







最近,腾讯混元文生图模型HunyuanDiT 架构升级,并免费开源了。他采用的神经网络架构和Sara一样都是Diffusion Transformer,参数量已经达到15亿。官方测评效果显示超过目前开源的Stable Diffusion。试用下来效果比较令人惊喜。
建议硬件要求(模型推理):
INT4 : RTX30901或 RTX40901,显存24GB,内存32GB,系统盘200GB
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。
模型微调硬件要求更高。一般不建议个人用户环境使用
本文在Docker环境下部署,如需直接部署请参考官网相关说明。
环境准备
模型准备
- 第一步:模型下载
git clone https://huggingface.co/Tencent-Hunyuan/HunyuanDiT
下载地址: https://huggingface.co/Tencent-Hunyuan/HunyuanDiT
模型名称: Tencent-Hunyuan/HunyuanDiT
本文统一放在模型存档目录:/u01/workspace/models/HunyuanDiT
- 第二步:由于在启动时需要通过huggingface加载openai/clip-vit-large-patch14-336视觉模型,正常情况下不通过科学上网这里基本无法自动下载到该模型。也需要请提前下载好该模型
git clone https://huggingface.co/openai/clip-vit-large-patch14-336
保存位置:/u01/workspace/models/clip-vit-large-patch14-336
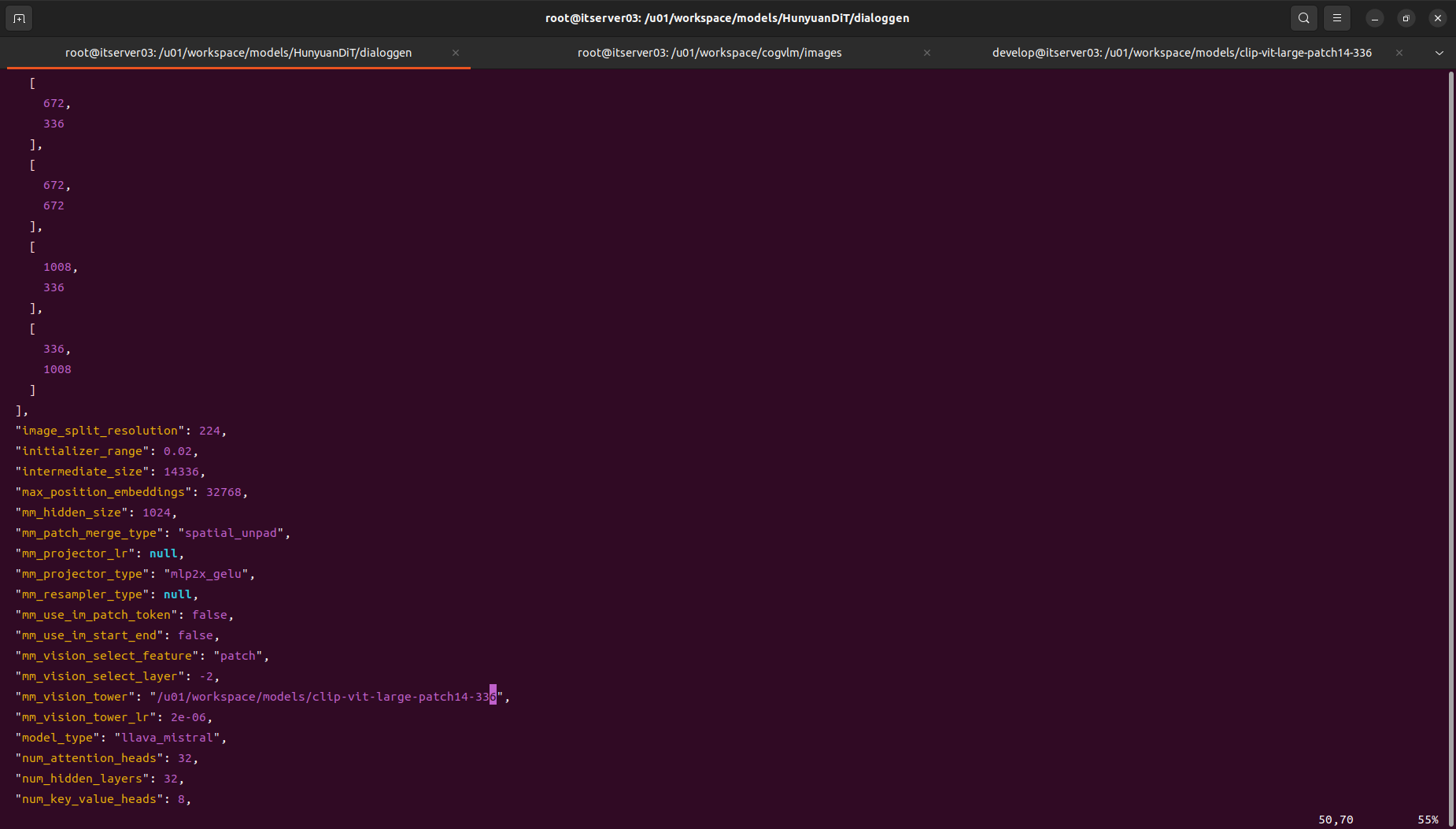
修改第一步下载模型中的配置文件:/u01/workspace/models/HunyuanDiT/dialoggen/config.json中mm_vision_tower 的值改为刚下载clip-vit-large-patch14-336的绝对路径下。
“mm_vision_tower”: “/u01/workspace/models/clip-vit-large-patch14-336”,, 如下图所示:
下载源码
git clone https://github.com/Tencent/HunyuanDiT;
cd HunyuanDiT
Dockerfile样例
注意
COPY HunyuanDiT/ /app/HunyuanDiT/这行执行需要根据世纪HunyuanDiT源码下载存放位置。
