






理论上,大模型可以处理任意长度的问题长度,但受限于GPU显存和算力,过长的文本会使GPU出现OOM内存溢出及耗时过高,用户等待时长过长问题。目前工业界对超长文本的处理,大部分通过RAG的方式处理,也是业界比较流行的,但除RAG外其实也有两大类方法,主要是按是否需要重新对齐大模型的方式分为:不训练LLM大模型和训练LLM大模型参数,其实RAG也算是不需要重新对大模型训练的一种,RAG相关本文就不再赘述。
Learning free 训练LLM大模型
Context Caching在线推理技术
- prefix cache:https://www.53ai.com/news/qianyanjishu/2024070287924.html
- google:https://ai.google.dev/gemini-api/docs/caching?lang=python

- 技术原理:在处理长文本或多轮对话时,经常存在一些不变的前缀部分(如系统提示或历史对话内容),这些前缀在多个请求之间是共享的。Prefix Cache通过缓存这些共享前缀的计算结果(即KV缓存),使得在后续请求中可以直接复用这些结果,而不必重新计算,显著减少了延迟和计算成本。
- 实现Prefix Cache的一种方法是使用Radix Tree(基数树)。基数树允许动态地分割和共享前缀,使得具有共同前缀的请求可以重用相同的KV缓存块。例如,如果两个对话请求共享相同的系统提示,那么这部分的KV缓存就可以被缓存并重用
InfLLM
- git地址:https://github.com/thunlp/InfLLM
- 论文:https://arxiv.org/pdf/2402.04617
