









测试了一下分别用cpu,gpu,gpu+cudnn跑CNN,看看分别会用多少时间。
直接看测试结果
1.运行Dogs vs Cats例子
| 使用配置情况 | cpu | gpu | gpu+cuDNN5.0 | gpu+cuDNN5.1 |
|---|---|---|---|---|
| 一个epoch耗时 | 526s | 41s | 38s | 38s |
gpu比cpu快了12倍,gpu+cudnn比gpu快了0.1倍
2.运行mnist例子
| 使用配置情况 | cpu | gpu | gpu+cuDNN5.0 | gpu+cuDNN5.1 |
|---|---|---|---|---|
| 一个epoch耗时 | 58s | 18s | 9s | 9s |
gpu比cpu快了3倍,gpu+cudnn比gpu快了1倍
差距还挺大,可能跟程序有关吧
说明
笔记本配置:i5-3210m+GT640M+8G内存。
实验图片下载地址:kaggle:Dogs vs. Cats
关于源码和图片层次结构的说明:
This script goes along the blog post
"Building powerful image classification models using very little data"
from blog.keras.io.
It uses data that can be downloaded at:
https://www.kaggle.com/c/dogs-vs-cats/data
In our setup, we:
- created a data/ folder
- created train/ and validation/ subfolders inside data/
- created cats/ and dogs/ subfolders inside train/ and validation/
- put the cat pictures index 0-999 in data/train/cats
- put the cat pictures index 1000-1400 in data/validation/cats
- put the dogs pictures index 12500-13499 in data/train/dogs
- put the dog pictures index 13500-13900 in data/validation/dogs
So that we have 1000 training examples for each class, and 400 validation examples for each class.
In summary, this is our directory structure:
data/
train/
dogs/
dog001.jpg
dog002.jpg
...
cats/
cat001.jpg
cat002.jpg
...
validation/
dogs/
dog001.jpg
dog002.jpg
...
cats/
cat001.jpg
cat002.jpg
...
cnn程序源自这里, 貌似需要翻墙,这里有个翻译后的中文地址面向小数据集构建图像分类模型。
直接贴源码:
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
# dimensions of our images.
img_width, img_height = 150, 150
train_data_dir = 'data/train'
validation_data_dir = 'data/validation'
nb_train_samples = 2000
nb_validation_samples = 800
nb_epoch = 50
model = Sequential()
model.add(Convolution2D(32, 3, 3, input_shape=(3, img_width, img_height)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# this is the augmentation configuration we will use for testing:
# only rescaling
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=32,
class_mode='binary')
model.fit_generator(
train_generator,
