







在实际的工作中,常见的机器学习处理的数据大概分成三种,一种是图像数据,图像数据通常是RGB三通道的彩色数据,图像上的每个像素由一个数值表示,这个其实比较容易处理;一种是文本数据,文本数据挖掘就是我们通常说的自然语言处理,文本数据首先是非结构化的,同时我们需要把文本数据表示成数值,这得花一些功夫;还有一种就是结构化的数据,结构化数据比如说一张excel数据表,每一列代表一个特征,具体到它的值可能是数值也可能是文本,可能是连续的也可能是非连续的,这种数据我们也需要进行转化,但是通常来说比自然语言好处理一点。
其实在前面的小练习中也加载过一些数据,但是都没有处理部分,那些数据都是已经处理好的。下面我们就看一些数据初始化的例子。
图像数据
普通二维图像
我们在显示器上看到的图像其实是经过了数字编码的,关于图像编码的方法其实有很多种,比如RGB,HSR,有关图像处理的事情,又想起了当年上学的时候学的冈萨雷斯《数字图像处理》那本大厚书,真是抹不去的记忆。
现在最常用的是RGB编码,一个彩色的图像由红绿蓝三色叠加而成,就像下面这个美女图像。

下面尝试加载图像,这里祭出我们的图像处理女神lena,当然这里只选取了她的头部数据,实际上这是花花公子某期杂志中的图像,整幅图还包括让人血脉偾张的部分,请感兴趣的朋友自行寻找。

我们使用imageio模块来加载图像,可以看到lena是一个512*512尺寸的美女,有3个通道。
import imageio
img_arr = imageio.imread('../../data/p1ch4/lena.jpg')
img_arr.shape
outs:
(512, 512, 3)
如果说我们想给维度换一下位置,可以使用permute方法,这里我们把channel维度换到了最前面
import torch
img = torch.from_numpy(img_arr)
out = img.permute(2, 0, 1)
out.shape
outs:torch.Size([3, 512, 512])
除了处理一张图像,我们更多的时候需要加载一批图像。毕竟我们的深度学习模型不想总盯着一个美女看,它喜欢看各种各样的美女,除了lena还有luna,sherry,cherry等等,这样它才能总结出美女的特质。
这里有一个方法就是预先设定好一个合适的tensor,然后不断的读取图像去塞满它。
我们定义一批数据就是3张图,每张图由3个通道和256*256的尺寸构成,其中的数值为8位无符号整型 。

这里作者给我们准备了3只可爱的猫猫当数据,你也可以在网上找三个美女。
batch_size = 3
batch = torch.zeros(batch_size, 3, 256, 256, dtype=torch.uint8)
import os
data_dir = '../../data/p1ch4/image-cats/' #设定相对路径
filenames = [name for name in os.listdir(data_dir) #读取文件名
if os.path.splitext(name)[-1] == '.png']
for i, filename in enumerate(filenames):
img_arr = imageio.imread(os.path.join(data_dir, filename)) #获取绝对路径
img_t = torch.from_numpy(img_arr) #生成tensor
img_t = img_t.permute(2, 0, 1) #交换维度位置
img_t = img_t[:3] # 保留前三个维度,有时候你下载的图像可能还会有其他维度
batch[i] = img_t #把图塞进batch里,这里要注意如果原始图跟目标tensor尺寸不一样还需要处理一下
接下来就是把数据归一化,在神经网络中通常使用浮点数进行运算。归一化方法有很多,比如说直接除以最大值255(8位无符号数能表示的最大数)
batch = batch.float()
batch /= 255.0
或者按均值标准差缩放,使得均值为0,标准差为1
n_channels = batch.shape[1]
for c in range(n_channels):
mean = torch.mean(batch[:, c])
std = torch.std(batch[:, c])
batch[:, c] = (batch[:, c] - mean) / std
三维图形:人体切片数据

本来这种数据并不多见,也就是在一些医学公司才会用得到,但是这本书里面,我看后面的例子都是用的医学数据,可能作者对这方面的数据比较擅长吧。关于切片数据和三通道,乍看图像好像有点像,但实际上是完全不同的,RGB通道数据所表示的都是一个图像,只是颜色不一样,这个切片数据每张图的内容都是不一样的,而其中的每张图可以有自己的RGB通道,因此这是一个三维图像。所以这个数据的维度要比刚才的多一维深度。
