






目录
论文地址: VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
1.介绍
本文提出了视频遮挡自动编码器是自监督视频预训练的高效数据学习者,受到ImageMAE的启发,提出了极高比例遮挡的video tube。极高的遮挡比例使得原本简单的任务变得更具有挑战性,从而促使在预训练过程中获得更有效的视频表示。
VideoMAE继承了 masking random cubes和reconstructing the missing ones的简单管道,视频的时间维度使它们不同于图像中的遮挡。
- 首先,视频帧通常被密集地捕获,它们的语义随时间变化缓慢,这种时间冗余会增加从时空邻域中恢复缺失立方体的风险,而缺乏高水平的理解。
- 此外,视频可以看作是静态外观的时间变化,帧之间存在对应关系,这种时间相关性可能会导致重构过程中的信息泄漏(被掩蔽的时空内容再次出现),对于每个被遮挡的立方体,很容易在相邻的帧中找到一个相应的未被遮挡的副本。
本文的贡献如下:
- 提出了第一个在相对小规模的视频数据集上表现良好的SSVP的遮挡视频自动编码器。提出了一种极高比例的遮挡设计,从而有效地提高了VideoMAE的性能。
- VideoMAE预训练的模型明显优于那些从头开始训练或用对比学习方法预训练的模型
- 本文的研究结果表明,VideoMAE是一个数据效率很高的学习方案,只需3.5k视频就可以成功地进行训练。当源数据集和目标数据集之间存在域的移位时,SSVP的数据质量比数量更重要。
2.方法
2.1 Masked Autoencoders
ImageMAE使用非对称编码器-解码器架构执行遮挡和重建任务。输入图像首先划分为大小为16×16的非重叠patch,每个patch用token嵌入表示。然后,以高遮挡率(75%)随机遮挡 token子集,并且仅剩下的token输入到 Transformer编码器。最后,将浅层解码器放置在编码器的可见token和可学习遮挡token的顶部,以重建图像。损失函数是像素空间中归一化遮挡token和重建的token之间的均方误差(MSE)损失:
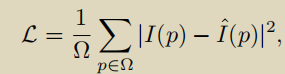
Ω 是遮挡的token集合,
I
I
I是输入也就是真值,
I
^
\hat{I}
I^是重建之后的.
2.2 视频特征分析
temporal redundancy
从视频中密集捕获视频帧,视频帧语义随时间变化缓慢。作者观察到,连续帧是高度冗余的。这个特性导致了遮挡视频自动编码中的两个关键问题。首先,如果在预训练保持原始的时间帧率,那么效率就会降低。这将促使作者在遮挡建模中更多地关注静态或慢速运动。其次,时间冗余性大大稀释了运动表示,这将使重建缺失像素的任务在正常遮挡率(例如,50%到75%)下不存在困难,编码器主干无法有效捕获运动表示。
temporal correlation
视频可视为静态外观的时间扩展,因此相邻帧之间存在固有的对应关系。这种时间相关性可能会增加遮挡和重建中的信息泄漏风险。例如,如上图所示,可以通过在普通随机遮挡或帧遮挡下在相邻帧中找到相应的未遮挡patch来重建遮挡patch。在这种情况下,这可能会导致视频MAE学习低级的时间对应关系,而不是高级信息,例如对内容的时空推理。为了避免这种行为,需要提出一种新的遮挡策略,使重建更具挑战性,并鼓励时空结构表征的有效学习。
2.3 VideoMAE
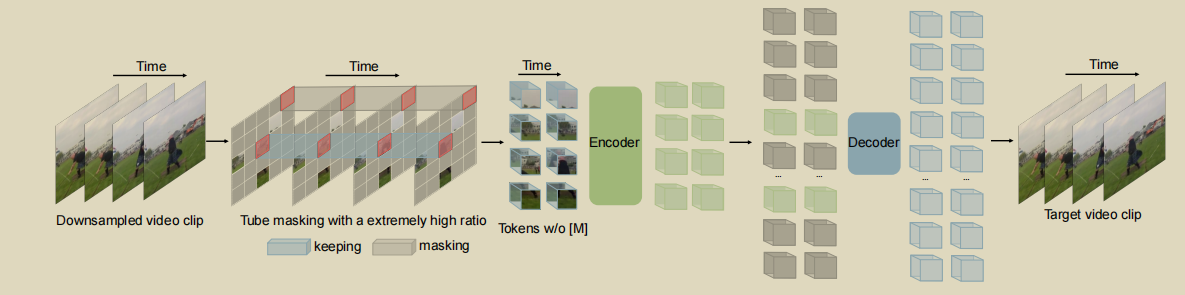
为了解决视频遮挡建模中的上述问题,作者在VideoMAE中进行了定制设计,总体流程如上图所示
时间下采样
根据以上对连续帧时间冗余性的分析,提出使用跨步时间采样策略来执行更有效的视频预训练。首先从原始视频V中随机抽取一个由t个连续帧组成的视频片段。然后,作者使用时间采样将片段采样为T帧,每个帧包含H×W×3个像素。在实验中,在Kinetics和Something-Something数据集中,步幅τ分别设置为4和2。
Cube embedding
在VideoMAE中采用了联合时空立方体嵌入,将每个大小为2×16×16的立方体视为一个token嵌入。因此,嵌入层获得个3D token,并将每个token映射到通道尺寸D。这种设计可以降低输入的时空维度,有助于缓解视频中的时空冗余。
Tube masking

为了缓解之前讨论的时间相关性带来的信息泄漏,提出了temporal tube masking机制,用于视频中的遮挡自动编码器预训练。temporal tube masking强制mask在整个时间轴上扩展,即,不同的帧共享相同的masking map。从数学上讲,tube masking机制可以表示为不同的时间t共享相同的值。利用这种机制,遮挡立方体的时间邻域总是被mask的。这将鼓励本文的VideoMAE通过高级语义进行推理,以恢复这些完全缺失的时空立方体。这种简单的策略可以缓解遮挡视频建模中的信息泄漏问题。
Extremely high masking ratio
时间冗余性是影响视频设计的关键因素。与ImageMAE相比,VideoMAE有利于极高的掩蔽比率 (例如90% 至95%),视频信息密度比图像低得多,高比率会增加重建难度。














 637
637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









