为MVU估计,最小方差为
1
/
I
(
θ
)
1/I(\theta)
1/I(θ)。
【例3.2】例3.1的CRLB。
对于例3.1,从(3.3)和(3.6),可以得到
v
a
r
(
A
^
)
≥
σ
2
,
f
o
r
a
l
l
A
{\rm var}(\hat A)\ge \sigma^2,\quad {\rm for \ all \ A}
var(A^)≥σ2,for all A
这里 x [ 0 ] = A + w [ 0 ] x[0]=A+w[0] x[0]=A+w[0],且 w [ 0 ] ∼ N ( 0 , σ 2 ) w[0]\sim {\mathcal N}(0,\sigma^2) w[0]∼N(0,σ2),无偏估计是 A ^ = x [ 0 ] \hat A=x[0] A^=x[0]。
因此,即使对于单个的
A
A
A的取值,也不存在方差小于
σ
2
\sigma^2
σ2的无偏估计。然而事实上我们知道,如果
A
^
=
x
[
0
]
\hat A=x[0]
A^=x[0],那么对于所有的
A
A
A,都有
v
a
r
(
A
^
)
=
σ
2
{\rm var}(\hat A)=\sigma^2
var(A^)=σ2。由于
x
[
0
]
x[0]
x[0]是无偏的且达到CRLB,因此它一定是MVU估计。Had we been unable to guess that
x
[
0
]
x[0]
x[0] would be a good estimator, we could have used (3.7). 从(3.2)和(3.7),如果我们令
θ
=
A
I
(
θ
)
=
1
σ
2
g
(
x
[
0
]
)
=
x
[
0
]
\begin{aligned} \theta&=A\\ I(\theta)&=\frac{1}{\sigma^2}\\ g(x[0])&=x[0] \end{aligned}
θI(θ)g(x[0])=A=σ21=x[0]则(3.7)成立。因此
A
^
=
g
(
x
[
0
]
)
=
x
[
0
]
\hat A=g(x[0])=x[0]
A^=g(x[0])=x[0]为MVU估计。此外,注意到KaTeX parse error: Undefined control sequence: \I at position 29: …t A)=\sigma^2=1\̲I̲(\theta),根据(3.6),我们一定有
I
(
θ
)
=
−
E
[
∂
2
ln
p
(
x
;
θ
)
∂
θ
2
]
.
I(\theta)=-{\rm E}\left[\frac{\partial^2\ln p({\bf x};\theta)}{\partial \theta^2}\right].
I(θ)=−E[∂θ2∂2lnp(x;θ)].下个例子之后我们再回来讨论这个问题。还可参见Problem 3.2,如何将其推广到非高斯的情况。
【例3.3】白高斯噪声中的直流电平
将例3.1进行推广,考虑多观测量的情况
x
[
n
]
=
A
+
w
[
n
]
,
n
=
0
,
1
,
…
,
N
−
1
x[n]=A+w[n],\qquad n=0,1,\ldots,N-1
x[n]=A+w[n],n=0,1,…,N−1其中
w
[
n
]
∼
N
(
0
,
σ
2
)
w[n]\sim {\mathcal N}(0,\sigma^2)
w[n]∼N(0,σ2)。为了决定
A
A
A的CRLB,有
p
(
x
;
A
)
=
∏
n
=
0
N
−
1
1
2
π
σ
2
exp
[
−
1
2
σ
2
(
x
[
n
]
−
A
)
2
]
=
1
(
2
π
σ
2
)
N
2
exp
[
−
1
2
σ
2
∑
n
=
0
N
−
1
(
x
[
n
]
−
A
)
2
]
