






论文:Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020

1.文章背景
计算机视觉当前最热门的两大基础模型就是Transformer和CNN了。
- Transformer的应用
Transformer提出后在NLP领域中取得了极好的效果,其全Attention的结构,不仅增强了特征提取能力,还保持了并行计算的特点,可以又快又好的完成NLP领域内几乎所有任务,极大地推动自然语言处理的发展。
但在其在计算机视觉领域的应用还非常有限。在此之前只有目标检测(Object detection)中的DETR大规模使用了Transformer,其他领域很少,而纯Transformer结构的网络则是没有。
VIT这篇文章就是将Transformer模型应用在了CV领域,它将图像处理成Transformer模型可以应用的形式,沿用NLP领域中Transformer的方法,直接验证了其精度可以和ResNet不相上下,展示了在计算机视觉中使用纯Transformer结构的可能,为Transformer在CV领域的应用打开了大门。
- Transformer的优势
1.并行计算
例如RNN,它每一层的参数都依赖前一个参数的计算结果,较难进行并行计算。而例如CNN,它每一层的计算的输入都是上一次的结果直接获取来的,可以进行并行计算,Transformer模型也具有这种能力。
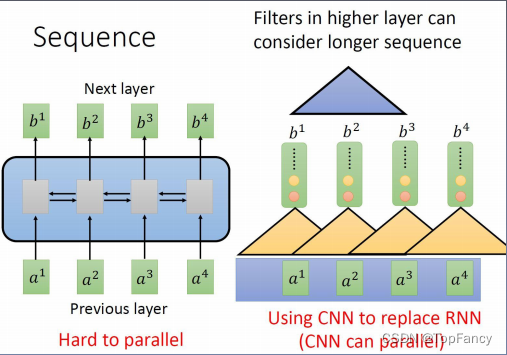
2.全局视野
其计算可以层叠更大的图像范围
3.灵活的堆叠能力
由于MultiHead Attention机制,其堆叠能力更加灵活
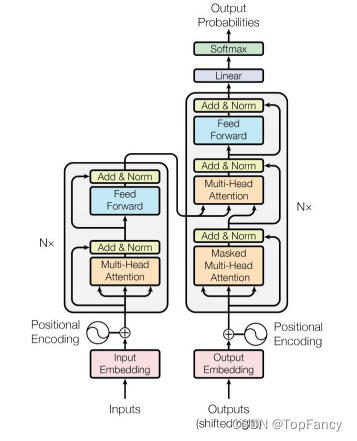
2.文章导读
2.1摘要核心
- Transformer在NLP中已经成为经典
