








【翻译】Convolutional Experts Network for Facial Landmark Detection
摘要: 约束局部模型(CLM)是一个成熟的面部标记点检测方法系列。然而他们最近不如 级联回归 方法流行。这部分是由于现有CLM局部检测器无法对表情,照明,面部毛发,化妆等影响的非常复杂的标记点外观进行建模。我们提出了一种新颖的局部检测器 - 卷积专家网络(CEN),它将端到端框架中的 神经结构和专家混合 的优点汇集在一起。我们进一步提出使用CEN作为局部检测器的卷积专家约束局部模型(CE-CLM)算法。我们证明,我们提出的CE-CLM算法在四个公开可用的数据集上大大地优于具有竞争力的面部标记点检测的最先进的基线。我们的方法在挑战性的个人侧颜图像上特别准确和鲁棒。
- 引言
面部标记点检测是面部表情分析,面部3D建模,面部属性分析,多模态情感分析,情感识别和人物识别等多个研究领域的重要的 初步步骤 [10,22,42,30]。这是一个经过深入研究的大量注释数据的问题,在过去几年中引起了人们的兴趣。
最近,面部标记点检测最流行的方法之一是约束局部模型(CLM)家族[10,29]。他们使用局部检测器单独模拟每个面部标记点的外观,并使用形状模型执行约束优化。CLMs包含了许多其他方法缺乏的许多优点和扩展:1)对每个标记点的外观进行建模使得CLM对闭塞稳健[1,29];对3D形状模型和多视图局部检测器的自然扩展允许CLMs自然采用姿态变化[29,24]和具有里程碑意义的遮挡[3]; 3)基于期望最大化的模型导致视频中的跟踪平滑[29]。这使得他们成为一个非常有吸引力的 面部标记点检测和跟踪 方法。
尽管有这些好处,CLM最近也被各种级联回归模型超过了[38,48]。 我们认为基于CLM的方法的相对性能不足是由于使用了局部检测器,这些检测器无法对局部标记点特征的复杂变化进行建模 。 鲁棒准确的局部检测器应该明确地建立这些不同的外观原型存在于同一标记点对齐概率。
我们引入了一种称为卷积网络的新型局部检测器,它将端到端框架中的神经体系结构和混合专家的优势汇集在一起[40]。CEN能够学习专家的混合物,捕获不同的外观原型, 而不需要明确的属性标签 。为了解决面部标记点检测问题,我们提出了卷积专家约束局部模型(CE-CLM),它是使用CEN作为局部检测器的CLM模型。我们通过对四个可公开提供的数据集,300W [25],300V [31],IJB-FL [15] 和Menpo挑战赛[44]的大量实验来评估我们的CEN局部检测器和CE-CLM面部标记点检测算法的优点。后两个数据集包括具有极高挑战条件的侧颜面部姿势的大部分。此外,我们将后三种用于跨数据集实验。
本文的结构如下:第2节讨论CE-CLM的相关工作,第3节介绍了CE-CLM。在第4节中,我们对CEN局部检测器进行了评估,并比较了CE-CLM与其他面部标记点检测方法。我们在第5节总结论文。
- 相关工作
面部标记点检测在数量上起着至关重要的作用研究领域和应用如面部特征检测[18],面部表情分析[22],情感认知和情绪分析[43,41,23,39]和3D面部重建[14]。对面部标记点检测工作的全面综述不在本文的范围之内,我们提及读者对该领域的近期评论[11,37]。
现代面部标记点检测方法可以分为两大类: 基于模型和回归的 。基于模型的方法通常明确地模拟面部标记点的外观和形状,尤其是限制形状的搜索空间并提供一种正则化形式。另一方面,基于回归的方法不需要明确的形状模型,并且在外观上直接执行标记点检测。我们简要介绍最近的模型和基于回归的方法。