\begin{aligned} p({\bf x};A)&=\prod_{n=0}^{N-1}\frac{1}{\sqrt{2\pi \sigma^2}}\exp\left[-\frac{1}{2\sigma^2}(x[n]-A)^2\right]\\ &=\frac{1}{(2\pi \sigma^2)^{\frac{N}{2}}}\exp \left[-\frac{1}{2\sigma^2}\sum_{n=0}^{N-1}(x[n]-A)^2\right] \end{aligned}
p(x;A)=n=0∏N−12πσ21exp[−2σ21(x[n]−A)2]=(2πσ2)2N1exp[−2σ21n=0∑N−1(x[n]−A)2]取一次导数,得到
∂
ln
p
(
x
;
θ
)
∂
θ
=
∂
∂
A
[
−
ln
[
(
2
π
σ
2
)
N
2
]
−
1
2
σ
2
∑
n
=
0
N
−
1
(
x
[
n
]
−
A
)
2
]
=
1
σ
2
∑
n
=
0
N
−
1
(
x
[
n
]
−
A
)
=
N
σ
2
(
x
ˉ
−
A
)
(3.8)
\tag{3.8}\begin{aligned} \frac{\partial \ln p({\bf x};\theta)}{\partial \theta}&=\frac{\partial}{\partial A}\left[-\ln [(2\pi \sigma^2)^{\frac{N}{2}} ]-\frac{1}{2\sigma^2}\sum_{n=0}^{N-1}(x[n]-A)^2\right]\\ &=\frac{1}{\sigma^2}\sum_{n=0}^{N-1}(x[n]-A)\\ &=\frac{N}{\sigma^2}(\bar x-A) \end{aligned}
∂θ∂lnp(x;θ)=∂A∂[−ln[(2πσ2)2N]−2σ21n=0∑N−1(x[n]−A)2]=σ21n=0∑N−1(x[n]−A)=σ2N(xˉ−A)(3.8)这里的
x
ˉ
\bar x
xˉ为
x
x
x的样本平均。再求导,得到
∂
2
ln
p
(
x
;
A
)
∂
A
2
=
−
N
σ
2
\frac{\partial^2 \ln p({\bf x};A)}{\partial A^2}=-\frac{N}{\sigma^2}
∂A2∂2lnp(x;A)=−σ2N为常数,从(3.6)得到
v
a
r
(
A
^
)
≥
σ
2
N
(3.9)
\tag{3.9} {\rm var}(\hat A)\ge \frac{\sigma^2}{N}
var(A^)≥Nσ2(3.9)为CRLB。另外,通过比较(3.7)和(3.8),我们可以看到样本平均估计达到CRLB界,因此一定是MVU估计。另外,最小方差再一次是由(3.8)中的常数
N
/
σ
2
N/\sigma^2
N/σ2的倒数得到的(这个例子的变形参见Problem 3.3-3.5)。
下面我们证明,当达到CRLB时,有
v
a
r
(
θ
^
)
=
1
I
(
θ
)
,
{\rm var}(\hat \theta)=\frac{1}{I(\theta)},
var(θ^)=I(θ)1,其中,
I
(
θ
)
=
−
E
[
∂
2
ln
p
(
x
;
θ
)
∂
θ
2
]
.
I(\theta)=-{\rm E}\left[\frac{\partial^2 \ln p({\bf x};\theta)}{\partial \theta^2} \right].
I(θ)=−E[∂θ2∂2lnp(x;θ)].从(3.6)和(3.7),可以得到
v
a
r
(
θ
^
)
=
1
−
E
[
∂
2
ln
p
(
x
;
θ
)
∂
θ
2
]
{\rm var}(\hat \theta)=\frac{1}{-{\rm E}\left[\frac{\partial^2 \ln p({\bf x};\theta)}{\partial \theta^2} \right]}
var(θ^)=−E[∂θ2∂2lnp(x;θ)]1以及
∂
ln
p
(
x
;
θ
)
∂
θ
=
I
(
θ
)
(
θ
^
−
θ
)
.
\frac{\partial \ln p({\bf x};\theta)}{\partial \theta}=I(\theta)(\hat \theta-\theta).
