










《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》
论文:https://arxiv.org/abs/2010.11929
代码:https://github.com/google-research/vision_transformer
达摩院modelscope模型开源平台快速体验ViT模型: ModelScope 魔搭社区
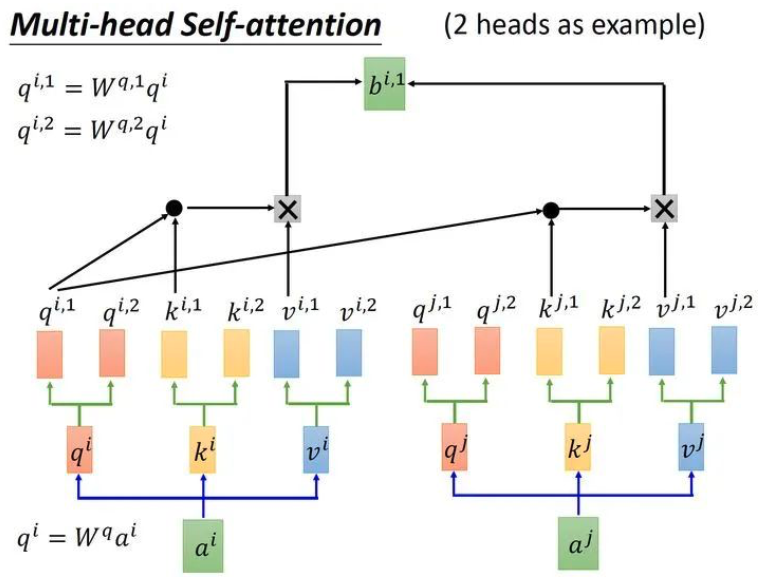
原理:使用transformer对长序列之间的关系进行建模(自注意力)
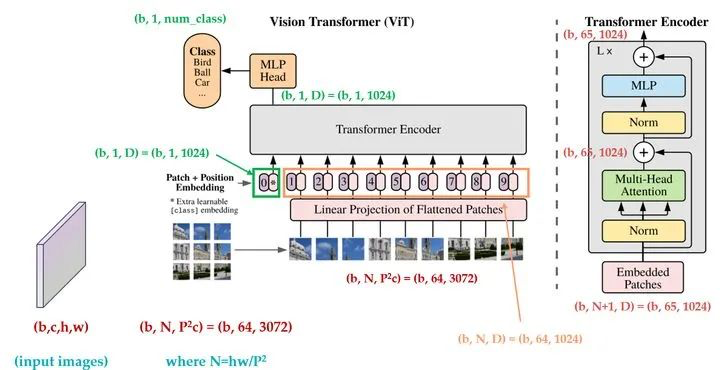
方法: 首次提出使用transformer进行分类:把输入图像直接划分为token,位置编码为可学习的token,额外增加一个分类token,最后使用head预测。
结果: acc提升, sota















 3592
3592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









