






读文章:Few-Shot Unsupervised Image-to-Image Translation
网络结构
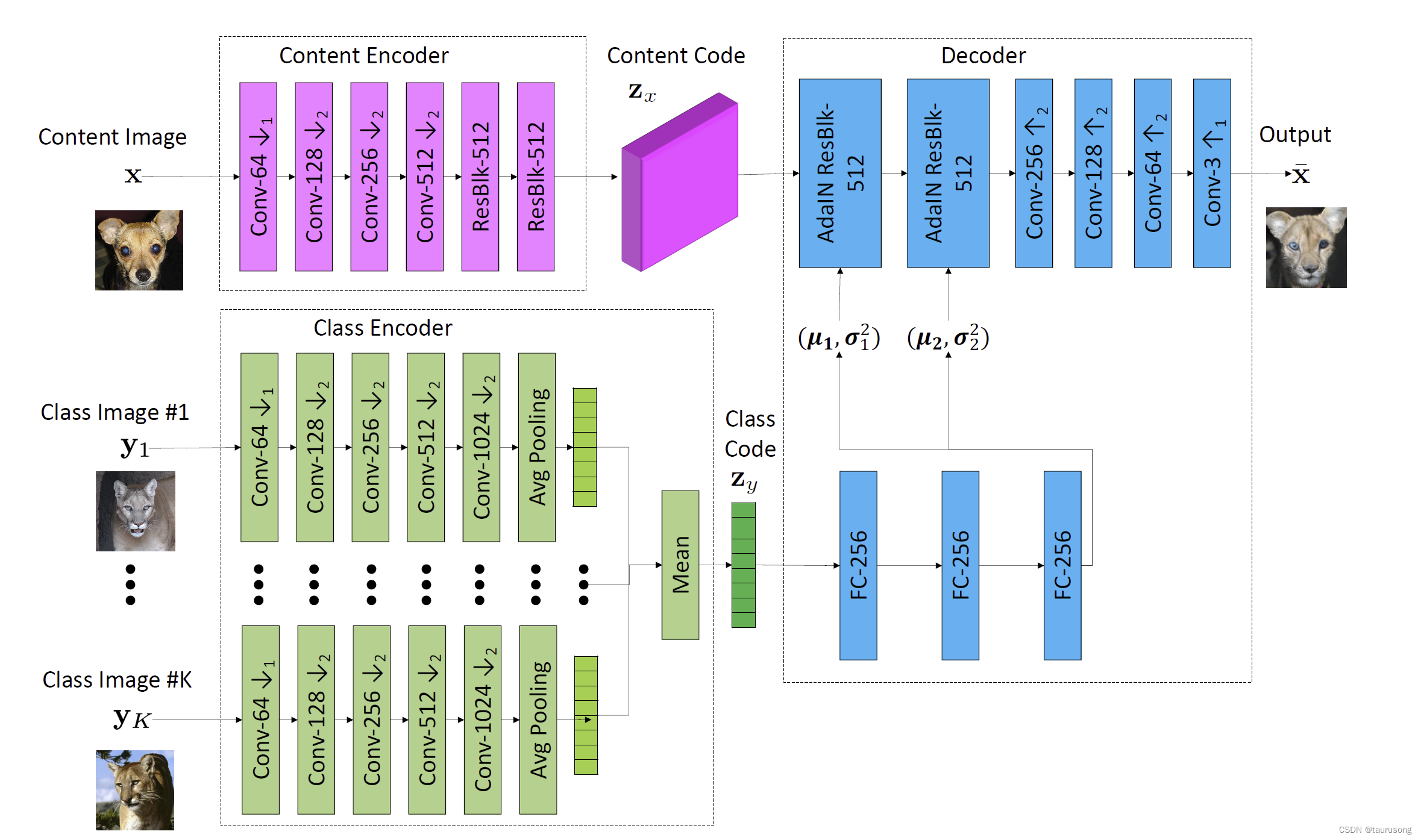
Unsupervised/unpaired image-to-image translation
Humans are remarkably good at generalization.人类擅长演绎。
This problem is inherently ill-posed as it attempts to recover the joint distribution using samples from marginal distributions非配对图像到图像的翻译是从边缘分布的样本推测联合分布,因此是ill-posed.
To deal with the problem, existing works use additional constraints. For example, some works enforce the translation to preserve certain properties of the source data, such as pixel values [41], pixel radients [5], semantic features [46], class labels [5], or pairwise sample distances [3]. There are works enforcing the cycle consistency constraint [52, 55, 25, 1, 56]. Several works use the shared/partially-shared latent space assumption [29, 30]/[19, 26]. Our work is based on the partiallyshared latent space assumption but is designed for the fewshot unsupervised image-to-image translation task.为了应对这个问题,现有的工作采用增加额外约束的方法。例如有的要求保留源数据的特定属性:像素值、像素梯度、语义特征、类标识、成对样本的距离等。有的强制满足循环一致性约束。有的采用共享/部分共享潜在空间假设。本文的工作基于部分共享潜在空间假设。但是针对的问题是少样本无监督图像到图像转换的任务。
While capable of generating realistic translation outputs, existing unsupervised image-to-image translation models are limited in two aspects. First, they are sample inefficient, generating poor translation outputs if only few images are given at training time. Second, the learned models are limited
for translating images between two classes. A trained model for one translation task cannot be directly reused for a new task despite similarity between the new task and the original task. For example, a husky-to-cat translation model can not be re-purposed for husky-to-tiger translation even though cat and tiger share a great similarity.