FROM pytorch/pytorch:2.2.1-cuda12.1-cudnn8-runtime
ARG DEBIAN_FRONTEND=noninteractive
WORKDIR /app
RUN pip install --user nvidia-pyindex
RUN pip config set global.index-url http://mirrors.aliyun.com/pypi/simple
RUN pip config set install.trusted-host mirrors.aliyun.com
RUN mkdir -p /u01/workspace/models/
COPY HunyuanDiT/ /app/HunyuanDiT/
WORKDIR /app/HunyuanDiT
RUN python -m pip install --verbose --use-pep517 -r requirements.txt
RUN pip install bitsandbytes huggingface_hub==0.23.0
EXPOSE 8000 8051
CMD [ "python","app/hydit_app.py"]
本文采用基础镜像pytorch/pytorch:2.2.1-cuda12.1-cudnn8-runtime 自带的 pip 相关版本与源码中的部分版本冲突(torchvision,protobuf,nvidia-pyindex),所以,下载原名后需要修改requirements.txt文件:
#--extra-index-url https://pypi.ngc.nvidia.com
timm==0.9.5
diffusers==0.21.2
peft==0.10.0
#protobuf==3.19.0
#torchvision==0.14.1
transformers==4.37.2
accelerate==0.29.3
loguru==0.7.2
einops==0.7.0
sentencepiece==0.1.99
cuda-python==11.7.1
onnxruntime==1.12.1
onnx
#nvidia-pyindex==1.0.9
onnx-graphsurgeon==0.5.2
polygraphy==0.49.9
pandas==2.0.3
gradio==4.31.0
构建image
docker build -t qingcloudtech/hunyuandit:v1.0 .