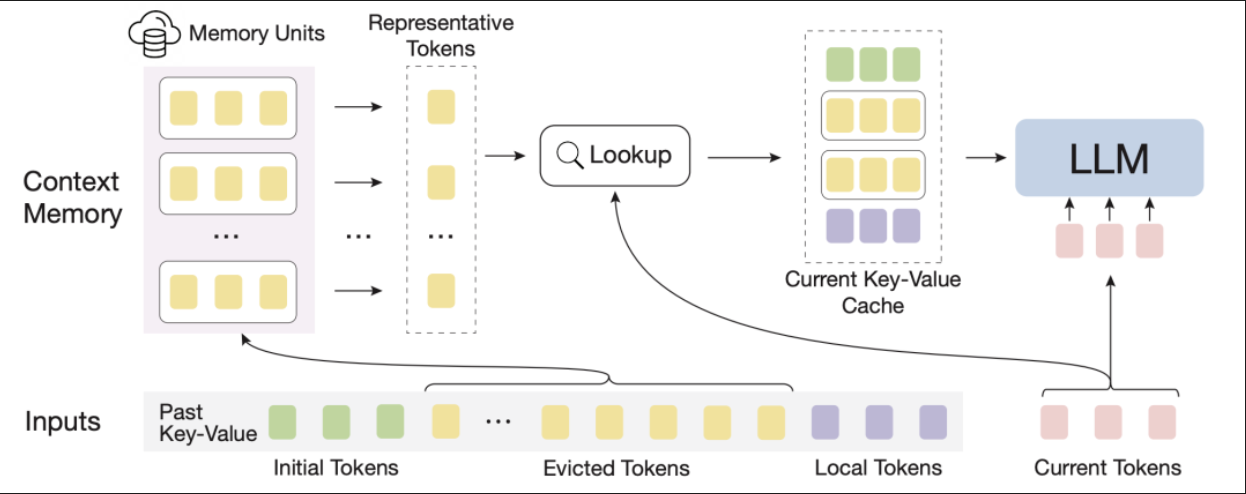
- 超长上下文token分为3类,Initial token、Evicted token、Local token,每次生成下一个token的时,Initial token和一个窗口内的token,Evicted token会分块,检索一部分token出来。如果检索不到,那这个方法就退化为了streaming llm方法
NBCE
苏剑林《NBCE:使用朴素贝叶斯扩展LLM的Context处理长度 》
git地址:https://github.com/bojone/NBCE
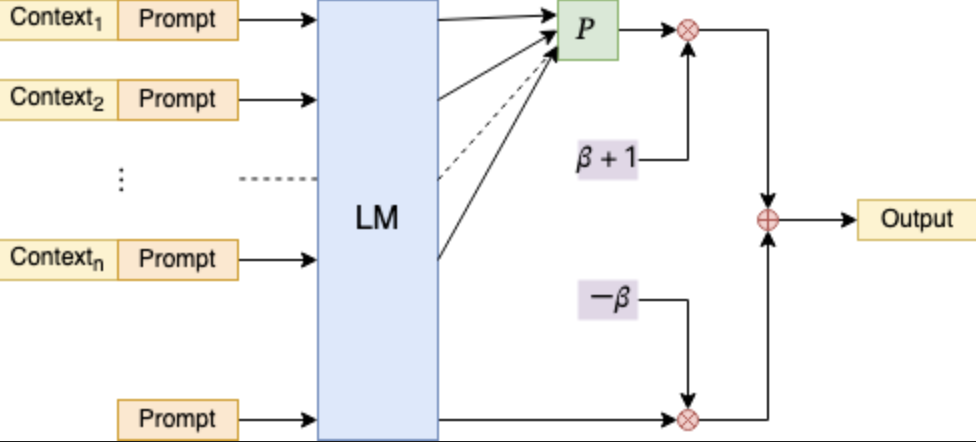
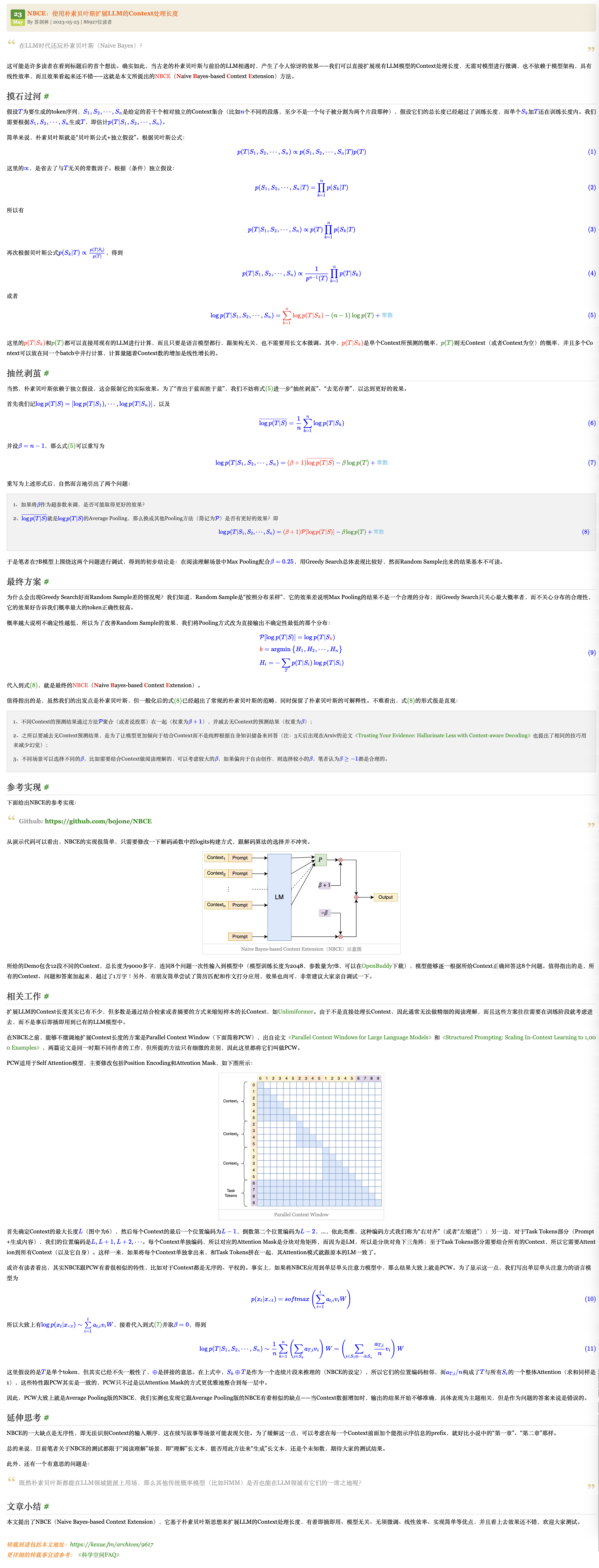
- 对长文本进行分段,对每段上文进行独立编码,在输出层对每一个Step预测token的概率矩阵进行融合,更大程度上避免了注意力被分散,保证了解码的合理性
PCW
Parallel Context Windows for Large Language Models
https://github.com/AI21Labs/Parallel-Context-Windows
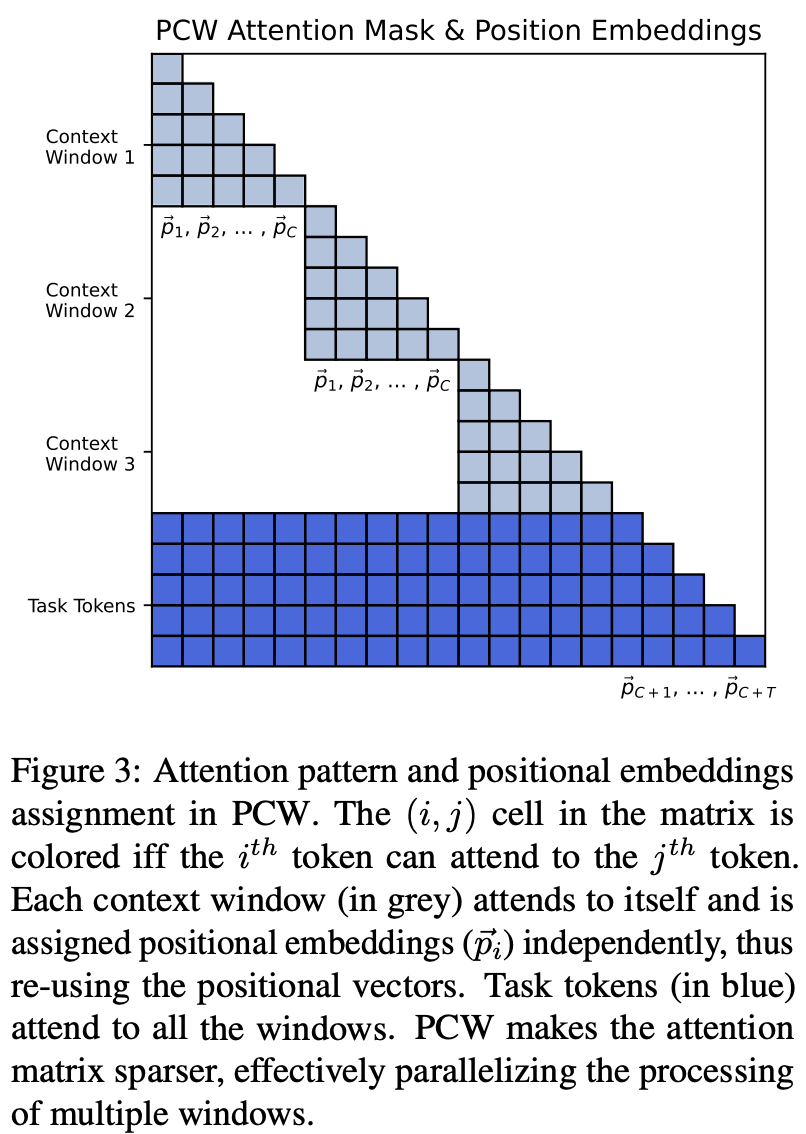
- 对超长文本进行分段,然后独立编码,在解码过程中对全部输入上文进行Attention。对比Encoder-Decoder框架,因为输入和输出都在Decoder侧,PCW需要解决两个问题:位置编码和注意力矩阵如何调整
