







目录
pytorch如何读取数据主要涉及两个类:
- dataset:提供一种方式去获取数据及其 label
dataset主要实现以下两个功能:
1)告诉我们如何获取每一个数据及其label
2)告诉我们总共有多少的数据
- dataloader:为网络提供不同的数据形式
’
1. Dataset
1.1 Dataset类解析
可通过以下方式查看该类解析:
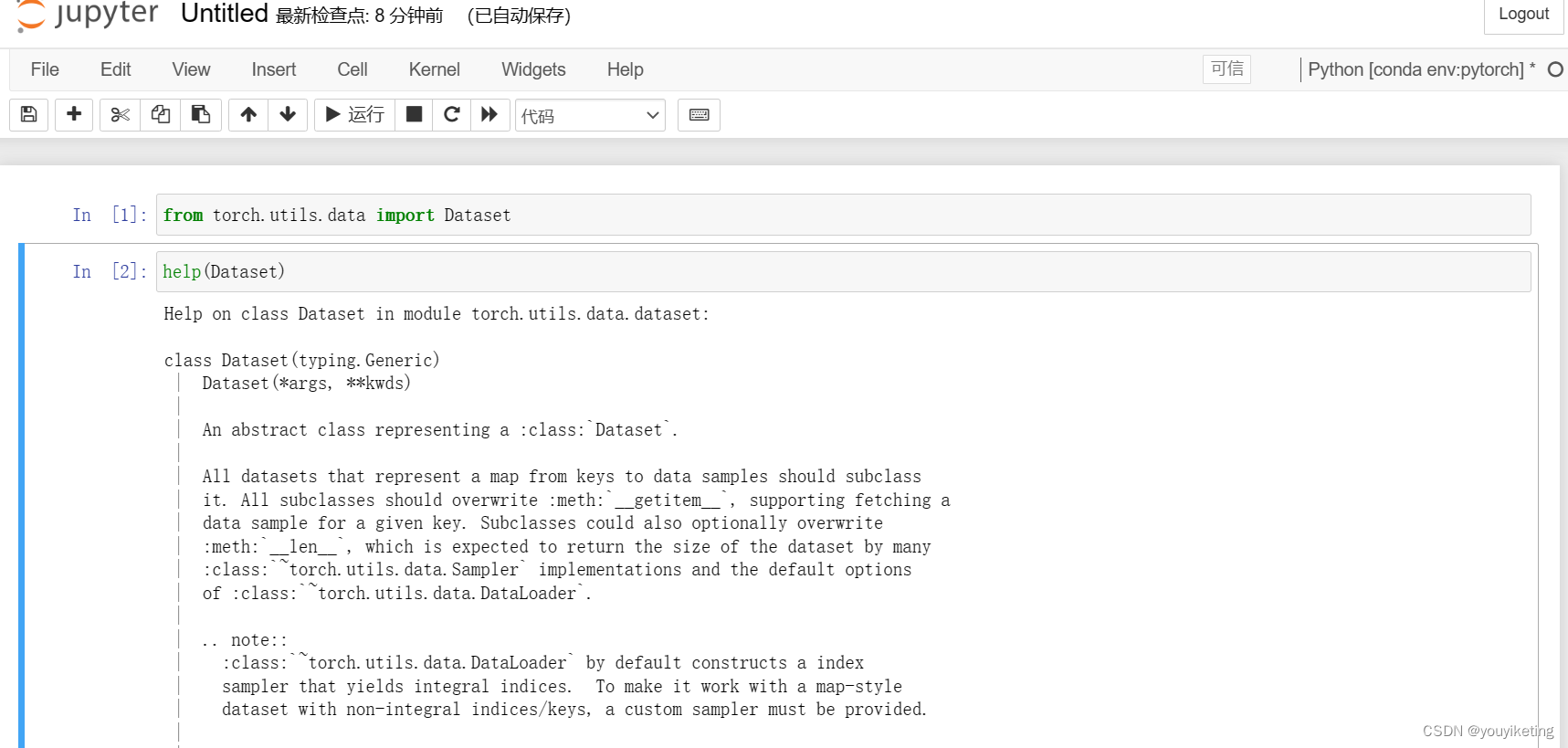
'Dataset‘ 是一个抽象类,所有数据集(datasets)都需要继承该类。
所有子类都需要重写 '__getitem__' 方法(用以获取每个数据及其对应的label);
此外,子类可选择重写 '__len__' 方法(用以获取数据的长度)。
1.2 Dataset类代码实战:
创建Dataset子类
from torch.utils.data import Dataset
from PIL import Image # 读取图片的库,可以对图片进行可视化
import os # 关于系统操作的库,主要用来对文件路径操作
# 每个数据集datasets都需要继承Dataset类
class MyData(Dataset):
# 初始化-为class提供一个全局变量,为后面的函数提供所需的量
def __init__(self, root_dir, label_dir):
# 创建数据(图片)列表(for ’__getitem__‘函数的idx获取图片)
self.root_dir = root_dir # 某类图片所在文件夹的根目录路径
self.label_dir = label_dir # 某类图片所在文件夹的名称(数据集以类名作为文件夹名称)
self.path = os.path.join(self.root_dir, self.label_dir) # 某类图片的文件夹路径
self.img_path = os.listdir(self.path) # 创建图片列表-存放的是某类数据中每个图片的文件名
# 获取数据及其label
def __getitem__(self, idx):
# 根据idx索引来读取某一数据(图片)
img_name = self.img_path[idx] # 图片名称
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name) # 图片路径
img = Image.open(img_item_path)
label = self.label_dir
return img, label
# 获取数据集长度
def __len__(self):
return len(self.img_path) # 返回列表长度实例化:
My_root_dir = r"C:\Users\L\Desktop\deeplearning\BelgiumTSC\Training"
label0_label_dir = "00000"
label1_label_dir = "00001"
label2_label_dir = "00002"
# 实例化类
label0_dataset = MyData(My_root_dir, label0_label_dir)
label1_dataset = MyData(My_root_dir, label1_label_dir)
label2_dataset = MyData(My_root_dir, label2_label_dir)
# 数据集拼接
train_dataset = label0_dataset + label1_dataset + label2_dataset
#调用
label0_dataset_len = len(label0_dataset)
label1_dataset_len = len(label1_dataset)
