







kv cache原理
kvcache一句话来说就是把每个token在过Transformer时乘以W_K,W_V这俩参数矩阵的结果缓存下来。训练的时候不需要保存。推理解码生成时都是自回归auto-regressive的方式,也就是每次生成一个token,都要依赖之前token的结果。如果没生成一个token的时候乘以W_K,W_V这俩参数矩阵要对所有token都算一遍,代价非常大,所以缓存起来就叫kvcache。
举个例子,假如prompt=“The largest city of China is”,输入是6个tokens,返回是"Shang Hai"这两个tokens。整个生成过程如下:
- 当生成"Shang"之前,kvcache把输入6个tokens都乘以W_K,W_V这两参数矩阵,也就是缓存了6个kv。这时候过self-attention+采样方案(greedy、beam、top k、top p等),得到"Shang"这个token
- 当生成"Shang"之后,再次过transformer的token只有"Shang"这一个token,而不是整个“The largest city of China is Shang”句子,这时再把"Shang"这一个token对应的kvcache和之前6个tokens对应的kvcache拼起来,成为了7个kvcache。"Shang"这一个token和前面6个tokens就可以最终生成"Hai"这个token
为什么有kv cache,没有q cache?
一句话来说q cache并没有用。展开解释就是整个scaled dot production公式 s o f t m a x ( Q K T d k ) V softmax(\frac{QK^T}{\sqrt{d_k}})V softmax(dkQKT)V,每次新多一个Q中的token时,用新多的这个token和所有tokens的K、V去乘就好了,Q cache就成多余的了。再拿刚才例子强调一下,当生成"Shang"之后,再次过transformer的token只有"Shang"这一个token,而不是整个“The largest city of China is Shang”句子
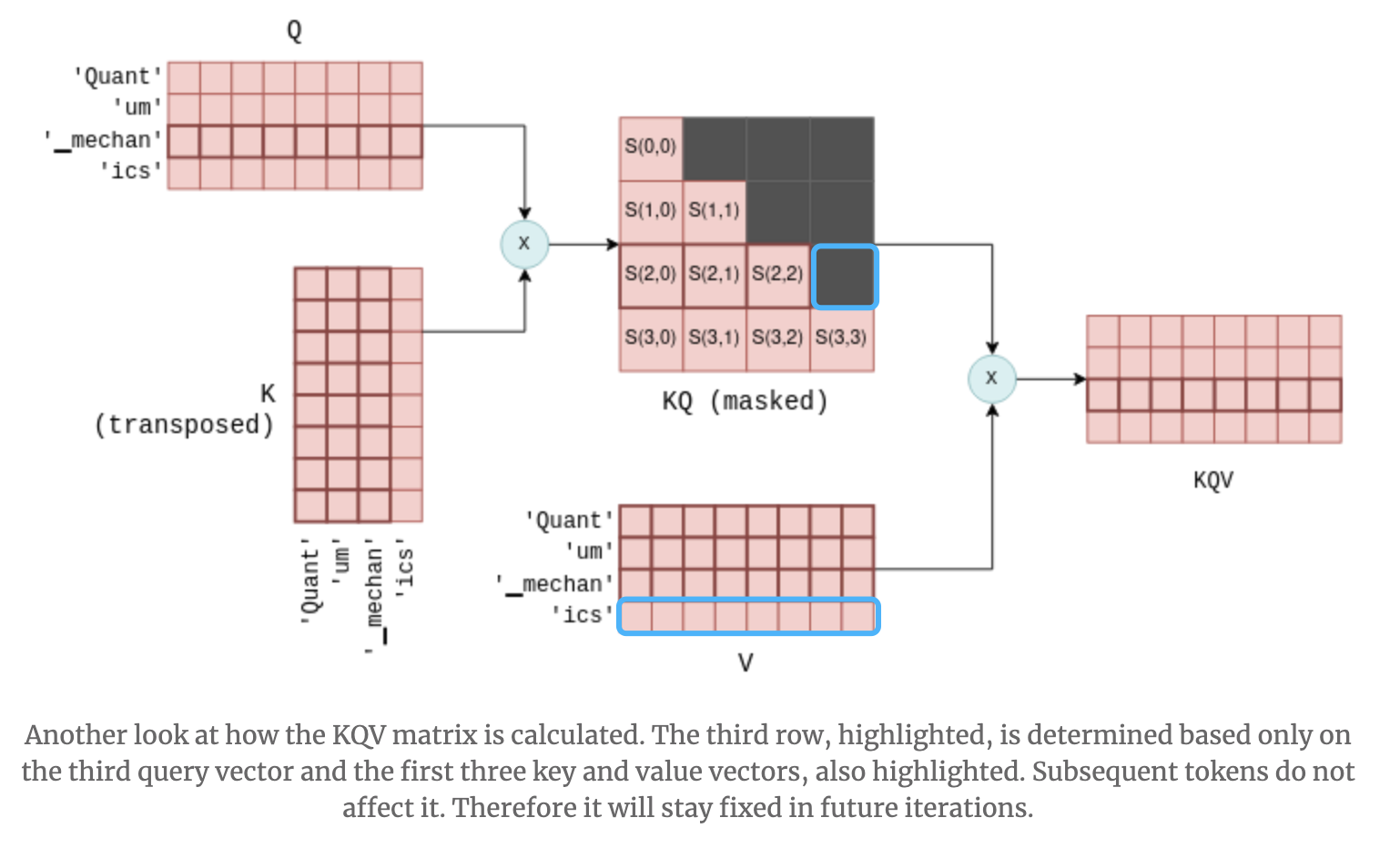
那么问题就又来了,生成"Shang"这个token时,感觉是“The largest city of China is”这6个tokens的query都用了,但是生成"Hai"这个token时,只依赖了"Shang"这个token的query嘛?这个问题其实是没有的,每个token的生成都只依赖前一个Q和之前所有的KV!!!借用https://www.omrimallis.com/posts/understanding-how-llm-inference-works-with-llama-cpp/#further-optimizing-subsequent-iterations里的下图来看:
- 训练的时候’Quant’,‘um’,'_mechan’的下一个token在矩阵乘法时对应的是蓝框,被mask没了
- 推理的时候在给定’Quant’,‘um’,'_mechan’的时候,已有的序列长度是3,矩阵乘法是由图中红框决定的,刚好和未来没读到的蓝框token没有任何关系。同时,‘_mechan’的下一个token只和’_mechan’的Q有关,和’Quant’,'um’的Q是无关的!!!所以每个token的生成都只依赖前一个Q和之前所有的KV,这也是kvcache能work下去的基础!