- 位置编码:输入文本分段后,每段文本的位置编码相同。考虑所最长的文本长度为C,则输入文本最大的位置编码id是pc,则解码器第一个字的位置编码id是pc+1,然后顺序向后编码。其实就是丢弃了上文多段文本之间的位置关系,解码时只知道上文多段文本都是在解码器之前,但无法区分文本之间的位置。不过因为上文每段文本复用了相同的位置编码,因此位置编码的长度大幅降低,也就降低了对位置编码外推性的需求
- 注意力矩阵:输入文本进行分段后各自独立通过进行编码。因此每一段输入的文本的注意力矩阵是相互独立的。这块不需要修改注意力矩阵的实现,只需要文本chunk后分别过模型即可。得到每段文本的past-key-values直接进行拼接
MemGPT
git代码:https://github.com/cpacker/MemGPT.git 论文:https://arxiv.org/pdf/2310.08560
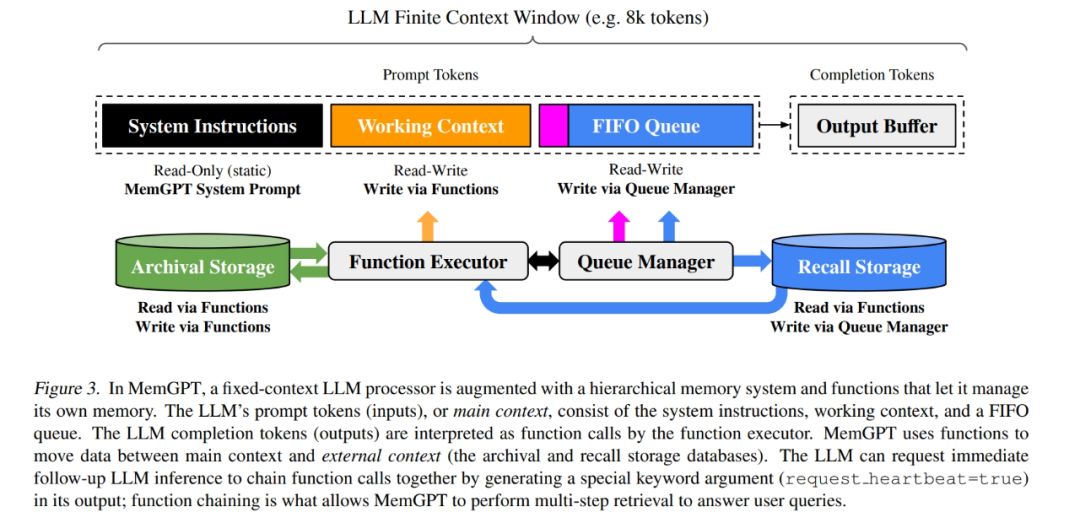
模仿操作系统内存管理管理读写机制,通过在快速和慢速存储器之间智能地移动数据,从而在有限的上下文窗口内提供扩展的上下文。这种设计模仿了传统操作系统的内存层次结构,允许模型在执行单一任务时,通过Prompt方式反复调整其上下文内容,以更高效地利用资源
训练LLM大模型参数
LLOCO
git地址:https://github.com/jeffreysijuntan/lloco 论文:LoCO: Learning Long Contexts Offline
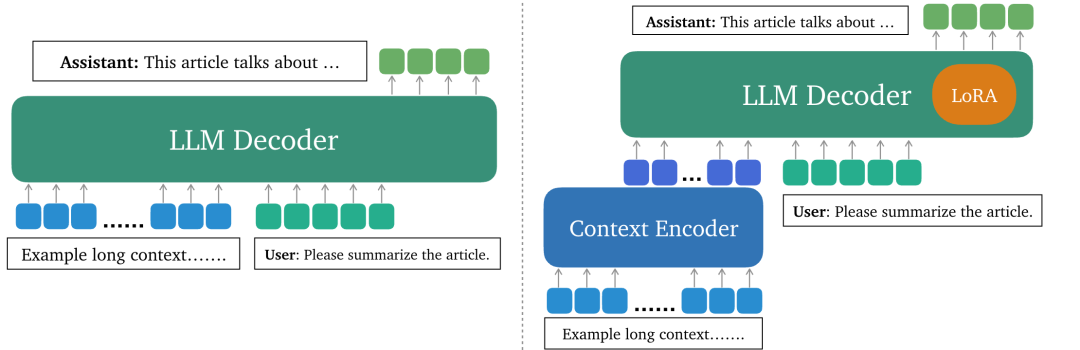
