







简单来说,TSN(Temporal Segment Networks)是2D卷积,融合了Temporal(比如光流信息)和Segment(视频抽帧)双流的信息;TSM(Temporal Shift Module)是3D卷积,作者管自己设计的3D卷积方式叫作Temporal Shift Module,可以在效果和开销中间取一定的平衡。
Temporal Segment Networks
论文主要思想仍然是Two-Stream 的结构,以下是算法主要流程图。
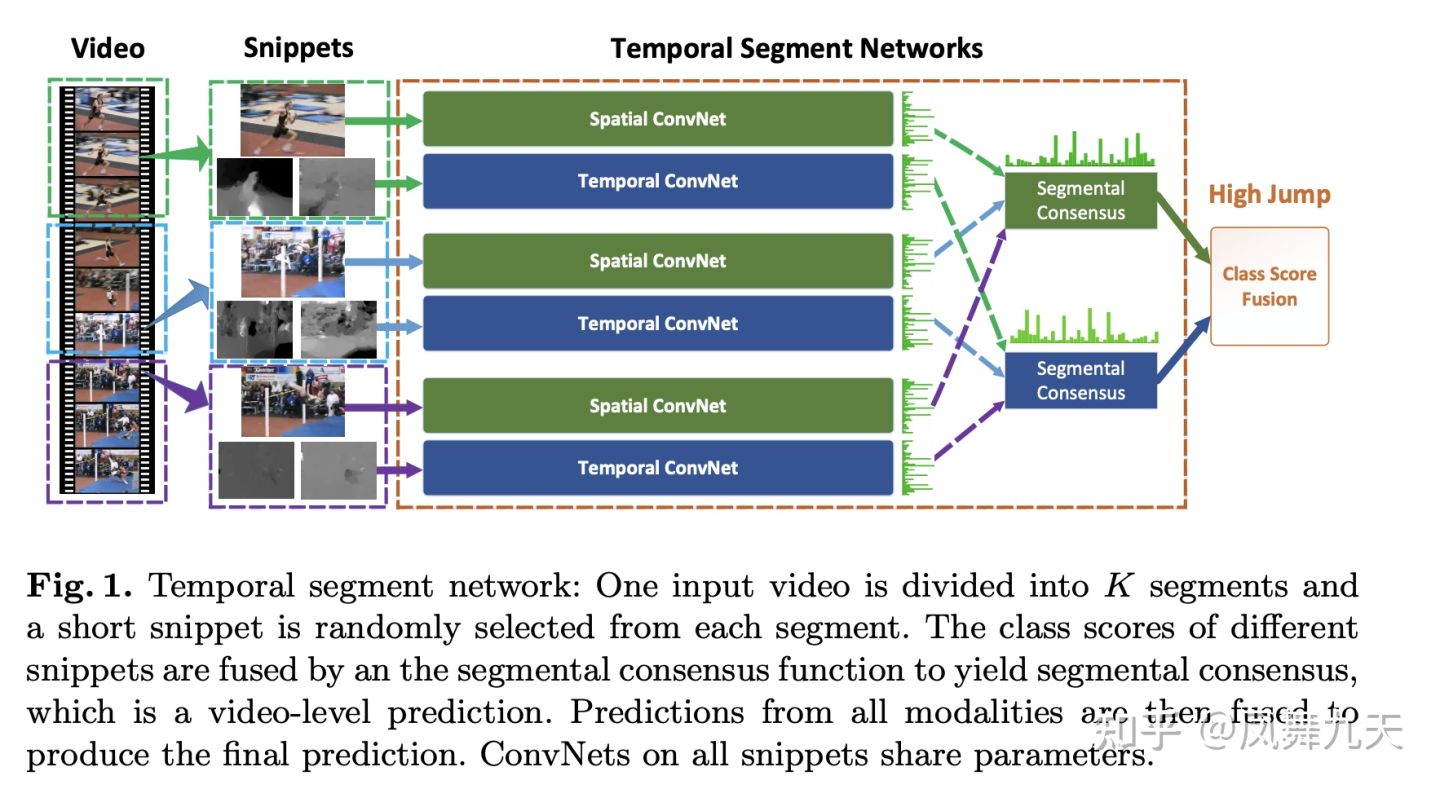
所谓Two-Stream,就是两种输入。TSN的输入除了视频帧(RGB)图像之外,还有视频的光流作为输入,然后两个输入分别过两个不同的卷积神经网络,论文给这两个卷积神经网络分别命名为Spatial ConvNet 和 Temporal ConvNet,只是输入不同。这里多说一下,其实这两个网络可以用同一个网络,参数共享,即不同模态的输入过同一个网络,也可以选择参数不共享,甚至网络结构也可以不同。
个人觉得TSN论文最重要的几点主要包括以下几点,自己业务上的工作主要也是参考了以下几点。
抽帧策略
一段完整的视频,包含的视频帧是非常多的,那么全部处理这些视频帧数据显然是不现实的,所以只能采用抽帧策略,TSN中的抽帧策略,个人感觉比较不错。
在TSN中,视频首先被等间隔分为K个片段,根据视频的时间分布来设置K,比如K=16,即一段视频被分成了16个片段,在每个片段中随机抽取一帧数据作为输入(测试的时需要固定,一般测试的时候可以选择中间帧),这样避免了采用过于连续帧之间的信息冗余,同时又尽可能利用到更多的视频信息。
数据增强
由于数据有限,为了更好的训练模型,作者采用了数据增强,主要包括location jittering, horizontal flipping, corner cropping, and scale jittering,作者通过实验证明了在图像领域常用的数据增强手段,在视频分类的任务中同样有效。
