







花了点时间研究了一下Python中的编码问题,在Python2.*的版本中存在着以下两种字符串的类型:
- Str类型:这里说的Str类型和我们在C语言里用到的字符串是一个概念,本质就是一个Bytes数组。这个Bytes数组内可以存任意的形式,可以想象“UTF-8”格式的字符串、“GBK”格式的字符串、原始格式的字符串等,他们的二进制都不一样,这些二进制都可以放进Str类型里,为我们带来不少困扰,有时候并不知道这个字符串是啥类型的。例如“编码”这两个汉字用UTF-8格式编码对应的二进制就是'\xe7\xbc\x96\xe7\xa0\x81',可以放进这个str类型里
- Unicode类型: 这里说的Unicode指的是一串Unicode的数字映射(code point), 用于映射某个字符与一个Unicode的对应关系。Unicode就是为了统一各国各地区的编码规则, 重新搞了一套包罗地球上所有文化符号的字符集。Unicode没有编码规则, 只是一套包含全世界符号的字符集。Unicode并不完美,所以之后还出现了UTF-8、UTF-16等,可以认为Unicode和UTF-8对应的二进制是不一样的,UTF-8对应的二进制可以放进Str类型里,Unicode对应的的数字映射可以放进Unicode类型里,例如“编码”这两个汉字用Unicode映射对应的结果是u'\u7f16\u7801'。
【Python字符串中的Str类型和Unicode类型】
因此,同样是“编码”两个汉字,分别用Str类型和Unicode类型保存时对应的Type完全不一样,以下是他们赋值操作的区别:

【Str类型和Unicode类型的相互转换】
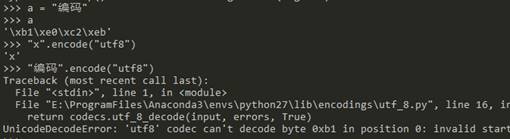
当然,Python2提供了这两种字符串类型的转换,encode的本意是从Unicode类型转Str类型,decode反之。但是在Python 2.7版本中,还存在str类型.encode(“utf8”)变成另外一个str类型的情况,这让函数的调用更加复杂。在Anaconda Python2.7版本中,中文Str类型.encode(“utf8”)是不支持的,会直接抛Exception。但是在IronPython 2.7版本中,中文Str类型.encode(“utf8”)是支持的,但是会把中文encode成乱码,如下两图所示:
| Anaconda Python2.7 不支持中文Str类型.encode(“utf8”) | IronPython2.7支持中文Str类型.encode(“utf8”) |
|
|
|

【json.dumps()函数的ensure_ascii参数】
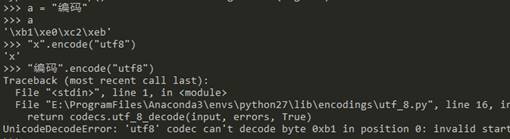
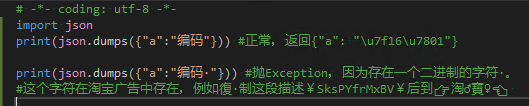
json.dumps()函数在Anaconda Python2.7和IronPython2.7的行为也是不同的,这个函数有一个重要参数ensure_ascii。Python2.7官方文档对这个参数的解释是:If ensure_ascii is true (the default), all non-ASCII characters in the output are escaped with \uXXXX sequences, and the result is a str instance consisting of ASCII characters only. Ifensure_ascii is false, some chunks written to fp may be unicode instances. This usually happens because the input contains unicode strings or the encoding parameter is used. 因此,在Anaconda Python2.7中,json.dumps(object, ensure_ascii=True)并不能序列化中文对象;但是在IronPython2.7中json.dumps(object, ensure_ascii=True)在多数情况下是可以序列化中文对象的并且返回一个包含\u序列的中文类型,但在少数情况下,如果原始字符串中存在二进制字符,也会抛错,以下是例子:
| Anaconda Python2.7 不支持json.dumps(中文object, ensure_ascii=True) | IronPython2.7 多数情况支持json.dumps(中文object, ensure_ascii=True),个别情况不支持json.dumps(中文object, ensure_ascii=True) |
|
|
例如 TraceId:938e8b9c5289aebba98a81b146982d6a |
[Python3的行为]
Python3中str类型直接变成了class str而不是type str,同时encode的结果直接变成了bytes class,避免了胡乱encode的问题。但是如果想要打印一个中文Object仍然需要json.dumps(中文object, ensure_ascii=False)















 470
470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