∂θ∂lnp(x;θ)=I(θ)(θ^−θ).对后者进行微分,可以得到
∂
2
ln
p
(
x
;
θ
)
∂
θ
2
=
∂
I
(
θ
)
∂
θ
(
θ
^
−
θ
)
−
I
(
θ
)
\frac{\partial^2 \ln p({\bf x};\theta)}{\partial \theta^2}=\frac{\partial I(\theta)}{\partial \theta}(\hat \theta-\theta)-I(\theta)
∂θ2∂2lnp(x;θ)=∂θ∂I(θ)(θ^−θ)−I(θ)对其求统计平均后取负值
−
E
[
∂
2
ln
p
(
x
;
θ
)
∂
θ
2
]
=
−
∂
I
(
θ
)
∂
θ
[
E
(
θ
^
)
−
θ
]
−
I
(
θ
)
+
I
(
θ
)
=
I
(
θ
)
-{\rm E}\left[\frac{\partial^2 \ln p({\bf x};\theta)}{\partial \theta^2} \right]=-\frac{\partial I(\theta)}{\partial \theta}[{\rm E}(\hat \theta)-\theta]-I(\theta)+I(\theta)=I(\theta)
−E[∂θ2∂2lnp(x;θ)]=−∂θ∂I(θ)[E(θ^)−θ]−I(θ)+I(θ)=I(θ)因此,可以得到
v
a
r
(
θ
^
)
=
1
I
(
θ
)
,
{\rm var}(\hat \theta)=\frac{1}{I(\theta)},
var(θ^)=I(θ)1,下面的例子中,我们可以看到CRLB并非总能达到。
【例3.4】相位估计
现在我们对WGN中余弦信号的相位
ϕ
\phi
ϕ进行估计,即
x
(
n
)
=
A
cos
(
2
π
f
0
n
+
ϕ
)
+
w
[
n
]
n
=
0
,
1
,
…
,
N
−
1.
x(n)=A\cos(2\pi f_0n+\phi)+w[n]\qquad n=0,1,\ldots,N-1.
x(n)=Acos(2πf0n+ϕ)+w[n]n=0,1,…,N−1.这里假定幅度
A
A
A和频率
f
0
f_0
f0已知,因此PDF为
p
(
x
;
ϕ
)
=
1
(
2
π
σ
2
)
N
2
exp
[
−
1
2
σ
2
∑
n
=
0
N
−
1
(
x
[
n
]
−
A
cos
(
2
π
f
0
n
+
ϕ
)
)
2
]
\begin{aligned} p({\bf x};\phi)&=\frac{1}{(2\pi \sigma^2)^{\frac{N}{2}}}\exp \left[-\frac{1}{2\sigma^2}\sum_{n=0}^{N-1}(x[n]-A\cos(2\pi f_0n+\phi))^2\right] \end{aligned}
p(x;ϕ)=(2πσ2)2N1exp[−2σ21n=0∑N−1(x[n]−Acos(2πf0n+ϕ))2]对似然函数求微分,得到
∂
ln
p
(
x
;
ϕ
)
∂
ϕ
=
−
1
σ
2
∑
n
=
0
N
−
1
[
x
[
n
]
−
A
cos
(
2
π
f
0
n
+
ϕ
)
]
A
sin
(
2
π
f
0
n
+
ϕ
)
=
−
A
σ
2
∑
n
=
0
N
−
1
[
x
[
n
]
sin
(
2
π
f
0
n
+
ϕ
)
−
A
2
sin
(
4
π
f
0
n
+
2
ϕ
)
]