基于模型的方法找到与图像外观相匹配的面部模型的最佳参数。基于模式的方法是约束局部模型[10,29]及其各种扩展,例如约束局部神经域[2]和判别响应映射拟合[1],其使用判别分类器计算局部响应映射的方法并推断标记点位置。另一个值得注意的基于模型的方法是使用基于树的可变形部件模型[50]的混合来共同执行面部检测,姿态估计和面部标记点检测。这种方法的扩展是高斯牛顿变形部分模型[36],它们使用高斯-牛顿优化联合优化部分基于柔性外观模型以及全局形状。最近提出的3D密集面对准方法[49]使用CNN更新3D变形模型[6]的参数,并且在侧颜面的面部标记点检测上显示出良好的性能。
基于回归的模型直接从外观预测面部标记点位置。大多数这样的方法采用 级联回归框架 ,其中通过在 显式形状回归 中给出当前界限估计值,通过在外观上应用回归因子来不断改进标记点检测[7]。级联回归方法包括 监督梯度下降法(SDM) [38],其采用线性回归的SIFT [21]特征来计算形状更新和粗略到精细形状搜索(CFSS)[48],其尝试避免通过执行粗略到精细形状搜索的局部最优。推出级联回归(PO-CR)[35]是另一个级联回归示例,更新形状模型参数,而不是直接预测标记点位置。
最近的工作也用了深层次的学习技巧标记点检测。粗到精的自动编码器网络[45]使用自动编码器提取的视觉特征进行线性回归。孙等人[32]提出了一种用于稀疏标记点检测的基于CNN的级联回归方法。同样,Zhang等[47]提出在多任务学习框架中使用CNN来通过训练网络来学习面部特征来改善面部标记点性能。最后,Trigeorgis等[34]提出了助记符下降方法,其使用经常性Neual网络来对基于地理位置地点提取的基于CNN的视觉特征进行级联回归。
3 卷积专家CLM
卷积专家约束局部模型(CE-CLM)算法由两个主要部分组成:使用卷积专家网络的响应图计算和形状参数更新。在第一步中,独立于其他标记点的位置来估计个别标记点对齐。在参数更新期间,所有标记点的位置被联合更新,并使用点分布模型对不对准的标记点和不规则形状进行惩罚。我们优化以下目标:
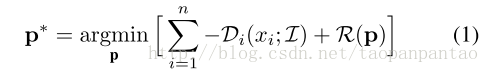
式中p *是控制标记点位置的最佳参数集(参见等式3),其中p为当前值估计。Di是计算输入面部图像I(3.1节)的位置xi中的标记i的对齐概率。R是点分布模型(3.2节)实施的正则化。方程1的优化使用 非均匀正则化标记点平均移位算法(NU-RLMS) (第3.3节)进行。
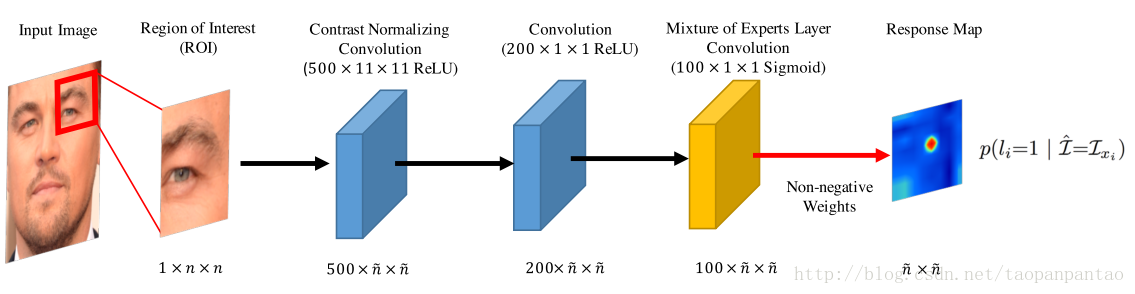
Figure 1 图2:卷积专家网络模型概述。给定输入图像,并且基于标记点位置的估计,从中提取大小为n×n的块。该小区域通过卷积核形状为500×11×11的对比度归一化卷积层,在相关运算之前进行Z分数归一化,输出500×n×n。之后,利用ReLU单位将响应图输入到200×1×1的卷积层。专家层的混合学习一个集合来捕获ROI变化,并使用100×1×1 sigmoid概率决策内核的卷积层。输出响应图是使用S形激活的ME层中神经元的非负和非线性组合。
3.1.卷积专家网络
CE-CLM算法的第一个也是最重要的一步是计算响应图,通过评估各个像素位置的标记点对齐概率,帮助准确地定位个别标记点。在我们的模型中,这是由CNN完成的,它采用围绕标记点位置的当前估计值的n×n像素区域作为输入,并且输出在每个像素位置评估标记点校准概率的响应图。有关图示请参见图2。
在CNN中,在形状为500×11×11的卷积层之间进行Z分数归一化,然后计算输入和内核之间的相关性。输出响应图然后与200×1×1个ReLU神经元的卷积层进行卷积。
CNN最重要的层次是能够通过可以对不同标记点外观原型进行建模的专家组合来建模最终对准概率。这是通过使用称为专家层混合(ME层)的特殊神经层来实现的,该层是使用S形激活的100×1×1的聚集层,输出个体专家对对齐概率的投票(由于可以解释sig-moid作为概率)。然后将来自各个专家的这些响应图与最后一层的非负权重组合,然后进行S形激活。这可以被看作是导致最终对齐概率的专家的组合。我们的实验表明,ME层对于提出的卷积专家网络的性能至关重要。