DICOM是一种图像数据类型,是Digital Imaging and Communication in Medicine的缩写,医学数字成像和通信,该类图像后缀为dcm,这里准备了99张图像,可以看到加载进度
import imageio
dir_path = "../../data/p1ch4/volumetric-dicom/2-LUNG 3.0 B70f-04083"
vol_arr = imageio.volread(dir_path, 'DICOM')
vol_arr.shape
Reading DICOM (examining files): 1/99 files (1.0%99/99 files (100.0%)
Found 1 correct series. #读取进度条
Reading DICOM (loading data): 31/99 (31.392/99 (92.999/99 (100.0%)
outs:(99, 512, 512)
不过从上面的shape我们可以看出,这份数据是不包含通道维度的,因为这个医学图像是灰度图,我们可以使用unsqueeze方法给它升维
vol = torch.from_numpy(vol_arr).float()
vol = torch.unsqueeze(vol, 0)
vol.shape
outs:torch.Size([1, 99, 512, 512])
结构化数据:表格
表格数据通常都保存成csv格式,里面用逗号分隔,当然存储的时候你也可以定义其他的分隔符。
这里给出的是一个用于判定葡萄酒质量好坏的数据集,里面包含了12列数据,因为我对葡萄酒比较感兴趣,所以我把每一列的含义都查了一下
| 列名 | 含义 |
|---|---|
| fixed acidity | 固定酸度 |
| volatile acidity | 挥发性酸度 |
| citric acid | 柠檬酸 |
| residual sugar | 残余糖度 |
| chlorides | 氯化物 |
| free sulfur dioxide | 游离二氧化硫 |
| total sulfur dioxide | 二氧化硫总量 |
| density | 密度 |
| pH | 酸碱度 |
| sulphates | 硫酸盐 |
| alcohol | 酒精度 |
| quality | 质量 |
根据给出的数据,我们或许可以训练一个模型来模拟人对葡萄酒的评分。
import numpy as np
import csv
wine_path = "../../data/p1ch4/tabular-wine/winequality-white.csv"
wineq_numpy = np.loadtxt(wine_path, dtype=np.float32, delimiter=";",
skiprows=1) #这里指定分隔符为‘;’,同时跳过第一行,因为第一行是列名
wineq_numpy
outs:array([[ 7. , 0.27, 0.36, ..., 0.45, 8.8 , 6. ],
[ 6.3 , 0.3 , 0.34, ..., 0.49, 9.5 , 6. ],
[ 8.1 , 0.28, 0.4 , ..., 0.44, 10.1 , 6. ],
...,
[ 6.5 , 0.24, 0.19, ..., 0.46, 9.4 , 6. ],
[ 5.5 , 0.29, 0.3 , ..., 0.38, 12.8 , 7. ],
[ 6. , 0.21, 0.38, ..., 0.32, 11.8 , 6. ]], dtype=float32)
col_list = next(csv.reader(open(wine_path), delimiter=';'))
wineq_numpy.shape, col_list #查看形状和列名
outs:((4898, 12),
['fixed acidity',
'volatile acidity',
'citric acid',
'residual sugar',
'chlorides',
'free sulfur dioxide',
'total sulfur dioxide',
'density',
'pH',
'sulphates',
'alcohol',
'quality'])
接下来就是把这个数据改成tensor格式
wineq = torch.from_numpy(wineq_numpy)
wineq.shape, wineq.dtype