\begin{aligned} \frac{\partial \ln p({\bf x};\phi)}{\partial \phi}&=-\frac{1}{\sigma^2}\sum_{n=0}^{N-1}[x[n]-A\cos(2\pi f_0n+\phi)]A\sin(2\pi f_0n+\phi)\\ &=-\frac{A}{\sigma^2}\sum_{n=0}^{N-1}[x[n]\sin(2\pi f_0n+\phi)-\frac{A}{2}\sin(4\pi f_0n+2\phi)]\\ \end{aligned}
∂ϕ∂lnp(x;ϕ)=−σ21n=0∑N−1[x[n]−Acos(2πf0n+ϕ)]Asin(2πf0n+ϕ)=−σ2An=0∑N−1[x[n]sin(2πf0n+ϕ)−2Asin(4πf0n+2ϕ)]以及
∂
2
ln
p
(
x
;
ϕ
)
∂
ϕ
2
=
−
A
σ
2
∑
n
=
0
N
−
1
[
x
[
n
]
cos
(
2
π
f
0
n
+
ϕ
)
−
A
cos
(
4
π
f
0
n
+
2
ϕ
)
]
\begin{aligned} \frac{\partial^2 \ln p({\bf x};\phi)}{\partial \phi^2}&=-\frac{A}{\sigma^2}\sum_{n=0}^{N-1}[x[n]\cos(2\pi f_0n+\phi)-A\cos(4\pi f_0n+2\phi)]\\ \end{aligned}
∂ϕ2∂2lnp(x;ϕ)=−σ2An=0∑N−1[x[n]cos(2πf0n+ϕ)−Acos(4πf0n+2ϕ)]对其求统计平均并取负值,可以得到
−
E
[
∂
2
ln
p
(
x
;
θ
)
∂
θ
2
]
=
A
σ
2
∑
n
=
0
N
−
1
[
A
cos
2
(
2
π
f
0
n
+
ϕ
)
−
A
cos
(
4
π
f
0
n
+
2
ϕ
)
]
=
A
2
σ
2
∑
n
=
0
N
−
1
[
1
2
+
1
2
cos
(
4
π
f
0
n
+
2
ϕ
)
−
cos
(
4
π
f
0
n
+
2
ϕ
)
]
≈
N
A
2
2
σ
2
\begin{aligned} -{\rm E}\left[\frac{\partial^2 \ln p({\bf x};\theta)}{\partial \theta^2} \right]&=\frac{A}{\sigma^2}\sum_{n=0}^{N-1}[A\cos^2(2\pi f_0n+\phi)-A\cos(4\pi f_0n+2\phi)]\\ &=\frac{A^2}{\sigma^2}\sum_{n=0}^{N-1}[\frac{1}{2}+\frac{1}{2}\cos(4\pi f_0n+2\phi)-\cos(4\pi f_0n+2\phi)]\\ &\approx \frac{NA^2}{2\sigma^2} \end{aligned}
−E[∂θ2∂2lnp(x;θ)]=σ2An=0∑N−1[Acos2(2πf0n+ϕ)−Acos(4πf0n+2ϕ)]=σ2A2n=0∑N−1[21+21cos(4πf0n+2ϕ)−cos(4πf0n+2ϕ)]≈2σ2NA2由于当
f
0
f_0
f0不接近等于0或者
1
/
2
1/2
1/2(参见Problme 3.7),有
1
N
∑
n
=
0
N
−
1
cos
(
4
π
f
0
n
+
2
ϕ
)
≈
0
\frac{1}{N}\sum_{n=0}^{N-1}\cos(4\pi f_0n+2\phi)\approx 0
N1n=0∑N−1cos(4πf0n+2ϕ)≈0因此,可以得到
v
a
r
(
ϕ
^
)
≥
2
σ
2
N
A
2
.
{\rm var}(\hat \phi)\ge \frac{2\sigma^2}{NA^2}.