简单来说,在公式1的迭代中,将CEN作为输入给出了图像ROI,并输出了评估单个标记点对齐的概率响应图。因此,将标记点i拟合到位置xi遵循以下等式:
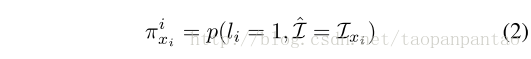
是标记点号码i对齐的坐标。图像的位置xi处的图像I# xi。响应映射π# i(大小n×n)然后用于最小化等式1。详细的网络训练程序在4.1节中给出,包括在测试时间为n选择的参数。我们的实验表明,使CNN模型更深入,不会改变网络的性能。我们使用消融技术来研究第4.1节中ME层的影响。
3. 2. 点分布模型
点分布模型[9,29]用于两者在CE-CLM框架中规划标记点位置并规范形状。最终检测不规则形状使用公式1中的术语R(p)对标记点进行惩罚。在以下PDM方程中,使用p = [s,t,w,q]对标记点位置_x_i = [_x_i
,_y_i]T进行参数化
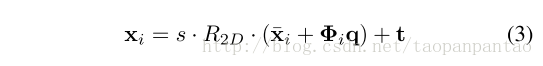
式中x_i表示PDM的第_i个标记点的2D位置,并且p = {s,R,t,q}表示PDM参数,其由全局缩放s,旋转R,平移t和 非刚性参数* q*组成。
3.2. NU-RLMS
方程1可以使用非均匀调节变化的Landmark Mean Shift(NU-RLMS)[2]。给定初始CE-CLM参数估计p,NU-RLMS迭代地找到更新参数Δp,使得p * = p0 +Δp接近等式1的解。NU-RLMS更新找到解决以下问题的解决方案:
其中J是具有参数p的标记点位置的雅可比矩阵。Λ-1是p上的先验矩阵具有高斯先验N(q; 0,Λ),用于非刚性形状,并且对于形状参数是均匀的。等式4中的W是用于加权平均移位向量的加权矩阵:W =wi diag(c1; …; cn; c1; …; cn)和ci是基于相关系数的模型训练期间计算的标记点检测器精度。v = [vi]是使用高斯核密度估计器使用CEN的响应图计算的平均移位向量:
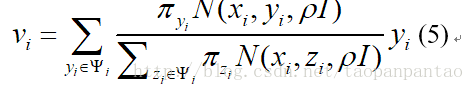
xc i是标记点位置和ρ的当前估计是一个超参数。这导致我们对NU-RLMS的更新规则
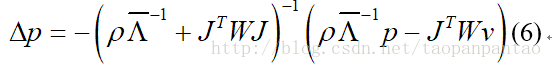
4. 实验
在我们的实验中,我们首先评估其性能卷积专家网络,并与LNF [2]和SVR [29]局部检测器(patch专家)的性能进行比较。我们还评估了关键ME层对CEN性能的重要性。我们最终的面部标记点检测实验探索了我们的模型在两个设置中的使用:图像和视频。我们所有的实验都是针对具有挑战性的公开数据集进行的,并与其中一些最新的基准进行比较
表1 :使用平方相关r2(较高)和RMSE(较低)的CEN,LNF [2]和SVR [29]的比较。为了评估ME层的必要性,我们还与CEN(无ME层)进行比较,这是一个对ME层权重没有非负约束的模型。性能下降表明ME层的关键作用。
| 探测器 | r2 | RMSE * 103 |
|---|---|---|
| SVR[29] | 21.31 | 66.8 |
| LNF [2] | 36.57 | 59.2 |
| CEN | 64.22 | 37.9 |
| CEN(无ME层) | 23.81 | 65.11 |
和跨数据集。CE-CLM和CEN训练代码可在1)https://github.com/A2Zadeh/ CE-CLM,2)multicomp.cs.cmu.edu/ceclm和3)作为OpenFace [4]的一部分https://github.COM/ TadasBaltrusaitis / OpenFace。
4.1.CEN实验
在本节中,我们首先描述CEN局部检测器的训练和推理方法。然后,我们比较CEN与LNF [2]和SVR [29]专家的性能,然后进行消融研究,以研究ME层的关键作用。