outs:(torch.Size([4898, 12]), torch.float32)
接下来,我们要把里面的数据分成特征集和结果标签集两部分。
data = wineq[:, :-1] # <1>
data, data.shape
outs:(tensor([[ 7.00, 0.27, ..., 0.45, 8.80],
[ 6.30, 0.30, ..., 0.49, 9.50],
...,
[ 5.50, 0.29, ..., 0.38, 12.80],
[ 6.00, 0.21, ..., 0.32, 11.80]]), torch.Size([4898, 11]))
target = wineq[:, -1] # <2>
target, target.shape
outs:(tensor([6., 6., ..., 7., 6.]), torch.Size([4898]))
#对于要预测的标签数据,我们要把它转换成整数,我理解如果是浮点数没办法作为目标运算,因为这是一个类别信息?这我还没试过,以后可以试试浮点数会不会报错。
target = wineq[:, -1].long()
target
tensor([6, 6, ..., 7, 6])
时序数据:共享单车每小时租赁数量
这份数据是跟时间有关系的:来自华盛顿的共享单车数据集,包括了2011、2012年华盛顿共享单车系统中每个小时的自行车租赁数量,以及天气和季节信息。数据示例如下,利用这种数据,我们可以想到的一种使用方法是,借助前若干天或小时的数据来预测下个小时将有多少车被租赁。
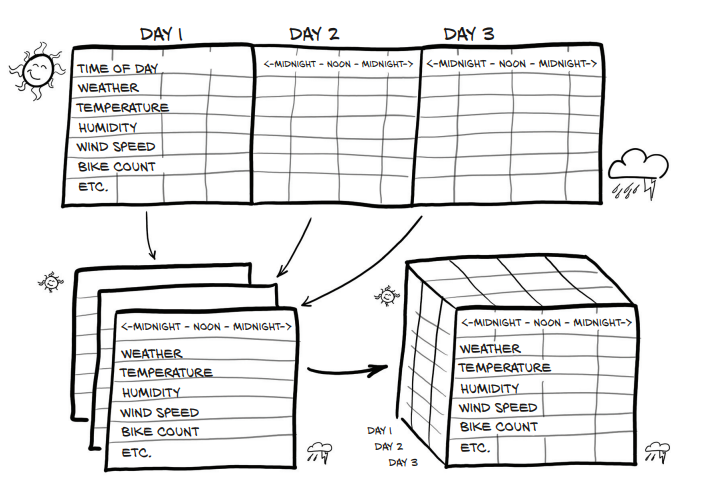
我们的数据源仍然是存在csv文件中
import numpy as np
import torch
# set_printoptions 用于控制输出结果的格式
# edgeitems 边界元素个数,即超过阈值后两边能显示的元素的个数
# threshold 阈值,超过阈值后进行缩略显示即中间用...显示,默认阈值是1000
# linewidth 行宽:即每行默认显示75个字符
torch.set_printoptions(edgeitems=2, threshold=50, linewidth=75)
加载数据
这是csv原始文件的数据

我们把这个数据读出来
bikes_numpy = np.loadtxt(
"../data/p1ch4/bike-sharing-dataset/hour-fixed.csv",
dtype=np.float32,
delimiter=",",
skiprows=1,
converters={1: lambda x: float(x[8:10])}) # 把日期字符串转换成数字
bikes = torch.from_numpy(bikes_numpy)
bikes
outs:
tensor([[1.0000e+00, 1.0000e+00, ..., 1.3000e+01, 1.6000e+01],
[2.0000e+00, 1.0000e+00, ..., 3.2000e+01, 4.0000e+01],
...,
[1.7378e+04, 3.1000e+01, ..., 4.8000e+01, 6.1000e+01],
[1.7379e+04, 3.1000e+01, ..., 3.7000e+01, 4.9000e+01]])
我们看一下数据的数量情况,里面总共有17520个小时的数据,也就是730天的数据
bikes.shape, bikes.stride()
outs:(torch.Size([17520, 17]), (17, 1))
下面我们要把它变成三维数据,增加一个‘日’维度。
Pytorch中使用view()函数对张量进行重构维度,类似于resize()、reshape()。用法如下:view(参数a,参数b,...),其中总的参数个数表示将张量重构后的维度,如果参数=-1,表示这该维度由pytorch自己补充。
例如 张量a的维度为16,a.view(2,3)的维度为23,a.view(-1,2,1)的维度为321
daily_bikes = bikes.view(-1, 24, bikes.shape[1])
daily_bikes.shape, daily_bikes.stride()
outs:(torch.Size([730, 24, 17]), (408, 17, 1))
关于常见的数值类型:连续值、序列值、分类值
基于上面的这些内容,关于比较简单的图像和结构化数据的读取基本上可以实现了,在介绍文本编码之前,我们先看一下数值类型的处理方式。
连续值
