






 在开发私有ChatGPT时,使用官方基础模型可能无法满足预设答案。通过OpenAIAPI提供的训练方法,可以使用自定义数据进行模型微调。文章介绍了安装相关工具,设置环境变量,准备和格式化数据,以及如何进行模型创建和微调的步骤。在微调过程中,需要注意数据的质量和数量,以及正确设置停止令牌。完成微调后,可以使用新模型进行交互。
在开发私有ChatGPT时,使用官方基础模型可能无法满足预设答案。通过OpenAIAPI提供的训练方法,可以使用自定义数据进行模型微调。文章介绍了安装相关工具,设置环境变量,准备和格式化数据,以及如何进行模型创建和微调的步骤。在微调过程中,需要注意数据的质量和数量,以及正确设置停止令牌。完成微调后,可以使用新模型进行交互。
在开发私有chatGPT的时候,如果我们使用官方的基础模型,那么回答的问题可能不符合我们自己的预设答案
现在就是通过官方的训练方法,提供一部分数据进去,训练出自己的私有模型
按照工具
pip install --upgrade openai
设置环境变量
export OPENAI_API_KEY="自己的key"
准备本地数据
{"prompt": "你是谁", "completion": "我是唯一客服小助手"}
{"prompt": "你会做什么", "completion": "我能帮你解答使用唯一客服时的问题"}
格式化数据
openai tools fine_tunes.prepare_data -f /tmp/json.txt
如果报错
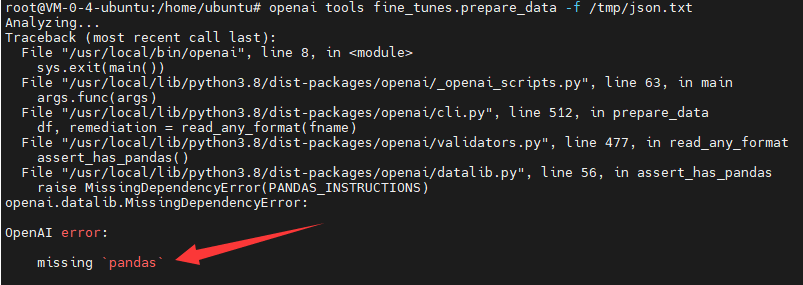
执行
pip install pandas
然后继续执行,他会给出一些格式化的建议
翻译一下
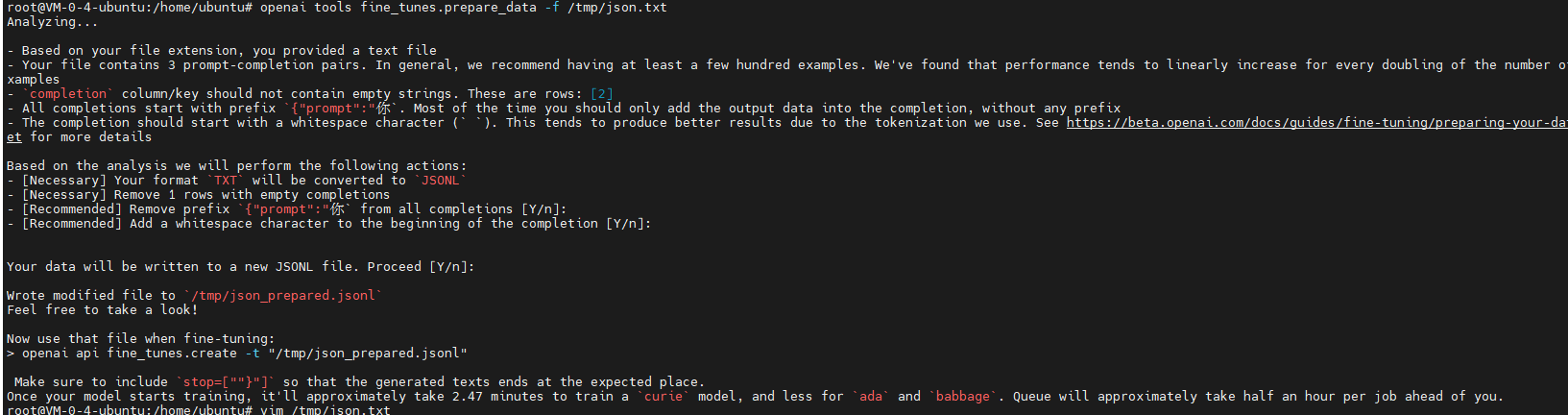
正在分析。。。
-根据您的文件扩展名,您提供了一个文本文件
-您的文件包含3个提示完成对。一般来说,我们建议至少有几百个例子。我们发现,示例数量每增加一倍,性能就会线性增加
-“completion”列/键不应包含空字符串。这些是行:[2]
-所有完成都以前缀“{”prompt“:”开头你`. 大多数情况下,您应该只将输出数据添加到完成中,而不添加任何前缀
-完成应该以空白字符(``)开头。由于我们使用的标记化,这往往会产生更好的结果。看见https://beta.openai.com/docs/guides/fine-tuning/preparing-your-dataset有关详细信息
根据分析,我们将采取以下措施:
-[必要]您的格式“TXT”将转换为“JSONL”`
-[必要]删除1行空白完成符
-[推荐]删除前缀“{”prompt“:”你` 来自所有完成[Y/n]:
-[推荐]在完成开头添加空白字符[Y/n]:
您的数据将写入新的JSONL文件。继续[Y/n]:
将修改后的文件写入`/tmp/json_prepared.jsonl`
随便看一看!
现在在微调时使用该文件:
>openai api fine_tunes.create-t“/tmp/jsonprepared.jsonl”
确保包含`stop=[“”}“]`,以便生成的文本在预期位置结束。
一旦你的模型开始训练,训练一个“curie”模型大约需要2.47分钟,而“ada”和“babbage”则需要更少的时间。在您之前,每个作业排队大约需要半小时。
创建一个微调模型
基于达芬奇模型,创建一个自己的模型
openai api fine_tunes.create -t 数据文件路径 -m 基础模型