- 在CV中,Attention机制只是作为一个补充在使用
- 我们使用纯Transformer结构就可以在图像分类任务上取得不错的结果
- 在足够大的数据集上训练后,ViT可以拿到和CNN的SOTA不相上下的结果
2.2 VIT结构
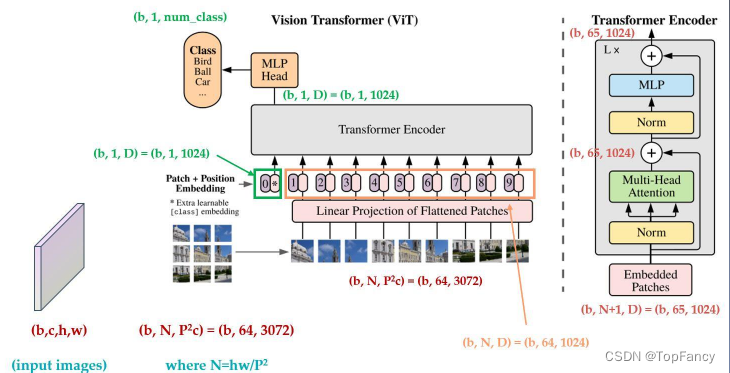
VIT的主要思想就是迁移在NLP中应用很好的Transformer模型,以求在使用时做出最小的改动,来验证模型在CV领域应用的效果。要把原来的NLP中的模型应用在CV领域,需要对图像输入做出处理,这就隐身出来本文的核心idea:把图像切分重排,当作输入。
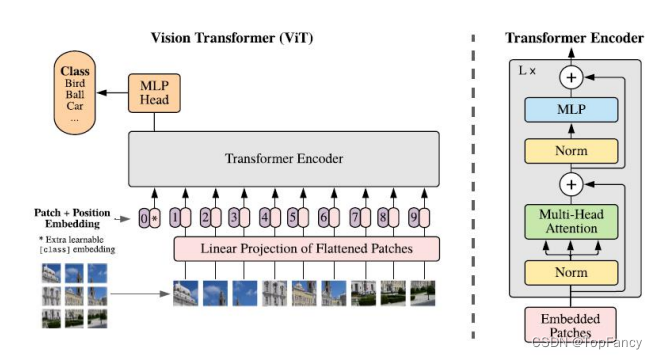
2.3 Attention 注意力机制
Attention其本质可以认为是加权平均。
输入层的各个参数与权重相乘后求和得出一个预测值。权重是如何获取的呢,实际上就是相似度计算。
将输入的图像解析之后,每个输入的要素都转换成坐标系上的向量,计算要素的相似度就可以转换为计算要素向量在坐标系上的距离,距离近的相识度高,距离远的相识度低,就可以使用向量的点积运算来做处理。
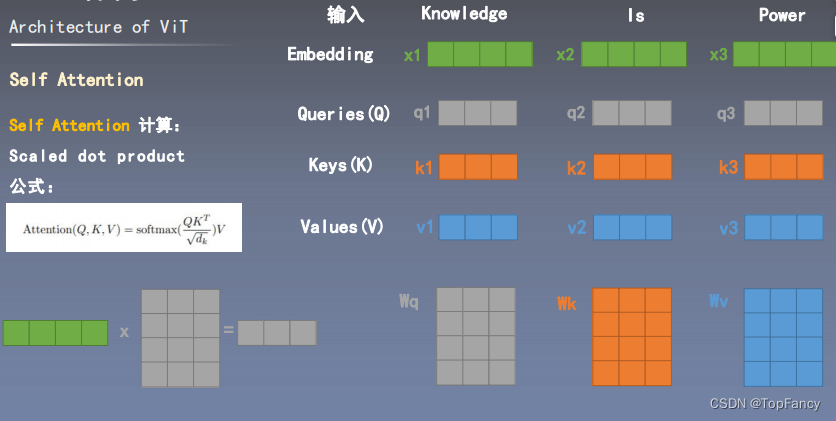
Q是输入值,K是关键词,self attention的计算实际上是在计算每个q和每个k的相似度。除以dk的平方根是为了避免较大的数值,较大的数值会导致softmax之后值更极端,softmax的极端值会导致梯度消失。softmax是将所有的值的权重和置为1,这个操作就想人的注意力似的,人对所有这些要素的注意力为1,有的要素注意力多点,有的要素注意力少点,softmax之后可以使权重更加集中。
相乘之后再进行相加,类比一词多意理解,这个词的多个意思都代表了这个词,具体要使用哪个意思需要借助其在句子中的意思。
