









- 对于取值多的属性,尤其一些连续型数值,比如两条地理数据的距离属性,这个单独的属性就可以划分所有的样本,使得所有分支下的样本集合都是“纯的”(最极端的情况是每个叶子节点只有一个样本)。
一个属性的信息增益越大,表明属性对样本的熵减少的能力更强,这个属性使得数据由不确定性变成确定性的能力越强。
所以如果是取值更多的属性,更容易使得数据更“纯”(尤其是连续型数值),其信息增益更大,决策树会首先挑选这个属性作为树的顶点。结果训练出来的形状是一棵庞大且深度很浅的树,这样的划分是极为不合理的。
C4.5使用了信息增益率,在信息增益的基础上除了一项split information,来惩罚值更多的属性。
- 熵:表示随机变量的不确定性。
条件熵:在一个条件下,随机变量的不确定性。
信息增益:熵 - 条件熵
在一个条件下,信息不确定性减少的程度!
通俗地讲,X(明天下雨)是一个随机变量,X的熵可以算出来, Y(明天阴天)也是随机变量,在阴天情况下下雨的信息熵我们如果也知道的话(此处需要知道其联合概率分布或是通过数据估计)即是条件熵。
两者相减就是信息增益!原来明天下雨例如信息熵是2,条件熵是0.01(因为如果是阴天就下雨的概率很大,信息就少了),这样相减后为1.99,在获得阴天这个信息后,下雨信息不确定性减少了1.99!是很多的!所以信息增益大!也就是说,阴天这个信息对下雨来说是很重要的!
所以在特征选择的时候常常用信息增益,如果IG(信息增益大)的话那么这个特征对于分类来说很关键~~ 决策树就是这样来找特征的!- 决策树的本质是找到数据与类别的关系,也就是说我们希望给定一些数据,通过这种关系可以确定每条数据的类别,并且显然这种关系越确定学好,而这种确定性的增加意味着我们希望随机性尽可能的减小。建立决策树的过程是每次选择一个特征对数据进行划分,这相当于给数据提供了已知信息,这个过程一定会使数据的不确定性减小,且不确定性减小的越多代表这次划分越有效,而这里面不确定性的减小程度就是用信息增益来度量的。
- 设计分类系统的时候,一个很重要的环节便是特征选择,面对成千上万上百万的特征,如何选取有利于分类的特征呢?信息增益(Information Gain)法就是其中一种简单高效的做法。本文首先介绍理解信息增益(Information Gain)需要的基本概念,之后介绍如何将其运用在特征选择中,最后以stanford-nlp中利用信息增益法实现特征选择的例子结束本文。
熵(Entropy)
介绍信息增益大法前,不得不提的一个概念就是熵。熵是信息论中一个很重要的概念,我们先看看它的长相:
如何量化信息
平时我们会这样说”这句话信息量好大”,我们通常所指的信息是指那句话里的语义,而这里我们谈的信息则是信息论鼻祖Shannon定义的,Shannon老爷子认为消息传递的过程是这样的:消息首先被编码器编码之后经过一定的通道再经过解码器解码,最后信息传递给目标。那么目标者能获得多少原来的信息则是我们这里所谈的信息,这样的信息可能是一堆废话,完全没”信息量”。
我们知道信息在传递的时候有很多不确定因素,而量化不确定因素的一个利器就是概率论,那么在概率框架下的信息的定义是这样的:对于一个事件
i
,它发生的概率是
pi
,那么当观察到该事件的时候,我们到底获得多少信息呢?Shannon老爷子是这样定义信息函数的:
第一,这样定义在实际中非常有用(不管黑猫白猫理论),工程的重要参数随数据概率的对数而线性改变。如时间、带宽、继电器数,等等。
第二,对数更接近我们本身的直观感受,我们是线性直观地测量实体对象,例如两张穿孔卡片比一张具有有两倍信息贮存量。
第三,以对数定义信息在数学上可以得到极大便利。
信息函数的性质
我们参考一下维基百科看看这样定义的性质有什么:
那么回过头来看看我们的老朋友熵:
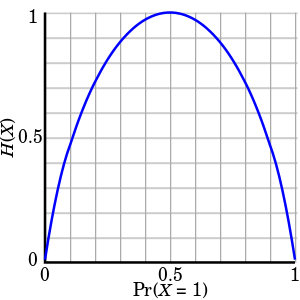
从图像中我们可以知道,当 Pr(X=1)=0.5 的时候, H(X) 达到峰值。因此我们可以这样直观地理解熵:熵是用来衡量事件可预知性,熵越大,事件发生的概率越随机。
条件熵(Conditional Entropy)
我们的目的是特征选择,那么现在假设我们在做一个垃圾分类器,首先我们从训练数据
X={x1,x2,...,xn}
中抽取特征,将每个输入
xi
映射到特征空间
Fi={f1,f2,...,fm}
,然后通过我们熟悉的机器学习算法比如SVM,NaiveBayes,LogisticRegression等等,从训练数据中获得这样的模型:
定义
我们先来看看这小节的主角的形象:
性质
好吧,看容貌,条件熵更加平易远人,我们知道熵是非负的,那么上面那一坨定义是否也是非负呢?利用Jensen不等式我们可以检验:
现在先不管复杂的表达式,我们试之从直觉上理解。上一节我们了解到熵是衡量事件发生的可预知性,那么条件熵我们可以这样理解,事件 Z 发生了对于我们知道事件 X 有什么贡献。当事件 Z 发生了但是完全没贡献时候,当前仅当 H(X)=H(X|Z) ,此时事件 X 与事件 Z 相互独立,否则,只要 H(X|Z)≥0 ,事件 Z 就对我们预知事件 X 有贡献,因为 H(X|Z)≤H(X) 的, Z 的出现导致熵变小了,我们对事件 X 的预知能力变强了。
尝试利用条件熵做特征选择
那么对于分类器而言,我们想知道某个特征对于分类这样的事件到底有多大贡献,然后对贡献太小的特征就舍弃,从而达到特征选择地效果。现在我们就进行尝试,假设我们有一个事件 F , f1=1 代表在我们拥有 f2,f3,...,fm 的情况下,再包含特征 f1 的事件, f1=0 则表明不包含特征 f1 的事件。那么我们想知道 f1,f2 对于我们识别垃圾到底哪个贡献大,我们可以比较 H(C=1|f1),H(C=1|f2) 看看哪个更小,熵小的特征说明对于识别信息为垃圾的事件贡献更大。于是我们计算所有特征都的 H(C=1|fi) ,按照从小到大排序,取前 K 个特征,太棒了,貌似我们解决了特征选择问题了。但是我们再仔细思考一下,上面的做法只是筛选出了对于识别是垃圾这种类别有用的特征,但是可能刷掉了对于识别非垃圾事件有用的特征,怎么办呢?我们可不可以比较一下 H(C=1|f1),H(C=0|f1) 的大小从而决定该特征是对识别为垃圾的事件贡献大还是对识别为非垃圾的贡献大呢?答案是否定的,因为两者不具备可比性,为什么呢?因为两者具有不同的上界,不在同一标准,所以不具备可比性。那该怎么办呢?