var(ϕ^)≥NA22σ2.在这个例子中,让界成立的条件无法满足。因此,不存在能够达到CRLB的无偏相位估计。然而,仍然可能存在MVU估计,只是我们不知如何确定MVU估计是否存在,以及如果存在的话如何找到。第5章中的充分统计会帮助我们回答这些问题。
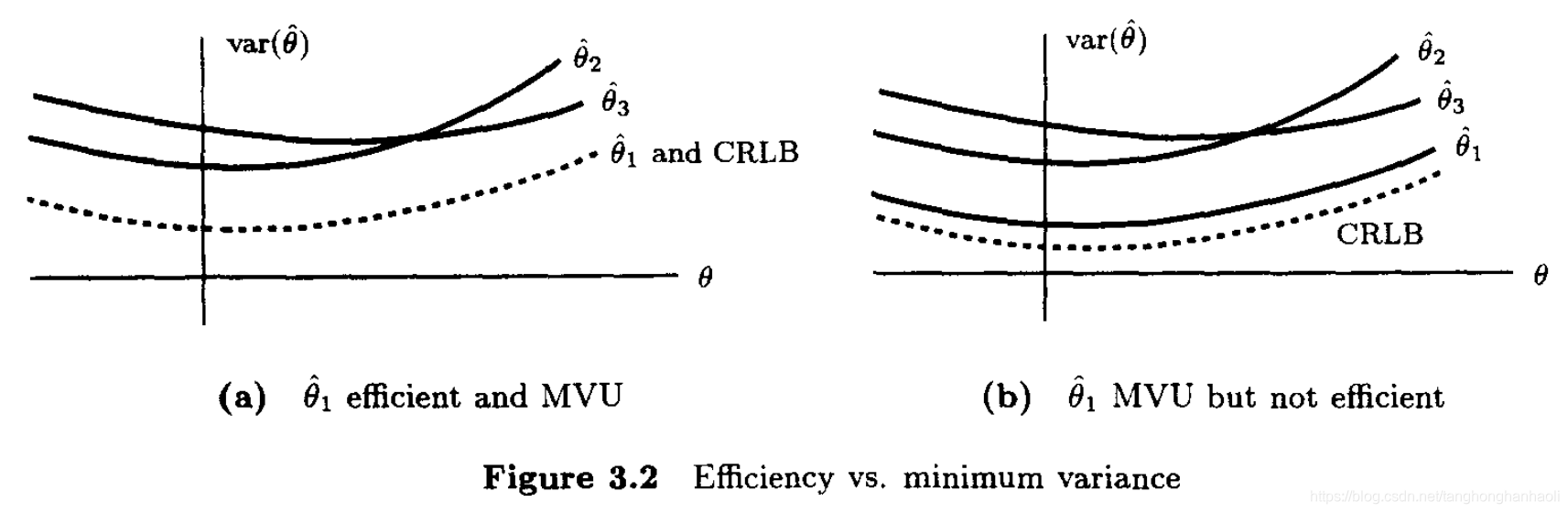
如例3.3中的样本均值估计所示,一个无偏且达到CRLB的估计被认为是有效的,因为它有效地利用了数据。MUV估计可能是,也可能不是有效(efficient)的。例如,图3.2给出了所有可能估计的方差(为了方便说明,给出了三种无偏估计)。在图3.2a中,由于达到了CRLB,因此
θ
^
1
\hat \theta_1
θ^1是有效的,因此它也是MVU估计。然而,在图3.2b中,
θ
^
1
\hat \theta_1
θ^1没有达到CRLB,因此不是efficient。然而由于它的方差小于其它估计,因此依然是MVU。
(3.6)给出的CRLB也可以用稍微有所不同的方式表达。尽管(3.6)用于评价更方便,另外一种表达在进行理论研究的时候更有用。根据下面等式(参见附录3A)
E
[
(
∂
ln
p
(
x
;
θ
)
∂
θ
)
2
]
=
−
E
[
∂
2
ln
p
(
x
;
θ
)
∂
θ
2
]
,
(3.11)
\tag{3.11} {\rm E}\left[\left(\frac{\partial \ln p({\bf x};\theta)}{\partial \theta}\right)^2\right]=-{\rm E}\left[\frac{\partial^2 \ln p({\bf x};\theta)}{\partial \theta^2}\right],
E[(∂θ∂lnp(x;θ))2]=−E[∂θ2∂2lnp(x;θ)],(3.11)因此
v
a
r
(
θ
^
)
≥
1
E
[
(
∂
ln
p
(
x
;
θ
)
∂
θ
)
2
]
.