多帧融合
TSN中,作者采用的多帧融合方式比较简单,直接取了平均,后续会介绍更为复杂的视频帧融合的方式。
多模态融合
这里的多模态融合是指RGB输入和光流输入的融合,作者采用的是结果融合。由于这篇论文是16年的文章,所以多模态融合的方式也相对简单,而且多模态还包括视频、文本之间的多模态,后续也会专门讲多模态视频分类。
结果 其中cross-modality pre-training和partial BN with dropout是提升性能的两个技巧,细节在技术细节部分介绍。
Cross-modality pre-training 利用ImageNet预训练模型对双流网络进行初始化。表象分支可以直接用ImageNet预训练模型,而对时序分支,TSN首先把光流离散化到[0, 255]区间,然后把预训练模型第一个卷积层的卷积核沿三个通道方向取平均并重复光流输入帧数这么多次,作为新的一个卷积层的卷积核。实验中发现,这种初始化方法对缓解运动分支过拟合十分有效。
Partial BN with dropout 由于样本较少,TSN将除了第一个之外的所有BN层的均值和标准差参数固定。由于输入数据变化(ImageNet图像->光流),第一层BN的均值和标准差参数没有固定。此外,在GAP之后加dropout,表象分支的dropout ratio为0.8,时序分支的dropout ratio为0.7。
Temporal Shift Module

本文提出的模型叫Temporal Shift Module(TSM),它对时序建模的方式就是shift。上图画出了tensor中的时间维度和通道维度,如图(a)所示,每一行不同的颜色代表着不同的时刻。如图(b)所示,在时间维度上,我们做前后移动,则此时通道维度的一行里就会有其他颜色,这也就代表着对每一帧,我们和附近的帧交换了信息。这个想法虽然听起来简单,但要能想到还是非常大胆的。