训练过程:对于所有的实验CEN对LFPW和Helen训练集以及多PIE数据集进行了训练。在训练过程中,位于11×11卷积区域的中心,则标记点存在的概率较高。提取总共5×10# 5卷积区域用于训练集,并选择6×10# 4作为测试集。我们每个标记点训练了 28套CEN :七点方向±70°,±45°,±20°,0偏航;和四个尺度17,23,30和60像素的眼间距离。减少需要训练的局部检测器的数量我们以不同的偏航角度查看了局部检测器,并且在正面视图的左侧和右侧使用相同的专家。CEN的优化者是Adam([16])学习速度为5×10# -4
,并训练了100个轮次,小批量512(每个标记点大约有80万个更新)。对于每个标记点,规模和视图已经对CEN局部检测器进行了训练。训练每个CEN模型在GeForce GTX Titan X上需要6个小时,但是一旦训练过的推理可以快速完成并行化。我们比较LN局部检测器与LNF和SVR贴片专家的性能改进。表1显示了每个标记点的平均表现。由于对齐概率推论是一个回归任务,我们使用地面真实验证集和局部检测器输出之间的平方相关(r2)和RMSE作为精度的度量(对于r2而言更好,RMSE更好)。训练和测试数据所有的型号都一样。平均CEN局部检测器比LNF好75.6%,比SVR高出近200%(以r2计算),这显示出显着的改善。虽然这是一个平均水平,但对于某些标记点,观点和规模,性能改善超过了LNF超过100%。这是17像素双眼距离尺度的具体情况,因为CEN能够基于图像中更大的标记点邻域的更大的外观来建模标记点的位置(图像中存在更多的上下文)。
我们还评估了ME层的重要性CEN模型。表1显示了CEN和CEN(无ME层)之间的差异。我们表明,将连接权重的非负约束从最终决策层(基本上删除了模型的专家混合能力)和再训练网络,显着降低了性能,几乎达到了SVR的水平。这表明ME层是至关重要的,也许是最重要的CEN模型的重要部分,在移除输入支持区域时捕获纹理,照明和外观变化范围,防止模型处理这些变化。
在图3中,我们可以看出CEN的改进不同标记点的LNF局部探测器,如眼睛,嘴唇和脸部侧颜。地面真相反应图是以标记点位置为中心的正态分布。来自CEN的输出响应图显示了对标记点的位置的更好的确定性,因为其响应图更集中在地面真相位置周围。虽然LNF输出没有显示这种集中的行为。因此,我们得出结论,CEN的主要改进来自于准确的局部检测,直接转移到标记点检测任务的改进。
4.2.CE-CLM实验
在本节中,我们首先描述用于训练的数据集并评估我们的CE-CLM方法。然后,我们简要讨论用于标记点检测的可比较的最先进的方法。最后,我们提供图像和视频上的面部标记点检测结果。
4.2.1数据集
我们在四个公开的数据集上评估了我们的CE-CLM:一个数据内评估(300-W)和三个跨数据集评估(Menpo,IJB-FL,300-VW)。我们认为交叉数据集评估呈现与基线相比,CE-CLM泛化最强的一例。数据集将在下面进行更详细的描述。
300-W [25,27]是四种不同面部的元数据集标记点数据集:Wild(AFW)[56],iBUG [26]和LFPW + Helen [5,20]数据集中的注释面。我们使用完整的iBUG数据集和LFPW和HELEN的测试分区。这导致了135,224和330个图像进行测试。它们都包含在野外的不受控制的脸部图像:在室内和室外环境中,在不同的照明下,存在遮挡,不同姿势以及来自不同质量的相机。我们使用LFPW和HELEN测试仪以及iBUG进行模型评估(因为一些基线使用AFW进行训练)。
Menpo基准挑战[44]数据集是非常重要的,用于标记点检测的综合多姿态数据集在显示任意姿势的图像中。训练集由8979张图像组成,其中2300张图片标有39个标记点点;其余图像标有68个标记点。数据集的图像主要是具有挑战性的AFLW [19]数据集的重新注释的图像。