kv cache参数量估计
假设输入序列的长度为s,输出序列的长度为n,层数为l,以float16来保存KV cache,那么KV cache的峰值显存占用大小为 b ∗ ( s + n ) h ∗ l ∗ 2 ∗ 2 = 4 l h ( s + n ) b*(s+n)h*l*2*2 =4lh(s +n) b∗(s+n)h∗l∗2∗2=4lh(s+n)。这里第一个2表示K/V cache,第个2表示float16占2个bytes。
以GPT3为例,对比KV cache与模型参数占用显存的大小。GPT3模型占用显存大小为350GB。假设批次大小b=64,输入序列长度 =512,输出序列长度n =32,则KV cache占用显存大约为 4 l h ( s + n ) 4lh(s + n) 4lh(s+n)= 164,282,499,072bytes约等于164GB,大约是模型参数显存的0.5倍
提供一个删减版的kvcache代码
class GPT2Attention(nn.Module):
def __init__(self):
super().__init__()
# ...
def forward(
self,
hidden_states: Optional[Tuple[torch.FloatTensor]],
layer_past: Optional[Tuple[torch.Tensor]] = None,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = False,
output_attentions: Optional[bool] = False,
) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]:
# hidden_states对应query
# encoder_hidden_states对应key和value
if encoder_hidden_states is not None:
if not hasattr(self, "q_attn"):
raise ValueError(
"If class is used as cross attention, the weights `q_attn` have to be defined. "
"Please make sure to instantiate class with `GPT2Attention(..., is_cross_attention=True)`."
)
query = self.q_attn(hidden_states)
key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2)
attention_mask = encoder_attention_mask
else:
query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
query = self._split_heads(query, self.num_heads, self.head_dim)
key = self._split_heads 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









