






目录
1.介绍
以往的方法大多使用多实例学习(MIL),就是通过对未修剪视频进行分类,来达到对其中视频片段的预测。本文认为将视频中片段视为独立的实例是错误的,他们之间有时间上的联系,比如片段内部和片段之间。本文提出一个ASM-loc结构,以动作提议的片段为焦点,包含三个模块:
- 动态段采样(dynamic segment sampling)以补充短时动作片段的作用
- 段内和段间的注意力,建模动作动态和捕获时间依赖
- 伪实例级监督,提高动作边界的预测
除此以外,提出了多步细化策略,在模型训练的过程中逐步改进动作提议
2.基础模型
2.1 特征提取和建模
与以往的弱监督时间动作定位一样,对未修剪的视频分割为不重叠的包含16帧的片段,输入到Kinetics-400预训练的I3D网络中得到RGB和光流特征,得到 F ∈ RT*D ,之后进行时间卷积和ReLU,得到 X = ReLU(conv(F))
2.2 动作预测和损失函数
对于X,经过FC层得到类激活序列CAS,P ∈ RT*(C+1) ,C+1指C个动作类和一个背景类。更好地区分前景和背景片段,引入了一个注意力模块,X同样通过FC层,在时间维度上进行softmax得到一个注意力权重A ∈ RT*2,注意权重A与CAS结合,得到 P ^ \hat{P} P^m ( c ) = P( c )⊙Am, m ∈ {fg, bg},最后生成视频级分类分数
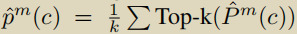
当然,这步之后肯定要进行softmax的。注意一点,这里的p是有两个的,m ∈ {fg, bg}对应前景和背景
前景损失
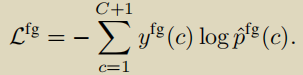
前景分类分数和真值得到交叉熵损失
背景损失
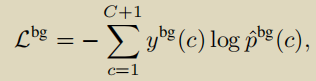
除了c=C+1时ybg (c)=1,其他都为0
背景感知动作损失
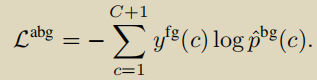
尽管在背景片段中没有发生任何动作,但仍然有丰富的上下文信息来反映实际的动作类别。
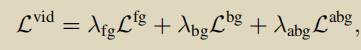
3.动作感知片段建模
此部分是本文的核心,包括动态段采样,段内段间注意力,伪实例级监督。
3.1 Dynamic Segment Sampling
直觉上来看,在目标检测中,物体体积越小越难以检测,对于时间动作定位同样如此,短时动作也难以被检测,所以此部分方法的作用是增强短时动作片段。
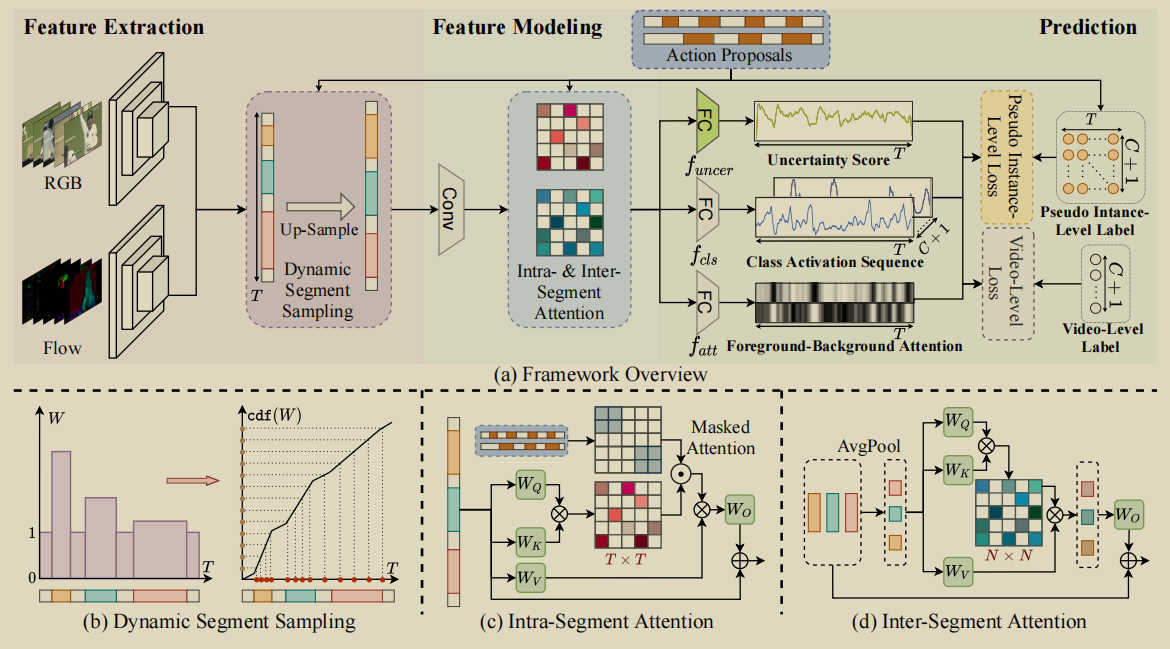
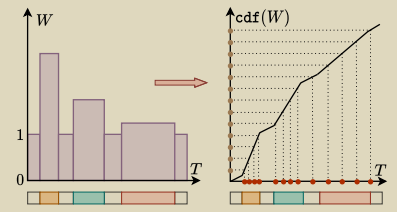
首先初始化一个采样权重W ∈ RT ,值全部为1,给定一个预定义的阈值γ
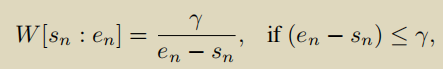
对动作片段持续时间小于阈值的,采样权重进行扩大。
之后对W计算累积发布函数fW = cdf(W) ,在cdf(W)上进行均匀采样,对应的T也会采样到片段,从而达到扩大短时动作片段的效果。