- LLoCO技术包含两个主要部分:上下文编码器和LLM解码器。上下文编码器负责将长篇文本转换成较短的摘要嵌入,这些嵌入能够捕捉原文的核心信息,大大减少模型需要处理的令牌数量。LLM解码器则使用这些摘要嵌入来生成回答。
- LLoCO的工作流程包括三个阶段:预处理、微调和服务:
- 预处理:使用上下文Encoder(如AutoCompressor)将长文档压缩成简短的摘要嵌入。
- 微调:利用LoRA(Low-Rank Adaptation)技术对压缩后的“作弊纸”进行参数高效的微调。
- 服务:使用标准的RAG(Retrieval-Augmented Generation)检索器检索压缩后的文档和最相关的LoRA模块,并将它们应用于LLM进行推理。
ICAE(上下文自动编码器)
git地址:https://github.com/getao/icae 论文:https://yiyibooks.cn/arxiv/2307.06945v3/index.html
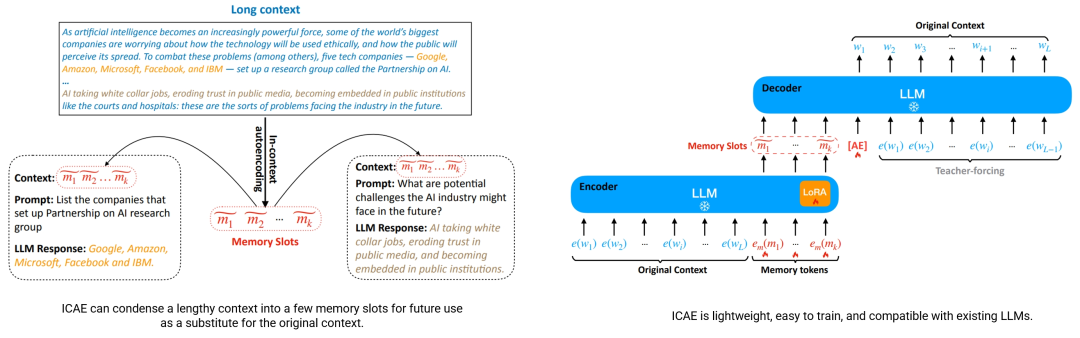
- 将长文本压缩成较短的、紧凑的内存槽位,使LLM能够在各种任务中直接使用这些内存槽位。ICAE首先在大量文本数据上使用自动编码和语言建模目标进行预训练,使其能够生成准确且全面地代表原始上下文的内存槽位。然后,在指令数据上进行微调,以产生对各种提示的理想响应。实验表明,ICAE在基于Llama模型的基础上,引入了约1%的额外参数,有效实现了4倍上下文压缩,在推理期间提高了延迟和GPU内存成本,并展示了记忆方面的有趣见解以及可扩展性潜力
- ICAE模型的架构包括两个主要模块:
- 编码器:可学习的编码器,使用LoRA技术从LLM中适应而来,用于将长上下文压缩成少量内存槽位。