现有的技术在两个方面有问题:一是他们都是样本依赖的,如果训练的时候给的样本少,则翻译的性能就会差。二是训练好的模型仅仅局限于两类图像之间的翻译。即使两类翻译任务比较相似,训练好的针对一类翻译任务的模型也不能直接复用。例如husky到猫之间的翻译就无法直接用于husky到老虎之间的翻译,虽然猫和老虎很像。
(Latent Space)潜在空间。
“潜在空间”的概念很重要,因为它的用途是“深度学习”的核心-学习数据的特征并简化数据表示形式以寻找模式。 深度神经网络即深度学习是一种Representation Learning, 表征学习。顾名思义,学习数据表征。我们的学习过程已经不是靠一些分布来拟合给定数据的分布, 而是通过空间转换来学习数据特征。通常,在机器学习中对数据进行压缩以学习有关数据点的重要信息。
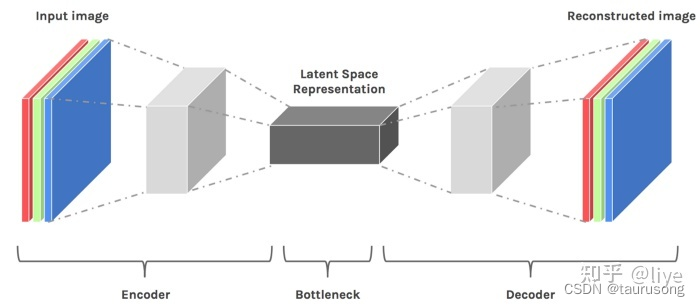
因为需要模型来重建压缩数据(请参见解码器),所以它必须学会存储所有相关信息并忽略噪声。 这就是压缩的价值,它使我们能够摆脱任何无关的信息,而只关注最重要的功能。这种“压缩状态”是数据的潜在空间表示。
(1)表征学习
数据的潜在空间表示包含表示原始数据点所需的所有重要信息。然后,该表示必须表示原始数据的特征。换句话说,该模型学习数据特征并简化其表示,从而使其更易于分析。这是称为表示学习(Representation Learning)的概念的核心,该概念定义为允许系统从原始数据中发现特征检测或分类所需的表示的一组技术。在这种用例中,我们的潜在空间表示用于将更复杂的原始数据形式(即图像,视频)转换为更“易于处理”和分析的简单表示。
(2)自编码器和生成模型
自编码器是操纵潜在空间中数据“紧密度”的一种常见类型的深度学习模型,它是一种充当身份函数的神经网络。 换句话说,自动编码器会学习输出任何输入的内容。
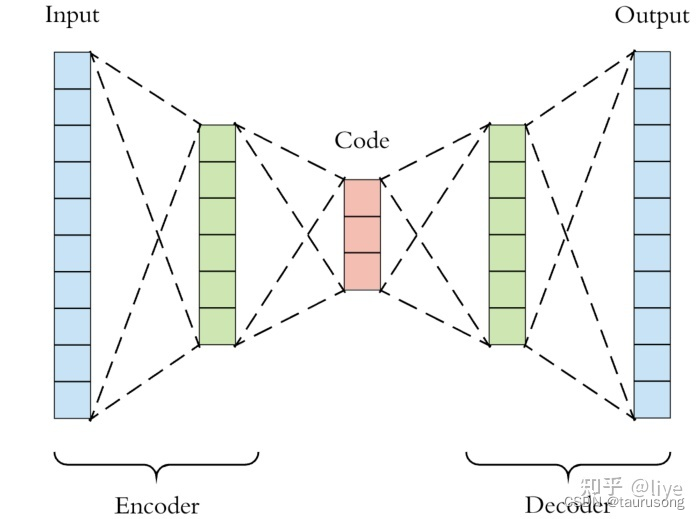
在上面的示例中,我们可以通过在潜在空间上进行插值,并使用模型解码器将潜在空间表示重构为二维图像,并以与原始输入相同的尺寸来生成不同的面部结构。
(3)重要要点
潜在空间只是压缩数据的表示,其中相似的数据点在空间上更靠近在一起。
潜在空间对于学习数据功能和查找更简单的数据表示形式以进行分析很有用。
我们可以通过分析潜在空间中的数据(通过流形,聚类等)来了解数据点之间的模式或结构相似性。
我们可以在潜在空间内插值数据,并使用模型的解码器来“生成”数据样本。
我们可以使用t-SNE和LLE之类的算法来可视化潜在空间,该算法将我们的潜在空间表示形式转换为2D或3D。
指标
domain-invariant perceptual distance (DIPD):是一种领域不变的感性距离指标。
inception score (IS) 用于评价生成图片真实性的一种指标。
Frechet Inception Distance FID:用于评价两个图片之间相似性的指标。
【1】Sagie Benaim and Lior Wolf. One-shot unsupervised cross domain translation. In Advances in Neural Information Processing Systems (NIPS), 2018. 少样本跨领域无监督翻译的一篇文献。这个模型针对的是一对多的翻译。本文针对的是多对多的翻译。
【2】Asha Anoosheh, Eirikur Agustsson, Radu Timofte, and Luc Van Gool. Combogan: Unrestrained scalability for image domain translation.
【3】Le Hui, Xiang Li, Jiaxin Chen, Hongliang He, and Jian Yang. Unsupervised multi-domain image translation with domain-specific encoders/decoders. arXiv preprint arXiv:1712.02050, 2017.
潜在空间:https://zhuanlan.zhihu.com/p/369946876
代码连接:https://github.com/NVlabs/FUNIT















 485
485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









