






主要贡献
1.提出一个动态片段采样模块,主要针对弥补短的动作片段语义信息不够的情况
2.利用片段内和片段间的注意力机制来动态捕捉片段的时序依赖性质
3.提出伪实例级别标签来提升动作边界的预测。
提出了一个多层级的提取策略来训练整个模型网络
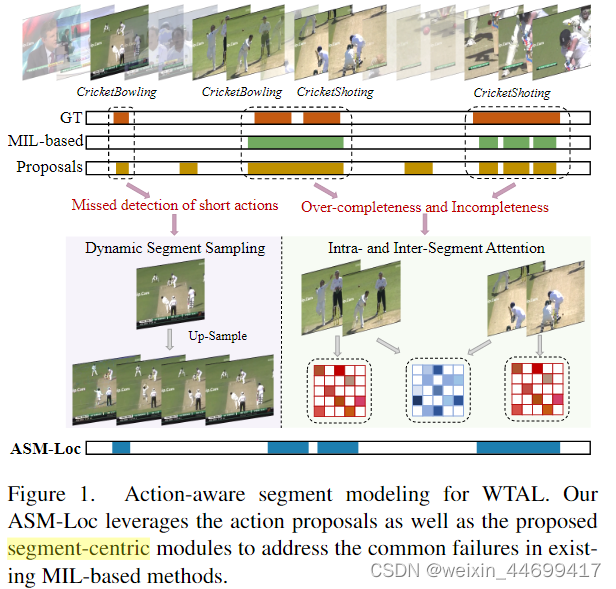
指出现有的弱监督TAL方法的缺点:1.定位完整性:由于缺乏视频级别的标签(定位)模型往往生成不完整的或者过于长的动作片段proposal
2.对于长度较短的动作片段,经常会出现漏检的情况,因为整个模型对于较短的视频片段往往会倾向于给更低的置信度分数。
作者认为现有的方法缺乏segment-based建模是现在性能较低的主要原因。
Foreground loss
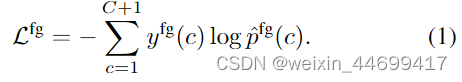
Background loss