(3.12)
\tag{3.12} {\rm var}(\hat \theta)\ge \frac{1}{{\rm E}\left[\left(\frac{\partial\ln p({\bf x};\theta)}{\partial \theta}\right)^2 \right]}.
var(θ^)≥E[(∂θ∂lnp(x;θ))2]1.(3.12)(参见问题3.8)。
3.5 WGN中信号的一般CRLB
3.6 参数的变换
3.7 扩展到矢量参数
3.8 矢量参数变换的CRLB
【附录3A】标量参数CRLB的推导
对于标量参数
α
=
g
(
θ
)
\alpha=g(\theta)
α=g(θ),其PDF由
θ
\theta
θ参数化。我们考虑所有的无偏估计
α
^
\hat \alpha
α^,即
E
(
α
^
)
=
α
=
g
(
θ
)
,
E(\hat \alpha)=\alpha=g(\theta),
E(α^)=α=g(θ),或
∫
α
^
p
(
x
;
θ
)
d
x
=
g
(
θ
)
(3A.1)
\tag{3A.1} \int\hat \alpha p({\bf x};\theta)d{\bf x}=g(\theta)
∫α^p(x;θ)dx=g(θ)(3A.1)在求导之前,我们先假定正定条件成立,即
E
[
∂
ln
p
(
x
;
θ
)
∂
θ
]
=
0
,
(3A.2)
\tag{3A.2} {\rm E}\left[\frac{\partial \ln p({\bf x};\theta)}{\partial \theta}\right]=0,
E[∂θ∂lnp(x;θ)]=0,(3A.2)
注意到
∫
∂
ln
p
(
x
;
θ
)
∂
θ
p
(
x
;
θ
)
d
x
=
∫
∂
p
(
x
;
θ
)
∂
θ
d
x
=
∂
∂
θ
∫
p
(
x
;
θ
)
d
x
=
∂
1
∂
θ
=
0
\begin{aligned} \int \frac{\partial \ln p({\bf x};\theta)}{\partial \theta} p({\bf x};\theta)d{\bf x}&=\int \frac{\partial p({\bf x};\theta)}{\partial \theta}d{\bf x}\\ &= \frac{\partial }{\partial \theta}\int p({\bf x};\theta)d{\bf x}\\ &=\frac{\partial 1}{\partial \theta}\\ &=0 \end{aligned}
∫∂θ∂lnp(x;θ)p(x;θ)dx=∫∂θ∂p(x;θ)dx=∂θ∂∫p(x;θ)dx=∂θ∂1=0因此,我们可以得出结论,如果微分和积分的顺序可以交换,那么正则条件就成立。通常情况下这是成立的,除非如Problem 3.1中,PDF的非零区域与未知有关参数有关。
下面将(3A.1)的两边同时关于
θ
\theta
θ取导,并交换偏导与积分的顺序,可以得到
∫
α
^
∂
p
(
x
;
θ
)
∂
θ
d
x
=
∂
g
(
θ
)
∂
θ
\int \hat \alpha \frac{\partial p({\bf x};\theta)}{\partial \theta}d{\bf x}=\frac{\partial g(\theta)}{\partial \theta}
∫α^∂θ∂p(x;θ)dx=∂θ∂g(θ)或者
∫
∂
ln
p
(
x
;
θ
)
∂
θ
p
(
x
;
θ
)
d
x
=
∫
∂
p
(
x
;
θ
)
∂
θ
d
x
=
∂
∂
θ
∫
p
(
x
;
θ
)
d
x
=
∂
1
∂
θ
=
0
\begin{aligned} \int \frac{\partial \ln p({\bf x};\theta)}{\partial \theta} p({\bf x};\theta)d{\bf x}&=\int \frac{\partial p({\bf x};\theta)}{\partial \theta}d{\bf x}\\ &= \frac{\partial }{\partial \theta}\int p({\bf x};\theta)d{\bf x}\\ &=\frac{\partial 1}{\partial \theta}\\ &=0 \end{aligned}
∫∂θ∂lnp(x;θ)p(x;θ)dx=∫∂θ∂p(x;θ)dx=∂θ∂∫p(x;θ)dx=∂θ∂1=0因此,我们可得结论,如果微分和积分的顺序可以互换,则正则条件就能够满足。通常情况下都是如此,除非如Problem 3.1中,PDF的非零域与未知参数有关。