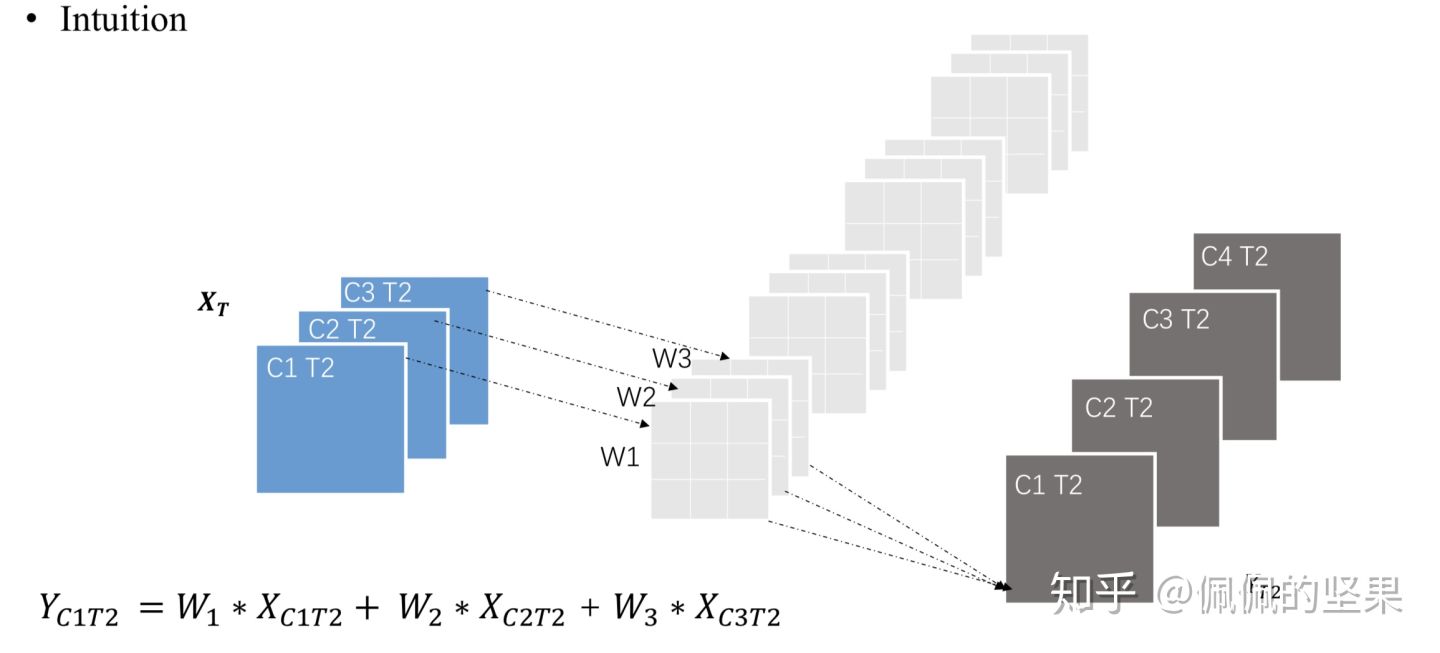


如果我们开始在时序维度上做shift,以T2位当前时间,在它左边的往上移,在它右边的往下移,这时一些通道上就有了其他时刻的信息,式子如上。可见,这相当于时序维度也有了移动、相乘累加的操作,折叠到通道维度里一起做了。虽然这和真正的3D CNN操作有着区别,但在计算时也能看到相邻时刻的信息,进行了时序建模。
谈完了灵感,具体如何进行移动呢?最简单的移动策略是每个通道都移动(naive shift),但这样存在两方面的问题。(1)效率低。虽说移动操作没有增加参数和计算量,但是对于视频这类大规模的数据(5D activation),数据移动所造成的的时延是不可忽略的。(2)准确性差。显然,我们在时序上移动时,把许多相邻帧的信息移动到了当前帧上,当前帧本身的空间结构被打乱了,这就影响了模型的空间建模能力,进而导致结果变差。实验证明,naive shift TSM的方法和2D baseline TSM相比,准确率降低了2.6%。
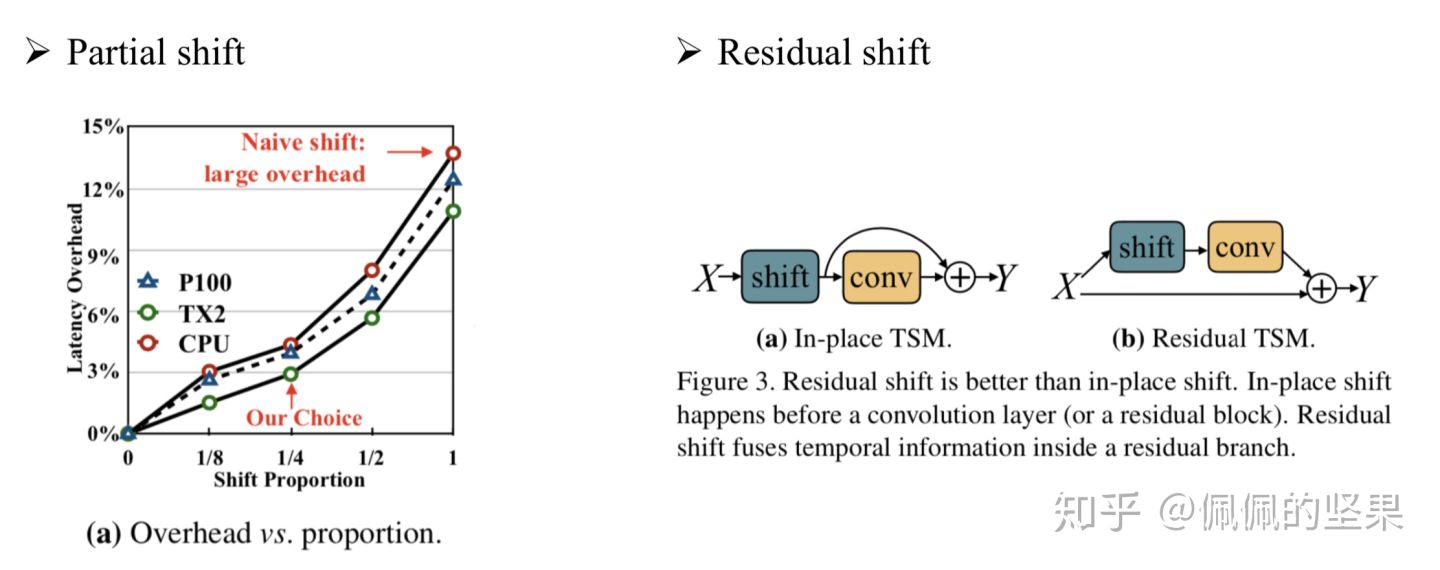
为了解决这两个问题,本文做了两处设计——partial shift 和 residual shift。(1)partial shift。只移动部分通道,如1/4或1/8,至于具体比例多少,需要结合该比例下的时延和准确率进行考量。上面左边的图给出了inference情况下在三种硬件环境下移动不同比例通道的时延。可以看到,在naive shift时(比例为1),时延在CPU上增加了13.7%,在GPU上增加了12.4%,这对于inference来说是不可忽略的。(2)residual shift。