Action-aware background loss
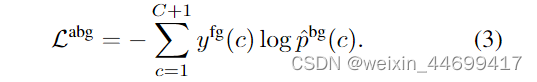
设置一个新的loss函数,用来反应一种现象:例如桌球这个动作,不属于动作帧会有一张台球桌的语义信息,这个语义信息足够使模型识别出来桌球这个动作。
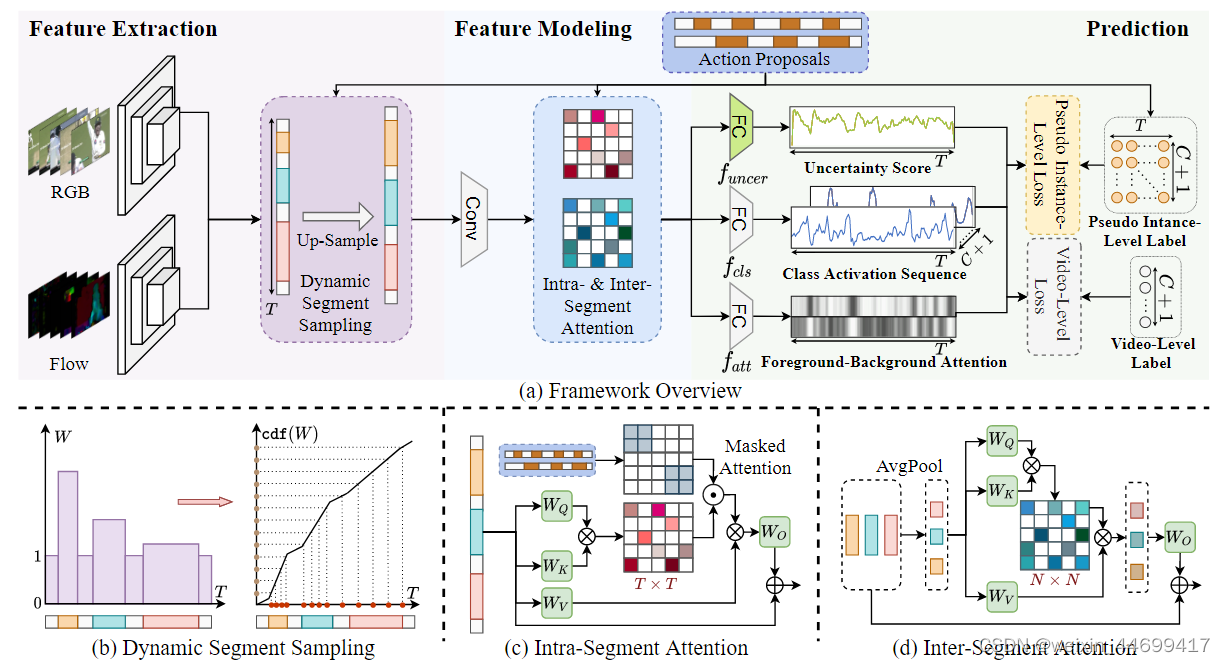
Dynamic Segment Sampling
问题:在WTAL中,时长较短的动作segment由于模型的bias尝尝被赋予较低的置信度分数,这就造成了动作检测和定位的错误。
解决方案:
动态上采样方案:
第一步:初始化采样权重 w = 1 对每个时间t来说
第二步:当一个视频proposal的长度小于gamma,给它重新赋予权重
s,e代表开始和结束,
计算出来
之后用它的倒数对整个片段进行均采样,需要上采样的地方,使用线性插值。
Intra- and Inter-Segment Attention
如果对整个视频片段使用注意力机制的话,那么会因背景产生额外的噪音,因此在片段内部使用注意力机制更好一点。
Intra-Attention
视频中很多动作是有关系的把比如CricketBowling和CricketShotting都是接连出现的,因此使用inter-attention捕捉这种依赖是对模型有帮助的。
Inter-attention
Pseudo Instance-level loss
实例级别的损失构成:
1.先生成实例级别的标签
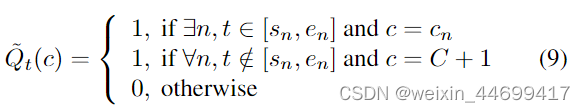
uncertainty score让noisy大的instance 对loss贡献减少
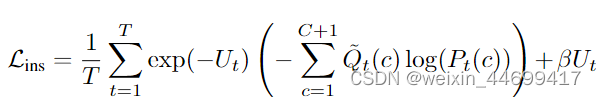
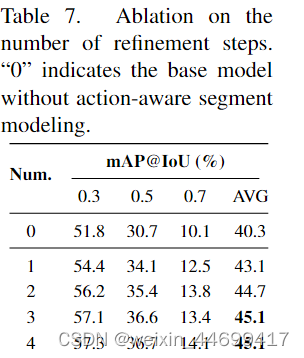
Multi-step Proposal Refinement

消融实验1,验证各个模块的有效性, DSS +1.1 intra-attention +1.5 inter-attention +1.7 Lins +1.0
并且看起来提出的模块都是互补的,开始我自己认为intra-inter可能会有冲突。
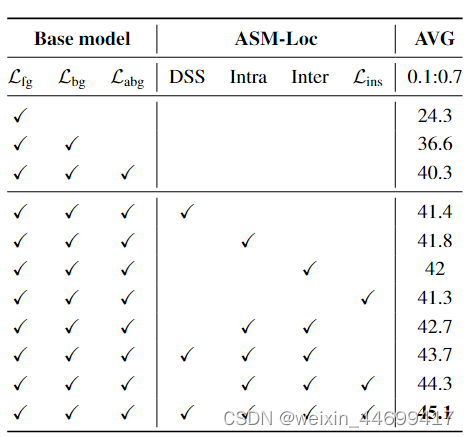
并且还对比了global对模型的伤害,这点对我是有一定启发的
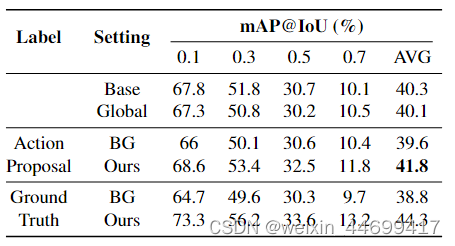
验证动态采样策略带来的提升,在baseline性能上发现xs目标的性能提升了很多。这点也很有意思。

不确定分数的消融实验,感觉可以当作一个trick

proporsal refinement,虽然没跑代码但是感觉这个模块的提升好大。















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