- 解码器:固定解码器即目标LLM本身,能够根据内存槽位进行各种任务的条件处理。
- 在预训练阶段,ICAE使用自动编码和语言建模目标,通过大量文本数据进行训练,以生成能够准确、全面地表示原始上下文的内存槽位。预训练有助于模型泛化,使生成的内存槽位能够更准确、全面地代表原始上下文。然后,通过在指令数据上的微调,增强其与各种提示的交互,以产生理想的响应
MemLong
git地址:https://github.com/Bui1dMySea/MemLong 博客:https://avoid.overfit.cn/post/886d820cba6240bfb005e4c2378fe2e8
论文:https://arxiv.org/abs/2408.16967
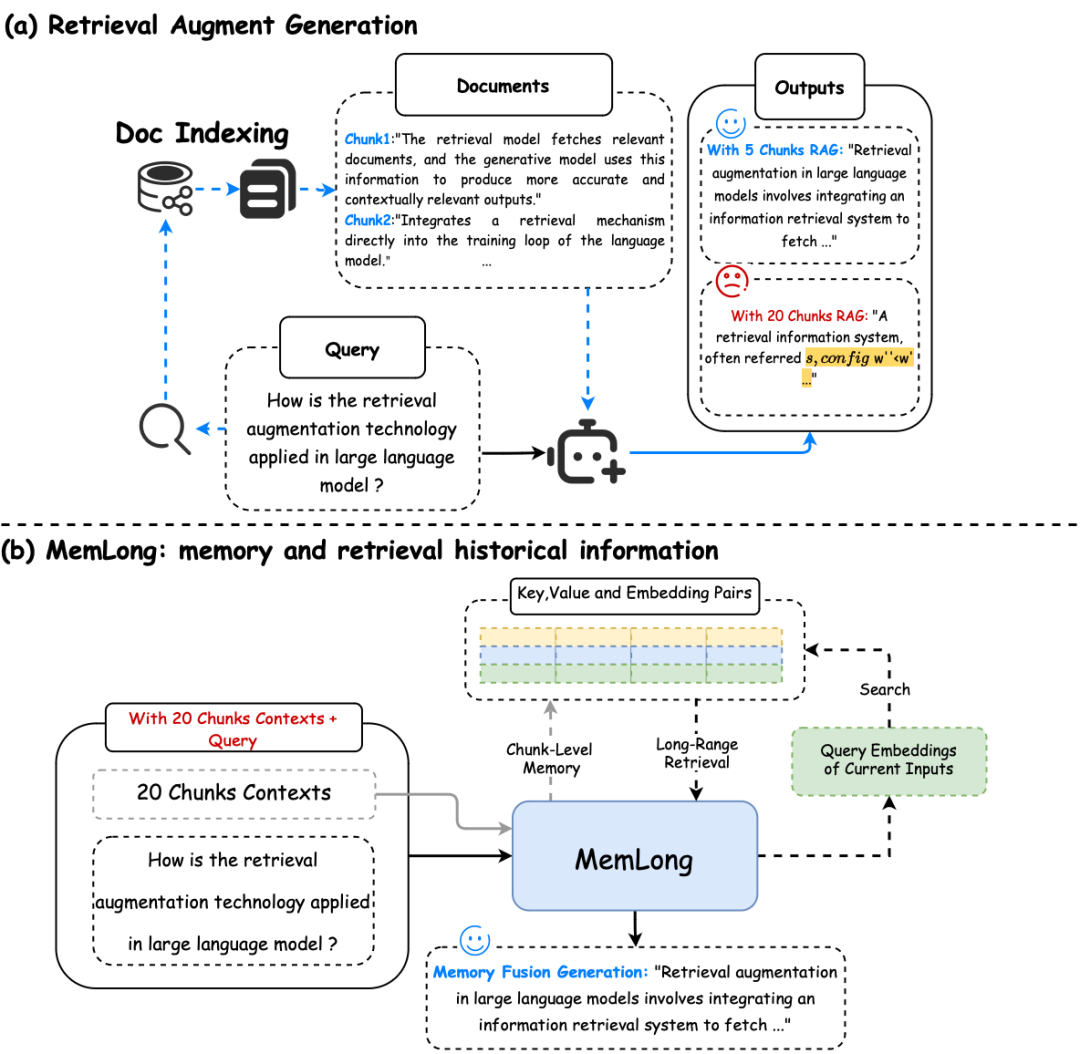
- 利用外部检索器来检索历史信息,从而提升上下文语言建模的能力。MemLong结合了一个不可微分的"ret-mem"模块和部分可训练的解码器语言模型,并引入了细粒度、可控的检索注意力机制,利用语义级相关块
- 核心思想是将过去的上下文和知识存储在非训练的记忆库中,并利用这些存储的嵌入来检索块级key-value(K-V)对输入模型。这种方法允许模型在处理长文本时能够"回顾"之前的内容,类似于人类在阅读长文档时会不时回顾前面的章节
- 大概流程
- 输入分块:将超过模型最大处理长度的输入文本分为前缀和主体。
- 记忆过程:对前缀部分进行编码和存储,每个固定大小的块都会被编码并存储其K-V对和检索表示。
- 检索过程:在处理主体部分时,对每个当前上下文块进行编码,并与存储的历史信息计算相似度,检索最相关的历史块。