IJB-FL [15]是IJB-A [17] - 面部识别基准。它包含180个图像的标签(128个正面和52个侧颜面)。这是包含非正面姿势的图像的挑战性子集,具有严重的遮挡和较差的图像质量。
300-VW [31]测试集包含64个标记为68的视频每个框架的面部标记点。测试视频分为三种类型:1)实验室和自然光线充足的条件; 2)不受约束的条件,如不同的照明,黑暗的房间和曝光过度的照片; 3)完全无约束的条件,包括照明和护照,如手动闭塞。
4.2.2基线
我们将我们的方法与面向标记点检测任务的一些已建立的基线进行了比较,包括级联回归和基于模型的方法。在所有情况下,我们使用作者提供的实现1,这意味着我们与每个基线的最佳可用版本进行比较,并使用相同的方法。
CFSS [48] 粗到精细形状搜索是最近的级联回归方法。这是300-W竞争数据的当前最先进的方法[25,8]。该模型训练了Helen和LFPW训练集和AFW。
CLNF是约束局部模型的扩展使用连续条件神经领域作为补丁专家[3]。该模型训练了LFPW和Helen训练集以及CMU Multi-PIE [12]。
PO-CR [35] - 是最近的级联回归方法它更新形状模型参数,而不是直接在投影空间中预测标记点位置。该模型训练了LFPW和Helen训练集。
DRMF - 区分响应图拟合直接对补丁专家响应映射进行回归,而不是对参数空间进行优化。我们用由LFPW [5]和Multi-PIE [12]数据集训练的作者[1]提供的实现。
3DDFA - 3D密集面对齐[49]已经显示了侧颜图像中面部标记点检测的最先进的性能。该方法使用300W的合成大面积图像的扩展的300W-LP数据集[49]。
CFAN - 粗到细自动编码器网络[45],对LFPW,HELEN和AFW训练的自动编码器视觉特征进行了级联回归。
TCDCN - 任务约束深卷积网络 - 工作[47]是面部标记点检测的另一种深度学习方法,它使用多任务学习来提高标记点检测性能。
SDM - 受监督的下降方法是非常受欢迎的级联回归方法。我们使用在多PIE和LFW [13]数据集训练的作者[38]的实现。
对所有上述基线进行了训练,以检测无面部侧颜(49或51)的标记点,或以面对面(66或68)进行检测。对于每个比较,我们使用最大的重叠标记点集,因为所有方法共享49个特征点的相同子集。为了评估侧颜图像(存在于IJB-FL和Menpo数据集)中的检测,我们使用地面真实图像和检测图像中共享标记点的子集。由于Menpo个人侧颜面的注释与68标记点计划略有不同,我们通过删除两个下标标记点并使用线性插值来遵循注释曲线将4个眉毛标记点转换为5;和10个面部侧颜标志到9.这仍然是一个公平的比较,因为没有一个方法(包括我们的)在Menpo上受过训练。
4.2.3实验设置
我们使用与第4.1节所述相同的CEN多视图和多尺度本地检测器。我们的PDM训练了多PIE和300W训练数据集,使用运动中的非刚性结构[33]。对于模型拟合,我们使用多尺度方法,每个迭代使用更高级别的CEN。对于每次迭代,我们使用逐渐变小的感兴趣区域{25×25,23×23,21×21,21×21}。对于NU-RLMS,我们基于训练数据上的网格搜索设置σ= 1.85,r = 32,w = 2.5。给定了一个边框,我们初步建立了七个不同的CE-CLM地标位置方向:正面,±30°偏航和±30°间距,±30°滚动(由于轮廓大,我们增加了Menpo和IJB-FL数据集的四个额外初始值±55°,±90°偏航面)。如果收敛最大后验得分高于或低于验证期间确定的阈值,我们可以提前停止和丢弃假设评估。这种早期停止将模型速度平均提高了四倍。在拟合期间,我们不会计算自封闭地标的响应图,也不要将其用于参数更新。