本文中的TSM是基于ResNet实现的,往ResNet里加shift,最直接的方法是在每一次卷积或者每一个residual block前做移动,我们称之为In-place TSM。以这种方式做卷积时,移动的操作是丢失了时刻上的空间信息的。因此,我们采取不同的办法,如(b)所示,将shift操作放到残差值中,另一支不动,以保留某一帧原始的空间信息,这样可以避免伤害到原来的2D CNN模型的空间特征学习能力,我们称之为Residual TSM。这里解释一下,为何每个卷积层或block都要做shift,而不是直接在开始就shift后面不再使用。这是因为,每做一次+-1的shift操作,时域上的感受野都会扩大两倍。已知ResNet本身随着网络的加深,空间感受野会越来越大,看到的信息越来越多。要在时序上也模拟这种情况,就得随着网络的加深扩大感受野,相当于让时域上看到的信息也越来越多,以模拟时序卷积的过程。
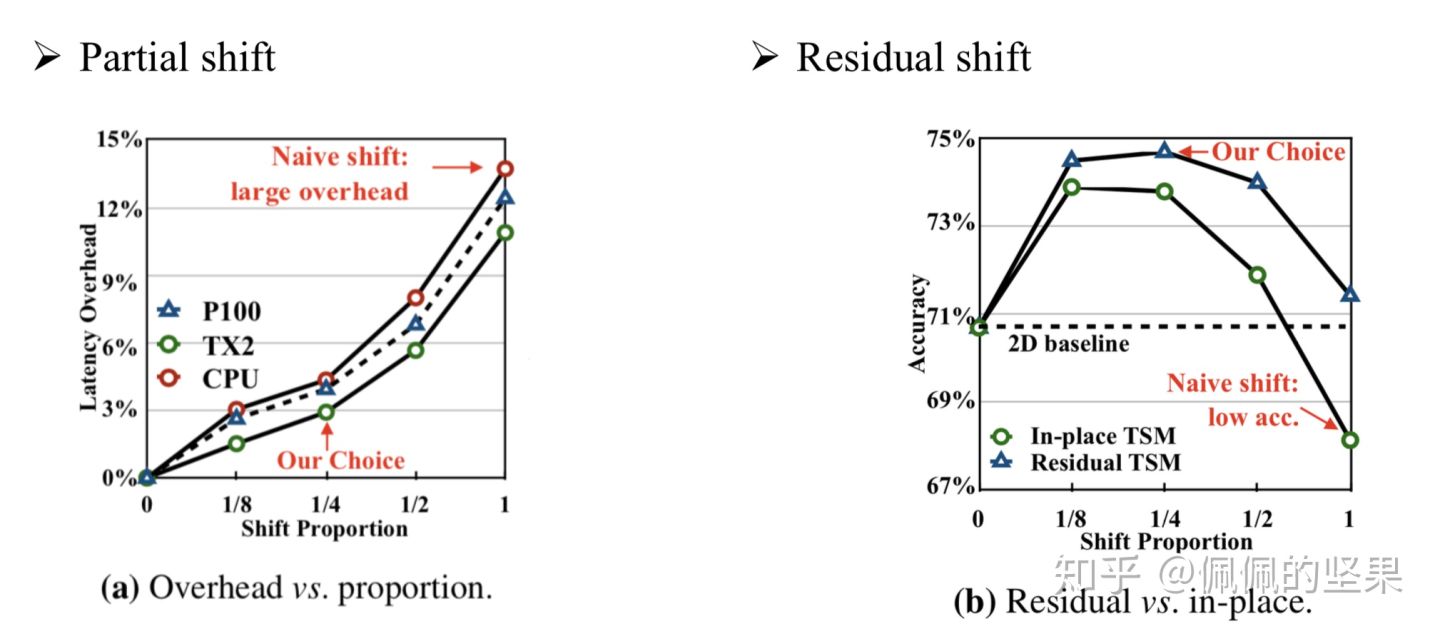
上图(b)比较了In-place TSM和Residual TSM的效果。实验显示,在所有的shift比例上,residual的方式都领先于in-place,并且,即使是做naive shift,它也能比2D baseline TSN好。利用这个实验,我们也可以结合时延实验对shift比例做选择,shift part比例在1/4的时候accuracy效果最好,而此时模型在各种设备上的时延也可以接受,因此后面的实验都是选择移动1/4的比例(1/8 for each direction)。
到这里,模型设计就介绍完了,我们串一下整个视频分类任务的流程。对于一个视频V,抽取T帧作为采样,记为F1,…,FT。在每一帧Fi上,我们都在处理它的2D CNN里加上TSM操作,每个帧得到一个预测的output,再把所有帧的output aggregate起来,可采用average之类的方法,从而得到预测。
SlowFast
1.核心思想