对于连续值来说,通常是可以直接运算的,比如说一个人的身高数据,是分布在假设是1米到2米区间内的任意一个数值,这种值是有自然意义的,比如说2米高的人是1米高的人两倍高度,1.5米的人比1米的人高0.5米,这里面存在着一种尺度衡量的关联。如果说理解这个有点匪夷所思,等看完下面两种数值应该能清楚一点区别。对于连续值来说,通常不需要进行特别的处理,可以直接丢进深度模型进行运算,不管是分类还是回归。
序列值
对于序列值,比如说时间序列,2点,3点,4点,或者是把某些具备序列关系的实体映射成序列值,比如说小杯饮料是1,中杯饮料是2,大杯饮料是3。这种序列值直接只存在顺序关系,就是3点在2点之后,4点在3点之后,但是4点并不是2点的两倍。同样道理,大杯比中杯大,中杯比小杯大,但是并没有大杯减去中杯等于小杯这样的概念。也就是说这种值不存在尺度关系,没办法进行数学运算。
分类值
对于分类值,就连序列关系也失去了,这只是用来标记某种事物用的,比如说我们要给新闻分类,军事映射为1,体育映射为2,娱乐映射为3,这些数字之间不存在任何逻辑关系,因为分类数值没有意义,所以它们被称为名义尺度。
对于序列值一般会把它变成一个维度,或者是把它也当做一种分类值来处理,而对于分类值怎么处理呢?这里主要是要去讲一下one-hot(独热编码)。
One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
One-Hot编码是分类变量作为二进制向量的表示。这首先要求将分类值映射到整数值。然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
思路拉回葡萄酒数据,如果我们把质量集看做是一种序列值,也就是说葡萄酒的品质有10个档次,分别为1-10,那么所谓的独热编码就是设定一个有10位的向量(0,0,0,0,0,0,0,0,0,0),对于一个具体的葡萄酒的品质数据,如果是1那么就构建一个10位的向量,第1位为1,其他位都是0;如果品质是10,那么构建一个10位的向量第10位是1其他位都是0。
target_onehot = torch.zeros(target.shape[0], 10)
target_onehot.scatter_(1, target.unsqueeze(1), 1.0) #这里试了一下,如果不把target转换成long型会报错,scatter期望整数类型
outs:
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 1., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
可以看到经过编码后的质量特征已经变成了上面的形式。
那么进行one-hot编码有什么好处呢?经过one-hot编码,相当于提升了该数据的维度,同时使得序列值在新的空间中容易计算,因为我们的机器学习思路往往是去计算相似度和距离来判断该怎么分类或者回归。而且one-hot编码是一种相当简单的编码,非常容易实现。当然,one-hot编码也有很明显的缺点,首先它对信息的表达肯定是不完全的,再就是当特征类别特别多的时候这个one-hot编码就会极其庞大,这就涉及到后面关于自然语言的编码了。
文本数据:傲慢与偏见
其实知道了one-hot编码,关于文本数据的处理就没有太多新的东西了,这里直接上代码。对了,这里趁机说一句,关于文本语料库有一个古登堡计划,里面存了大量的英文原版书的数据,可以拿来阅读用,还有一个很不错的电子书下载网站z-library,希望你不会错过。
import numpy as np
import torch
torch.set_printoptions(edgeitems=2, threshold=50)
with open('../data/p1ch4/jane-austen/1342-0.txt', encoding='utf8') as f:
text = f.read() #限定编码格式为utf8,在文本处理中,编码格式是个让人头疼的问题,尤其是中文的自然语言处理
lines = text.split('\n')
line = lines[200] #抽取其中第200行的文本
line
outs:'“Impossible, Mr. Bennet, impossible, when I am not acquainted with him'
接下来让我们为它进行one-hot编码,这段代码有点长,文本数据往往需要比较多的处理,当然现在比较流行的文本预训练模型大大降低了文本处理的难度,但是这里我们先不用预训练模型来处理,不然就没得讲了。
为字符构建独热编码,英语里有26个字母,有一种常见的底层编码格式是ASCII格式,大家有兴趣可以去查一下,总共包含128个字符。我们这里也设定一个长度128的向量来编码我们的字符。
ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