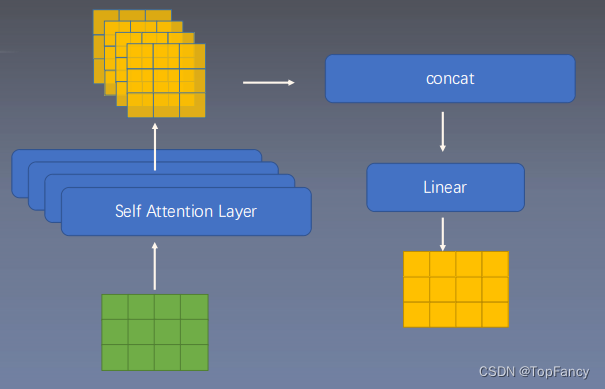
然后进行MultiHead Attention操作,有多个Wq,Wk,Wv重复多次,结果concat一起。
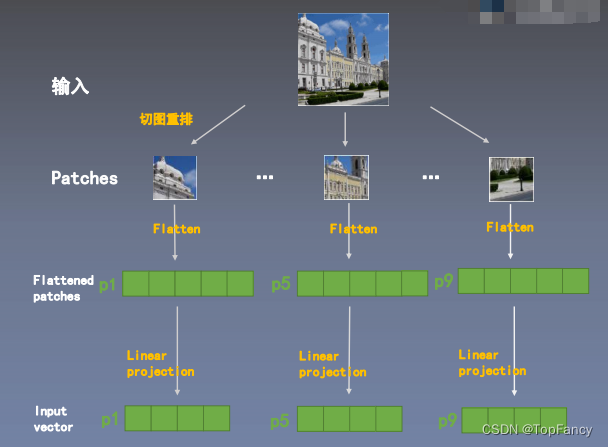
2.3 输入端适配
将图像切图重排成一个个Patches,Patch经过Flatten操作后,获得一个个向量(Flattened patohes),然后经过Linner Projection获取到Input vector。
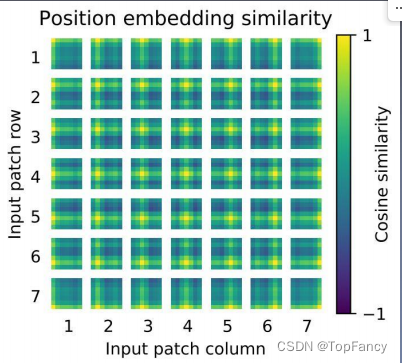
2.4 位置编码
图像切分重排后失去了位置信息,并且Transformer的内部运算是空间信息无关的,所以需要把位置信息编码重新传进网络;ViT使用了一个可学习的vector来编码,编码vector和patch vector直接相加组成输入
2.5 数据流
3.实验结果
ViT和ResNet Baseline取得了不相上下的结果
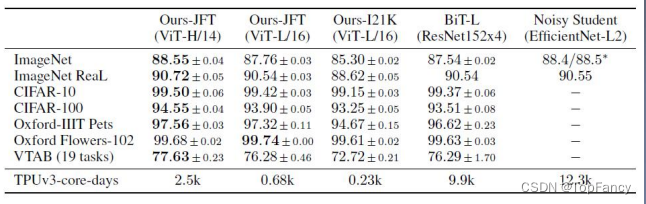
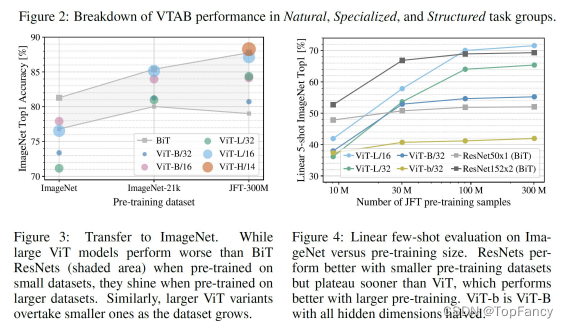
VIT 的性能可能依赖更大量的数据
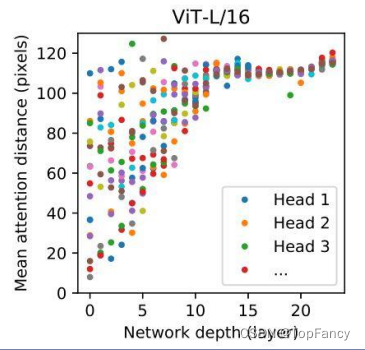
Attention距离和网络层数的关系
Attention的距离可以等价为Conv中的感受野大小
可以看到越深的层数,Attention跨越的距离越远
但是在最底层,也有的head可以覆盖到很远的距离
这说明他们确实在负责Global信息整合















 775
775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