3.2 Intra- and Inter-Segment Attention
段内注意力
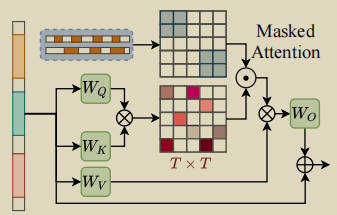
对于注意力掩膜 M ∈ RT*T ,首先全部初始化为0,对M[s:e,s:e] =1 ,就是对具有动作片段的部分赋值1。
最后进行注意力操作
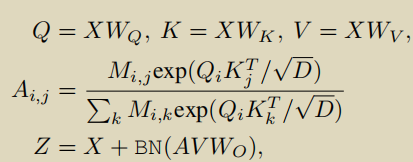
A本质上就是softmax(M* Q * KT /
D
\sqrt{D}
D),自注意力是snippet之间的关系,M的作用是屏蔽掉背景片段的部分,以及不是相同动作实例的片段。
段间注意力
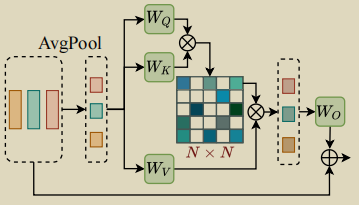
与段内注意力的计算方式很像,首先计算不同的动作实例平均池化,
X
^
\hat{X}
X^n 指第n个动作实例池化后的结果,shape为1*D,总共有N个动作实例,故最后得到片段级特征 {
X
^
\hat{X}
X^n }1N∈ RN*D
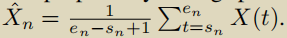
得到
X
^
\hat{X}
X^之后,分别计算Q=
X
^
\hat{X}
X^WQ ,K=
X
^
\hat{X}
X^WK,V=
X
^
\hat{X}
X^WV
段间注意力A=softmax(Q * KT /
D
\sqrt{D}
D),输出为 Z=X+BN(AVWO)。
注意一点,特征BN(AVWO)是在时间维度上进行复制,从N * D到T * D,最后加到原始特征上的。
3.3 Pseudo Instance-level Loss
伪实例级监督实际上是一种作弊手法,通过之前得到的动作提议,作为伪标签,这种监督方式比视频级监督更细粒度,进一步细化动作边界。
伪标签
Q
^
\hat{Q}
Q^ ∈ RT×(C+1) , 由于它起的是标签的作用,根据得到的动作提议,在对应时间段的动作类别部分赋值为1 ,在所有背景时间段的C+1赋值为1,其余位置都为0
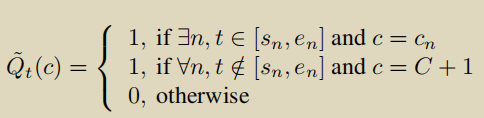
为了引导模型从有噪声的伪标签中学习,引入了一个不确定性模块,其实就是X经过一个FC得到不确定性分数U∈ RT ,具有高不确定性分数的实例对损失的贡献小,并且希望不确定性分数不能增长的太过分,损失后加了权重衰减。
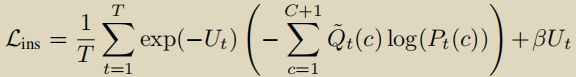
3.4 Multi-step Proposal Refinement
由于上面的每个模块都要用到动作提议,因此动作提议的质量是至关重要的,与模块性能呈正相关。
简单说一下,就是先训练E个epoch得到初始动作提议
S
^
\hat{S}
S^0 ,之后每隔E个epoch更新一下
S
^
\hat{S}
S^,更新次数L后,就使用
S
^
\hat{S}
S^L 作为最终的动作提议来训练模型,直到模型收敛。














 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