letter_t = torch.zeros(len(line), 128) # 这里设定我们one-hot编码的长度为128
letter_t.shape
outs:torch.Size([70, 128])
for i, letter in enumerate(line.lower().strip()):
letter_index = ord(letter) if ord(letter) < 128 else 0 # 处理掉没办法表示的字符
letter_t[i][letter_index] = 1
仅仅为字母进行编码还是比较容易的,下面再试试为单词构建独热编码。
def clean_words(input_str): #处理停用词,这里是处理掉一些特殊字符,并全部转换为小写
punctuation = '.,;:"!?”“_-'
word_list = input_str.lower().replace('\n',' ').split()
word_list = [word.strip(punctuation) for word in word_list]
return word_list
words_in_line = clean_words(line)
line, words_in_line
outs:
('“Impossible, Mr. Bennet, impossible, when I am not acquainted with him',
['impossible',
'mr',
'bennet',
'impossible',
'when',
'i',
'am',
'not',
'acquainted',
'with',
'him'])
word_list = sorted(set(clean_words(text))) #清理整篇傲慢与偏见并对单词进行排序
word2index_dict = {word: i for (i, word) in enumerate(word_list)} #把清理好的傲慢与偏见存成一个字典,字典存的是单词和单词所在的位置
len(word2index_dict), word2index_dict['impossible'] #查询一下impossible的位置
outs:(7261, 3394) #总共有7261个词,impossible在位置3394
word_t = torch.zeros(len(words_in_line), len(word2index_dict)) #查询第200句话中所有词的位置,并构建起这句话one-hot编码,结果是这句话的ont-hot编码是一个矩阵,每一行表示一个单词,总共有11行,说明有11个单词,每个单词使用词典全集的长度7261作为one-hot编码,只有在它所在的位置置为1,其他位都是0。
for i, word in enumerate(words_in_line):
word_index = word2index_dict[word]
word_t[i][word_index] = 1
print('{:2} {:4} {}'.format(i, word_index, word))
print(word_t.shape)
outs:
0 3394 impossible
1 4305 mr
2 813 bennet
3 3394 impossible
4 7078 when
5 3315 i
6 415 am
7 4436 not
8 239 acquainted
9 7148 with
10 3215 him
torch.Size([11, 7261])
构建起这个编码之后,我们就可以拿着这个编码去做其他的事情了,比如给文本分类。但是它的问题显而易见,7000多位的向量只有1位是1,这是对空间大大的浪费,而且这只是一本英文小说,英文都是按单词来分的,总单词量不是特别多,还相对容易一点,对于中文来说,要按中文的分词结果进行处理,可能有几十万上百万的词,要构建one-hot编码这简直就是让人头爆炸的事情。
因此很多人在文本编码问题上做了大量的试验和探究,后面有了很多种基于one-hot的变体编码方式,还有了比如说PCA这种降维的算法,但是one-hot就是one-hot,在庞大的语言词汇面前是那么的消耗资源,直到一种新的编码方式横空出世,造就了自然语言处理新的时代,那就是词嵌入(word embedding)技术,再后面的发展都是在词嵌入的基础上进行的,不过这个算法我们就不在这里讨论了,以后有时间讲自然语言处理的话再拿出来讲吧。
今天就学到这里了,让我头大。














 1598
1598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