下面把(3A.1)的等号两边都关于
θ
\theta
θ求导,并交换偏导与积分的顺序,可以得到
∫
α
^
∂
p
(
x
;
θ
)
∂
θ
d
x
=
∂
g
(
θ
)
∂
θ
\int \hat \alpha\frac{\partial p({\bf x};\theta)}{\partial \theta}d{\bf x}=\frac{\partial g(\theta)}{\partial \theta}
∫α^∂θ∂p(x;θ)dx=∂θ∂g(θ)或者
∫
α
^
∂
ln
p
(
x
;
θ
)
∂
θ
p
(
x
;
θ
)
d
x
=
∂
g
(
θ
)
∂
θ
(3A.3)
\tag{3A.3} \int \hat \alpha\frac{\partial \ln p({\bf x};\theta)}{\partial \theta} p({\bf x};\theta)d{\bf x}=\frac{\partial g(\theta)}{\partial \theta}
∫α^∂θ∂lnp(x;θ)p(x;θ)dx=∂θ∂g(θ)(3A.3)利用正则条件,由于
∫
α
∂
ln
p
(
x
;
θ
)
∂
θ
p
(
x
;
θ
)
d
x
=
α
E
[
∂
ln
p
(
x
;
θ
)
∂
θ
]
=
0
,
\int \alpha\frac{\partial \ln p({\bf x};\theta)}{\partial \theta} p({\bf x};\theta)d{\bf x}=\alpha{\rm E}\left[\frac{\partial \ln p({\bf x};\theta)}{\partial \theta} \right]=0,
∫α∂θ∂lnp(x;θ)p(x;θ)dx=αE[∂θ∂lnp(x;θ)]=0,则有
∫
(
α
^
−
α
)
∂
ln
p
(
x
;
θ
)
∂
θ
p
(
x
;
θ
)
d
x
=
∂
g
(
θ
)
∂
θ
.
(3A.4)
\tag{3A.4} \int (\hat \alpha-\alpha)\frac{\partial \ln p({\bf x};\theta)}{\partial \theta} p({\bf x};\theta)d{\bf x}=\frac{\partial g(\theta)}{\partial \theta}.
∫(α^−α)∂θ∂lnp(x;θ)p(x;θ)dx=∂θ∂g(θ).(3A.4)下面我们利用Cauchy-Schwarz不等式
[
∫
w
(
x
)
g
(
x
)
h
(
x
)
d
x
]
2
≤
∫
w
(
x
)
g
2
(
x
)
d
x
∫
w
(
x
)
h
2
(
x
)
d
x
,
(3A.5)
\tag{3A.5} \left[\int w(x)g(x)h(x)dx\right]^2\le \int w(x)g^2(x)dx\int w(x)h^2(x)dx,
[∫w(x)g(x)h(x)dx]2≤∫w(x)g2(x)dx∫w(x)h2(x)dx,(3A.5)当且仅当
g
(
x
)
=
c
h
(
x
)
g(x)=ch(x)
g(x)=ch(x)的时候,上式中的等号成立,这里
c
c
c为与
x
x
x独立的常数,
g
g
g和
h
h
h为任意函数,而对于所有
x
x
x,均有
w
(
x
)
≥
0
w(x)\ge 0
w(x)≥0。现在令
w
(
x
)
=
p
(
x
;
θ
)
g
(
x
)
=
α
^
−
α
h
(
x
)
=
∂
ln
p
(
x
;
θ
)
∂
θ
\begin{aligned} w({\bf x})&=p({\bf x};\theta)\\ g(\bf x)&=\hat\alpha-\alpha\\ h(\bf x)&=\frac{\partial \ln p({\bf x};\theta)}{\partial \theta} \end{aligned}
w(x)g(x)h(x)=p(x;θ)=α^−α=∂θ∂lnp(x;θ)并将柯西-施瓦茨不等式用于(3A.4),可以得到
(
∂
g
(
θ
)
∂
θ
)
2
≤
∫
(
α
^
−
α
)
2
p
(
x
;
θ
)
d
x
∫
(
∂
ln
p
(
x
;
θ
)
∂
θ
)
2
p
(
x
;
θ
)
d
x