视频行为识别需要从视频中提取鲁邦的外观(空间语义)和运动特征来进行行为识别,所谓SlowFast是指采用Slow和Fast两种采样率的path(输入两个path的是视频采样后的帧)来并行处理视频,Slow path以较低的采样率来处理输入视频(2D卷积+3D卷积),提取随时间变化较慢的外观特征,为了提取鲁邦的外观特征,卷积核的空间通道数较大;Fast path以较高的采样率来处理输入视频(3D卷积),提取随时间变化较快的运动特征,为了降低该通道的复杂度,卷积核的空间通道数较小;然后通过横向连接对两个path的特征进行融合,进行行为识别。
作者文中提了一个“可能比较粗糙且为时尚早的类比”,在灵长类动物的视网膜神经细胞中,有80%的细胞以较低的速率工作,它们对视觉运动变化不敏感,但是可以提供良好的空间和颜色细节(这类比为Slow Path中的卷积核来提取外观特征,总参数量占两个通道总参数的80%左右);剩余20%的细胞以较高速率工作,能够敏感地捕捉运动变化(这类比为Fast Path的卷积核来提取运动特征,总参数占20%左右)。
2.模型结构
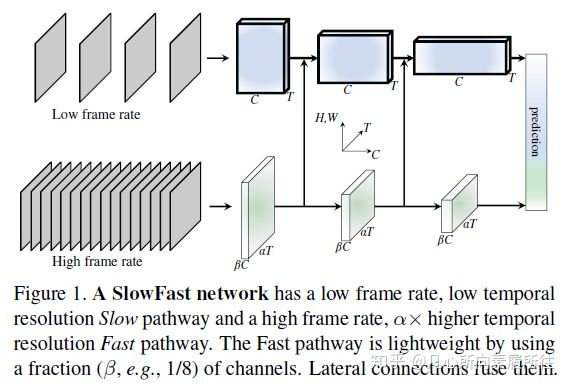
SlowFast模型结构图如上图所示,其主要的工作流程大致如下所示:
step1:用快慢两种速率采样输入视频
step2:采样后的视频帧对应输入到Slow/Fast两个分路
step3:Slow分路使用ResNet 2D Conv + 3D Conv提取视频空间语义特征,size {T,S²,C}
step3:同时Fast分支使用ResNet 3D Conv提取视频时域运动特征,size{αT,S²,βC},其中α>1,β<1
step4:横向连接统一两个分路的特征
step5:Softmax进行分类
详细的流程可以看原文和代码~~~~~~~
3.实验
本文实验相当丰富,还是值得好好看看,学学大佬都是怎么做实验的,实验结果主要是下边几部分:
(1)Kinetics-400数据集SOTA
(2)Kinetics-600新数据集提供了个baseline结果
(3)Fast分支能以很小的代价提高Slow-Only的精度
(4)AVA行为检测
4.与Two Stream、C3D的区别
(1)与Two Stream方法的区别
对行为识别有一定了解的小伙伴应该知道Two Stream方法采用RGB + Optical flow两个通路来分别提取视频的空间语义特征和运动特征进行行为识别,而本文的SlowFast也是两个通路提取两方面特征进行识别,二者的主要区别有如下几个部分:
a:SlowFast更强调两个分路不同的采样和处理速率,这也是SlowFast的核心思想
b:Two Stream两个分路的backbone是相同的,而SlowFast中的Fast分支更轻量级
c:双流是手工设计的特征,无法端到端学习,而SlowFast可以端到端学习两个分路的所有参数
(2)与C3D系列方法的区别
另一种广泛的行为识别方法是C3D及其改进,C3D采用3D卷积同时提取空域和时域特征,SlowFast中虽然也用到了3D卷积,但和C3D行为识别模型是有区别的:
a:C3D模型将2D卷积扩展到时空域,同时处理空域和时域的信息(默认时域和空域是平等的、对称的),而SlowFast采用和TwoStream类似的想法将空域和时域的处理拆分开,这更符合时域和空域特征的关系(二者不应该像一幅图的x,y那样对称处理)
b:SlowFast中用到了3D卷积,但又不太相同。Slow通路前几层使用2D卷积,后两层才用3D卷积(实验发现比全用3D卷积效果更好);Fast通路每一层都用的是3D卷积,但是各层维持时域维度大小不变,尽可能地保留时域信息(而C3D中是越深的层时域维度越小)。















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