这个时候会让等几分钟或者几个小时哦
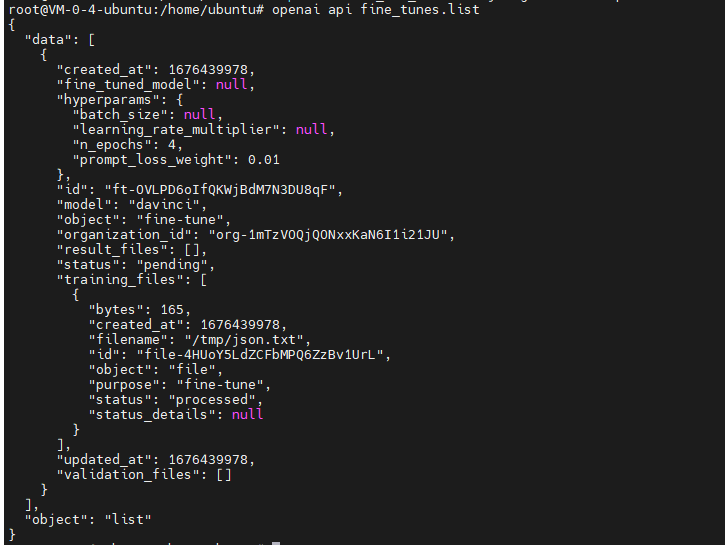
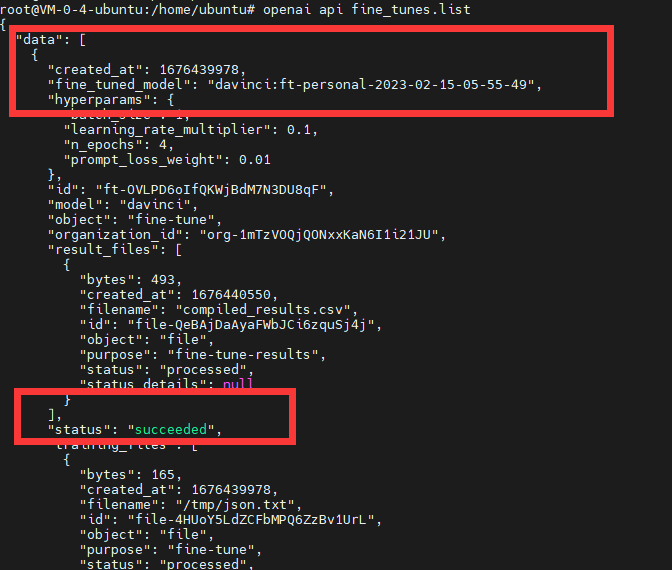
列出所有微调任务的列表
openai api fine_tunes.list
查看微调任务的状态,ID就是上面列表的ID,可以看到正在运行中
openai api fine_tunes.get -i 任务ID
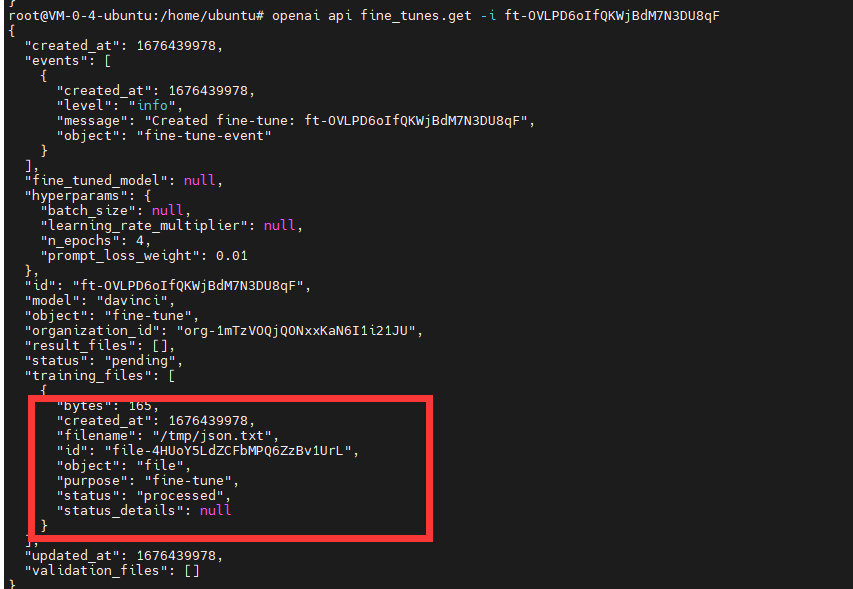
当任务完成以后,fine_tuned_model 字敦会有模型名称
后面就可以使用这个模型了,可以看到模型名称
使用模型
openai api completions.create -m 模型名称 -p 提示

















 2654
2654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