- 注意力重构:在模型上层引入检索因果注意力机制,融合局部上下文和检索到的块级历史信息。
隐式搜索:Unlimiformer
Unlimiformer: Long-Range Transformers with Unlimited Length Input https://github.com/abertsch72/unlimiformer 适用于Encoder-Decoder模型,长文本摘要等场景
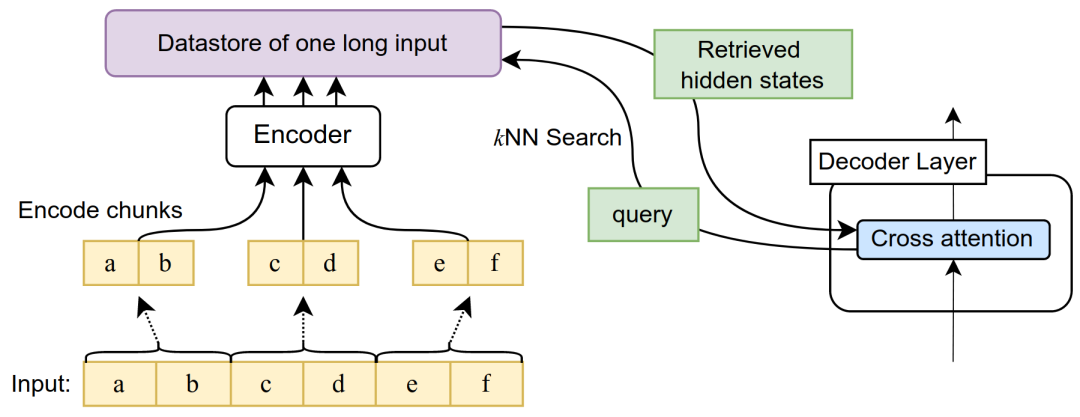
- 采用预训练的Encoder-Decoder架构的Transformer模型处理无限长度的输入序列。通过将注意力计算外包给一个k-最近邻(kNN)索引来实现,该索引可以存储在GPU或CPU内存中,并以亚线性时间查询,从而允许索引几乎无限的输入序列。在每个解码器层中,每个注意力头检索其顶部k个键,而不是关注每个键。Unlimiformer在几个长文档和书籍摘要基准测试中得到了评估,展示了它能够处理来自BookSum数据集的长达500k个token的输入,而无需在测试时截断输入。此外,Unlimiformer通过扩展它们到无限输入,无需额外的学习权重,无需修改代码,就提高了像BART和Longformer这样的预训练模型的性能
关键组成部分包括:- 编码(Encoding):超长输入序列被编码并存储在数据存储器中,使用类似Faiss的库进行索引。检索增强的交叉注意力(Retrieval-augmented Cross-Attention):在标准的交叉注意力之上进行改进,允许解码器不仅仅关注编码器输入序列的前k个token,而是检索整个输入序列中的top-k个hidden states,然后对这些top-k的hidden states进行attention计算。
- 注意力重构(Attention Reformulation):通过重新构思传统的注意力计算方法,允许每个注意力头在每个解码步骤中从完整的输入序列中选择一个独立的上下文窗口
AutoCompress
git 代码:https://github.com/princeton-nlp/AutoCompressors?tab=readme-ov-file
论文:https://arxiv.org/pdf/2305.14788

- 长文本上下文压缩成紧凑的摘要向量,这些向量随后可以作为软提示(soft prompts)供模型使用。通过这种方式,模型能够处理超出其原始上下文窗口的长文本。
- 无监督训练目标:通过无监督的方式训练摘要向量,即将长文档分割成多个部分,并将之前部分的摘要向量用于语言建模。
- 摘要向量:AutoCompressor在基础模型的输入词汇表中增加了特殊的摘要标记,并初始化了新的输入Embedding。当这些摘要标记附加到输入序列上时,模型被引导输出前文的特别摘要向量。
- 摘要累积:通过串联所有先前段的摘要向量来形成整个文档的摘要。
随机分割:长文档被分割成多个部分,然后顺序处理,每部分处理时都会将之前部分的摘要向量用于语言建模。
附录
https://kexue.fm/archives/9617
https://kexue.fm/archives/9632


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