\left(\frac{\partial g(\theta)}{\partial \theta}\right)^2\le \int(\hat \alpha-\alpha)^2p({\bf x};\theta)d{\bf x\int}\left(\frac{\partial \ln p({\bf x};\theta)}{\partial \theta}\right)^2p({\bf x};\theta)d{\bf x}
(∂θ∂g(θ))2≤∫(α^−α)2p(x;θ)dx∫(∂θ∂lnp(x;θ))2p(x;θ)dx或者
v
a
r
(
α
^
)
≥
(
∂
g
(
θ
)
∂
θ
)
2
E
[
(
∂
ln
p
(
x
;
θ
)
∂
θ
)
2
]
{\rm var}(\hat \alpha)\ge \frac{\left(\frac{\partial g(\theta)}{\partial \theta}\right)^2}{{\rm E}\left[\left(\frac{\partial \ln p({\bf x};\theta)}{\partial \theta}\right)^2\right]}
var(α^)≥E[(∂θ∂lnp(x;θ))2](∂θ∂g(θ))2
注意到由于
E
[
(
∂
ln
p
(
x
;
θ
)
∂
θ
)
2
]
=
−
E
[
∂
2
ln
p
(
x
;
θ
)
∂
θ
2
]
,
{\rm E}\left[\left(\frac{\partial \ln p({\bf x};\theta)}{\partial \theta}\right)^2\right]=-{\rm E}\left[\frac{\partial^2 \ln p({\bf x};\theta)}{\partial \theta^2}\right],
E[(∂θ∂lnp(x;θ))2]=−E[∂θ2∂2lnp(x;θ)],
上式证明如下:
∫ ∂ ln p ( x ; θ ) ∂ θ p ( x ; θ ) d x = 0 ∂ ∂ θ ∫ ∂ ln p ( x ; θ ) ∂ θ p ( x ; θ ) d x = 0 ∫ [ ∂ 2 ln p ( x ; θ ) ∂ θ 2 p ( x ; θ ) + ∂ ln p ( x ; θ ) ∂ θ ∂ p ( x ; θ ) ∂ θ ] d x = 0 \begin{aligned} \int \frac{\partial \ln p({\bf x};\theta)}{\partial \theta} p({\bf x};\theta)d{\bf x}&=0\\ \frac{\partial}{\partial \theta}\int \frac{\partial \ln p({\bf x};\theta)}{\partial \theta} p({\bf x};\theta)d{\bf x}&=0\\ \int \left[ \frac{\partial ^2\ln p({\bf x};\theta)}{\partial \theta^2} p({\bf x};\theta)+ \frac{\partial \ln p({\bf x};\theta)}{\partial \theta} \frac{\partial p({\bf x};\theta)}{\partial \theta}\right]d{\bf x}&=0\\ \end{aligned} ∫∂θ∂lnp(x;θ)p(x;θ)dx∂θ∂∫∂θ∂lnp(x;θ)p(x;θ)dx∫[∂θ2∂2lnp(x;θ)p(x;θ)+∂θ∂lnp(x;θ)∂θ∂p(x;θ)]dx=0=0=0
因此有
v
a
r
(
α
^
)
≥
(
∂
g
(
θ
)
∂
θ
)
2
−
E
[
∂
2
ln
p
(
x
;
θ
)
∂
θ
2
]
,
{\rm var}(\hat \alpha)\ge \frac{\left(\frac{\partial g(\theta)}{\partial \theta}\right)^2}{-{\rm E}\left[\frac{\partial^2 \ln p({\bf x};\theta)}{\partial \theta^2}\right]},
var(α^)≥−E[∂θ2∂2lnp(x;θ)](∂θ∂g(θ))2,此式为(3.16)。如果
α
=
g
(
θ
)
=
θ
\alpha=g(\theta)=\theta
α=g(θ)=θ,我们可以得到(3.6)。














 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