运行docker
docker run -it --gpus all \
-p 8501:8501 \
-v /u01/workspace/models:/u01/workspace/models \
qingcloudtech/hunyuandit:v1.0 \
python app/hydit_app.py --model-root /u01/workspace/models/HunyuanDiT --no-enhance
注意:
–no-enhance :禁用增强模型,低显卡配置情况下请启用,否则会报显存错误
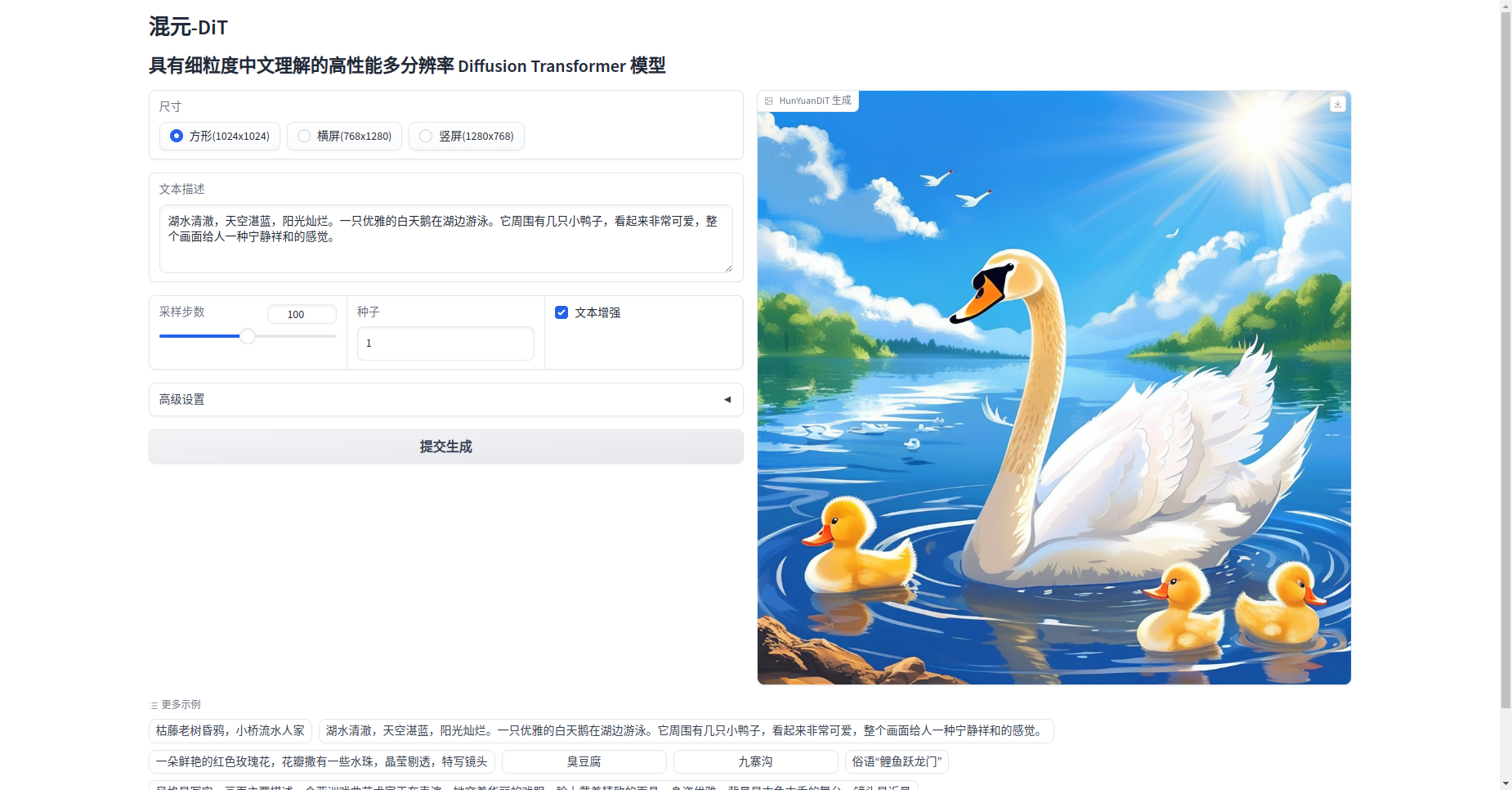
访问并验证
默认地址: http://127.0.0.1:443




【Qinghub Studio 】更适合开发人员的低代码开源开发平台
【QingHub企业级应用统一部署】
【QingHub企业级应用开发管理】
【QingHub** 演示】**
【https://qingplus.cn】

















 1509
1509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