samples_per_epoch=nb_train_samples,
nb_epoch=nb_epoch,
validation_data=validation_generator,
nb_val_samples=nb_validation_samples)
model.save_weights('first_try.h5')下面是具体的结果和使用教程:
1.CPU
装完keras后跑例子就直接用的cpu了。
.theanorc.txt配置文件里设为cpu。
.theanorc.txt文件在C:\Users\tang下面(tang是我的电脑名字,你找你的电脑名字就行)。
如没有该文件就手动创建一个。
内容:
[global]
openmp = False
device = cpu
floatX = float32
allow_input_downcast=True
[blas]
ldflags =
[gcc]
cxxflags = -IC:\Anaconda2\MinGW
[nvcc]
flags = -LC:\Anaconda2\libs
compiler_bindir = C:\Program Files (x86)\Microsoft Visual Studio 11.0\VC\bin
fastmath = True
flags = -arch=sm_30运行结果:
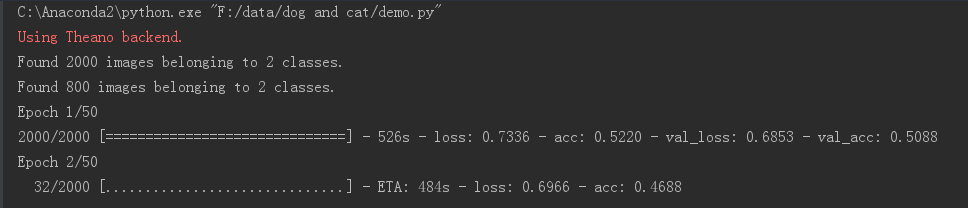
2.GPU
要用GPU加速的话,要安装CUDA,安装过程参考Keras安装与配置指南(cpu+gpu+cudnn)。
提醒:在安装cuda前,最好先把独显显卡驱动卸载,不然很容易失败。
安装完cuda后,把.theanorc.txt配置文件里的
device = cpu改为
device = gpu就行了,运行结果:
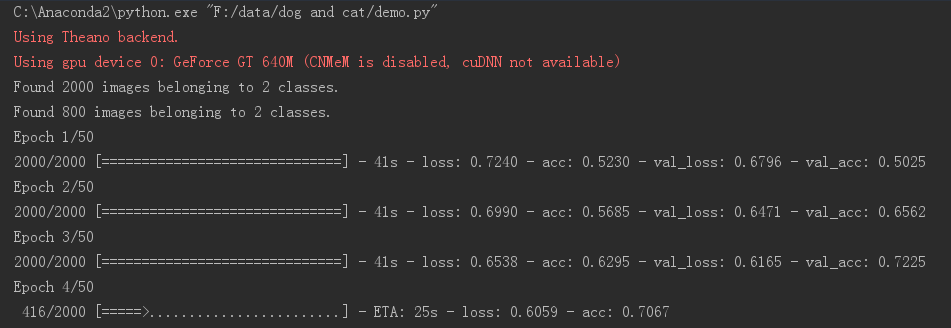
可以看到红色字体显示出了显卡信息,并且运行速度提升了12倍左右。
3.GPU+cuDNN
直接去这里(Nvida官网)下载就行,不过得申请个账号。看到cuDNN有5.0和5.1版本,就都试了一下。
使用方法
第一步:下载完cuDNN后,把压缩包里的bin、lib、include文件夹拷贝到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5下面,覆盖原文件夹即可。
提醒:覆盖前,备份原本的文件是个好习惯,以防意外发生
第二步:修改.theanorc.txt配置文件。
在device = gpu下面添加一句optimizer_including=cudnn就行了。
即由
[global]
openmp = False
device = gpu
floatX = float32
allow_input_downcast=True
[blas]
ldflags =
[gcc]
cxxflags = -IC:\Anaconda2\MinGW
[nvcc]
flags = -LC:\Anaconda2\libs
compiler_bindir = C:\Program Files (x86)\Microsoft Visual Studio 11.0\VC\bin
fastmath = True
flags = -arch=sm_30变为
[global]
openmp = False
device = gpu
optimizer_including=cudnn
floatX = float32
allow_input_downcast=True
[blas]
ldflags =
[gcc]
cxxflags = -IC:\Anaconda2\MinGW
[nvcc]
flags = -LC:\Anaconda2\libs
compiler_bindir = C:\Program Files (x86)\Microsoft Visual Studio 11.0\VC\bin
fastmath = True
flags = -arch=sm_30保存文件,直接运行程序即可。
3.1cuDNN5.1版本结果
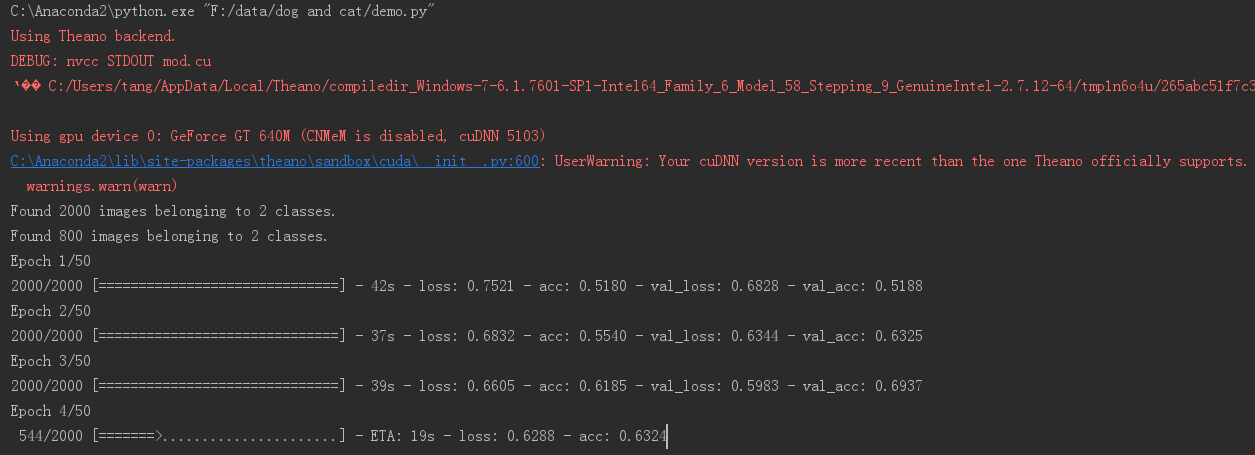
可以看到提示版本太新,可能会发生意外,如果有问题请换回5.0版本。暂时测试的没什么问题。
3.2cuDNN5.0版本结果
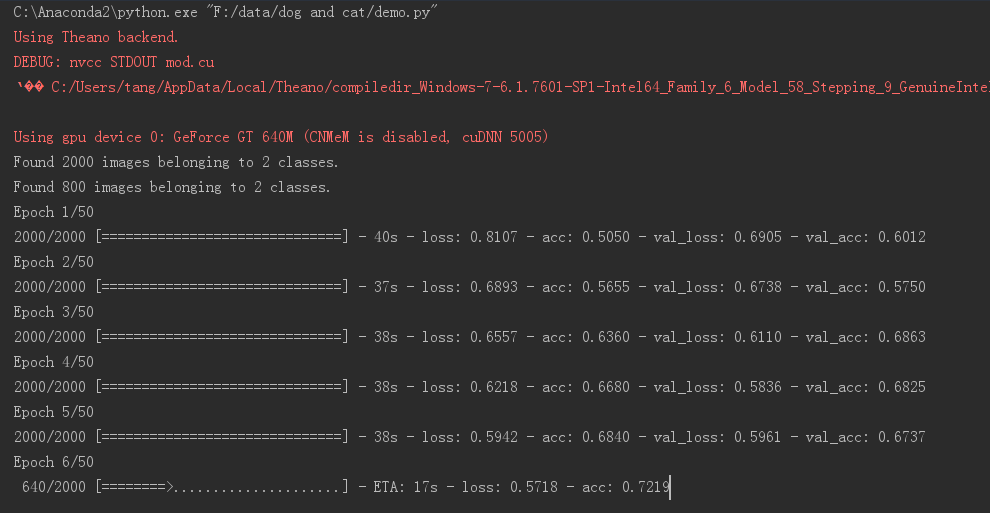
红字部分可以看到cuDNN版本号变了,但……速度提升不大。















 2377
2377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