信息增益(Information Gain)
上一节我们一开始以为找到了特征选择的办法,后来发现是不可行的,这一次,我们的主角将为我们解决难题。
定义
老套路,我们还是先看看老兄的形象:
性质
我们照常来看看信息增益的一些性质。首先从定义可以很容易知道它符合交换律,也就是
由于两个事件相互的信息增益是相同的,所以信息增益也叫相互信息(Mutual Information)。对于定义,我们可以展开重写一下:
利用信息增益做特征选择
上一节中,我们说过 H(C=1|f1),H(C=0|f2) 不具备可比性,因为他们具有不同的上界 H(C=1),H(C=0) ,从而阻止我们利用条件熵来做特征选择,这次我们利用信息增益再看看会不会有相同问题。我们看
信息增益法在stanford-nlp的应用
前面讲了那么多理论,该是大显身手的时候了。我们再回过头来看如何求取分类与特征之间的信息增益。首先观察定义:
假设我们的训练样本数是
N
且看Dataset里面的一段代码:
public double[] getInformationGains() {
labels = trimToSize(labels);
ClassicCounter<F> featureCounter = new ClassicCounter<F>();
ClassicCounter<L> labelCounter = new ClassicCounter<L>();
TwoDimensionalCounter<F,L> condCounter = new TwoDimensionalCounter<F,L>();
for (int i = 0; i < labels.length; i++) {
labelCounter.incrementCount(labelIndex.get(labels[i]));
boolean[] doc = new boolean[featureIndex.size()];
for (int j = 0; j < data[i].length; j++) {
doc[data[i][j]] = true;//标识一下特征是否出现过
}
for (int j = 0; j < doc.length; j++) {
if (doc[j]) {//统计count(fi)和count(c|fi)
featureCounter.incrementCount(featureIndex.get(j));
condCounter.incrementCount(featureIndex.get(j), labelIndex.get(labels[i]), 1.0);
}
}
}
double entropy = 0.0;//计算H(C)
for (int i = 0; i < labelIndex.size(); i++) {
double labelCount = labelCounter.getCount(labelIndex.get(i));
double p = labelCount / size();
entropy -= p * (Math.log(p) / Math.log(2));
}
double[] ig = new double[featureIndex.size()];
Arrays.fill(ig, entropy);
//计算H(C|fi)
for (int i = 0; i < featureIndex.size(); i++) {
F feature = featureIndex.get(i);
double featureCount = featureCounter.getCount(feature);//count(fi=1)
double notFeatureCount = size() - featureCount;//count(fi=0)
double pFeature = featureCount / size();//p(fi=1)
double pNotFeature = (1.0 - pFeature);//p(fi=0)
if (featureCount == 0) { ig[i] = 0; continue; }
if (notFeatureCount == 0) { ig[i] = 0; continue; }
double sumFeature = 0.0;
double sumNotFeature = 0.0;
for (int j = 0; j < labelIndex.size(); j++) {
L label = labelIndex.get(j);
double featureLabelCount = condCounter.getCount(feature, label);//count(c,fi=1)
double notFeatureLabelCount = size() - featureLabelCount;//count(c,fi=0)
double p = featureLabelCount / featureCount;//p(c|fi=1)
double pNot = notFeatureLabelCount / notFeatureCount;//p(c|fi=0)
if (featureLabelCount != 0) {
sumFeature += p * (Math.log(p) / Math.log(2));
}
if (notFeatureLabelCount != 0) {
sumNotFeature += pNot * (Math.log(pNot) / Math.log(2));
}
}
ig[i] += pFeature*sumFeature + pNotFeature*sumNotFeature;//最后H(C)+H(C|F)
return ig;
}对于每个特征计算信息增益后,进行排序,然后就可以愉快地取前 K 个特征了!















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