为了公平的模式比较,基线和我们的模型已经使用相同的协议进行了初始化。对于300-W数据集,我们使用挑战组织者提供的边界框初始化了所有方法。对于Menpo,我们使用多任务卷积神经网络[46]面部检测器初始化了方法,该检测器能够检测96%图像中的面部。我们执行了边界框的仿射变换,以匹配68个面部地标周围的边界框。对于IJB-FL,我们通过在地面真实地标上添加噪声(基于300-W数据集中的边界框的噪声属性)来生成面包围框来初始化方法。对于300VW,我们使用多任务卷积神经网络[46]面部检测器检测每个视频的每第30帧的脸部。当在框架中没有检测到脸部时,我们使用最接近的框架,而成功检测。我们从检测到的边界框执行线性映射,围绕所有68个地标(如Menpo数据集)所做的一致。每个基线从检测初始化,并允许使用先前检测到的地标或使用新的边界框追踪30帧。
4.2.4标记点检测结果
在这样的工作中常见的是,我们使用每个图像的 尺寸归一化误差的交换误差曲线 来显示标记点检测精度。我们还会报告每个图像误差的标准化中值的大小。我们报告中值而不是平均值,因为误差不是正态分布的,平均值非常容易出现异常值。对于仅包含接近正面(300-W和300V)的数据集,我们通过 眼间距离(IOD)来归一化误差 ,对于包含其中一个眼睛可能不可见的侧颜面的图像,我们改为使用平均值面部宽度和高度。
300-W数据集上的标记点检测结果可以在表2和图4中可以看出,我们的方法在68和49点情景下都胜过所有基线(除了iBUG数据集49个标记点案例中的PO-CR)。CE-CLM的改进精度在包括面部侧颜的68个标志性案例中尤其明显。这是一个更困难的设置,因为脸部侧颜的模糊性,并且很多方法(特别是基于级联回归的方法)不能解决。
IJB-FL数据集上的标记点检测结果可以在表4中可以看出,CE-CLM模型在这个艰巨的任务上优于所有基线,对于侧颜面具有很大的余地。
Menpo数据集上的标记点检测结果可以在 表3和图5 中可以看出,CE-CLM模型也超越了这个艰巨任务的所有基线。性能改进在侧颜面上特别大,SDM,CFAN,DRMF和PO-CR方法完全无法处理。我们还优于最近设计的3DDFA模型,用于大型姿势面配合。由于这些结果在跨数据集评估中,它们展示了我们的方法如何概括地看到数据的不可见性以及它在挑战性面孔方面的表现(例如,参见图7)
视频上的标记点检测和跟踪结果300 VW数据集显示在图6中。CE-CLM始终优于所有三个类别中的所有基准,具有第1类最大的改进。最后,我们的方法胜过最近提出的iCCR标记点跟踪方法,对其跟踪的特定人物[28]。然而,由于这是一种视频方式,这与我们的工作和其他基线独立对待每个视频帧不是一个公平的比较。请注意,我们的方法在正面和侧颜面上表现良好而其他方法对于正面(CFSS,PO-CR)或侧颜(3DDFA)表现良好。在不同类别的300 VW中,其他方法的性能也不尽相同,而CE-CLM始终如一地表现出优于其他方法。
- 结论
在本文中,我们介绍了卷积专家局部模型(CE-CLM)是CLM系列的新成员,它使用称为卷积专家网络(CEN)的新型局部检测器。我们提出的局部检测器能够通过内部学习检测器的集合来处理不同的标记点外观,从而对标记点外观原型进行建模。这是通过专家层的混合来实现的,该层由决定神经元连接到非负权重到最终决策层。在我们的实验中,我们表明这是CEN的重要组成部分,其优于以前引入的LNF和SVR的局部检测器。由于这种更好的性能,CE-CLM能够比面部标记点检测的最先进的方法执行更好的准确性(图4),并且更加坚固,特别是在侧颜面的情况下(图5) 。图7显示了在一组有挑战性的图像上的CE-CLM,CFSS和CLNF标记点检测方法之间的可视比较。CE-CLM即使在极端侧颜面上也能够准确对齐标记点。

















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