label2_dataset_len = len(label2_dataset)
label0_img0, label0 = label0_dataset[0]
label1_img0, label1 = label1_dataset[0]
label2_img0, label2 = label2_dataset[0]
train_dataset_len = len(train_dataset)
img, label = train_dataset[label0_dataset_len]
print("label0_dataset_len = ", label0_dataset_len)
print("label1_dataset_len = ", label1_dataset_len)
print("label2_dataset_len = ", label2_dataset_len)
print("train_dataset_len = ", train_dataset_len)
print("label0 = ", label0)
print("label1 = ", label1)
print("label2 = ", label2)
print("label = ", label)
label1_img0.show()
img.show()
结果: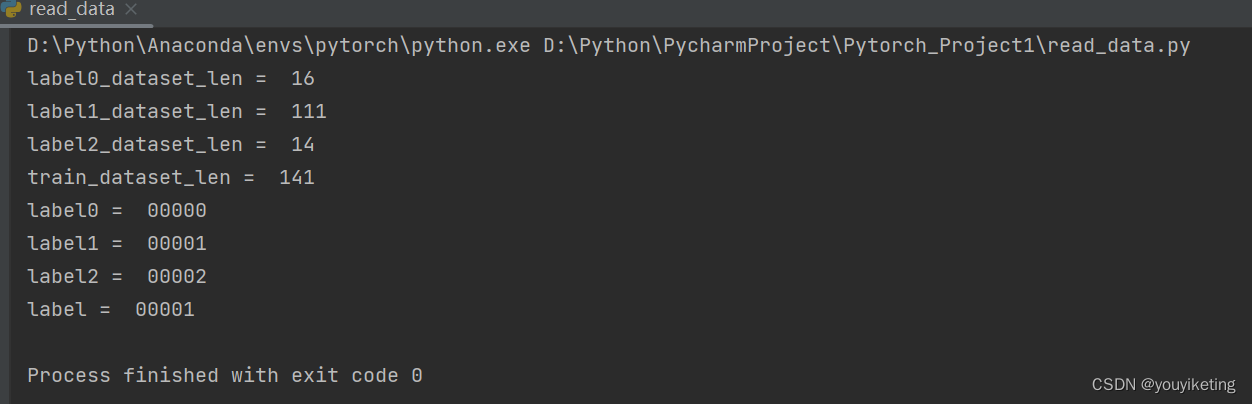
2. Dataloader
把数据加载进神经网络中,控制从dataset中以什么形式加载多少数据。
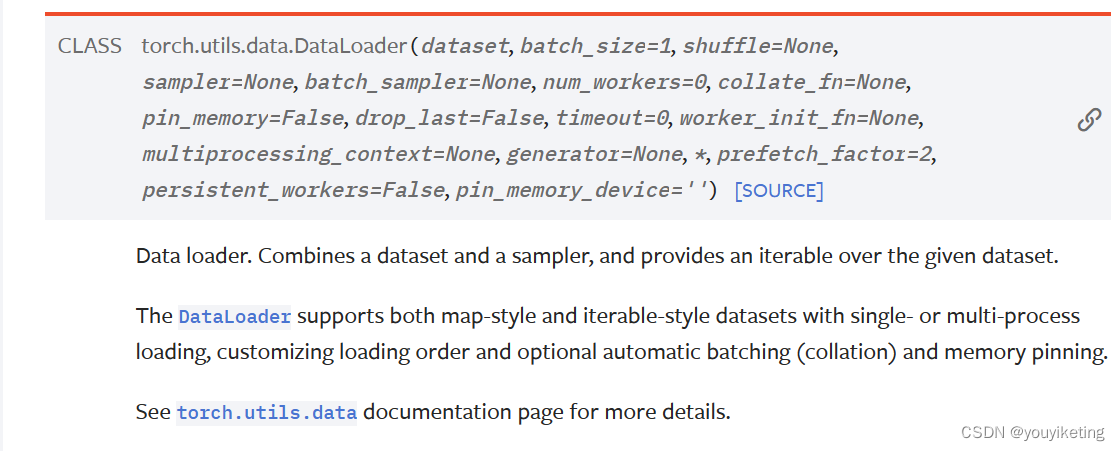
常用参数:

![]()



PS:当num_workers = 0时,windows可能会报错.

2.1 测试batch_size参数
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False, transform =torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=True)
# 测试batch_size=4: 每次从测试数据集中取4个数据进行打包
# 测试数据集中第一张图片及target
img, target = test_data[0]
print("1st image: ", img.shape)
print("1st image_target: ", target)
i = 0
for data in test_loader:
imgs, targets = data
print("batch {}: ".format(i), imgs.shape)
print(" targets= ".format(i), targets)
i = 1+i
batch_size = 4,每次从测试数据集中取4个数据进行打包.

2.2 测试drop_last参数
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False, transform =torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
# 测试drop_last
writer = SummaryWriter("dataloader_logs")
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("drop_last = False", imgs, step)
step = step + 1
writer.close()batch_size=64,drop_last=False
当最后一组数据不满足batch_size时,也不舍去。

batch_size=64,drop_last=True
当最后一组数据不满足batch_size时,舍去。
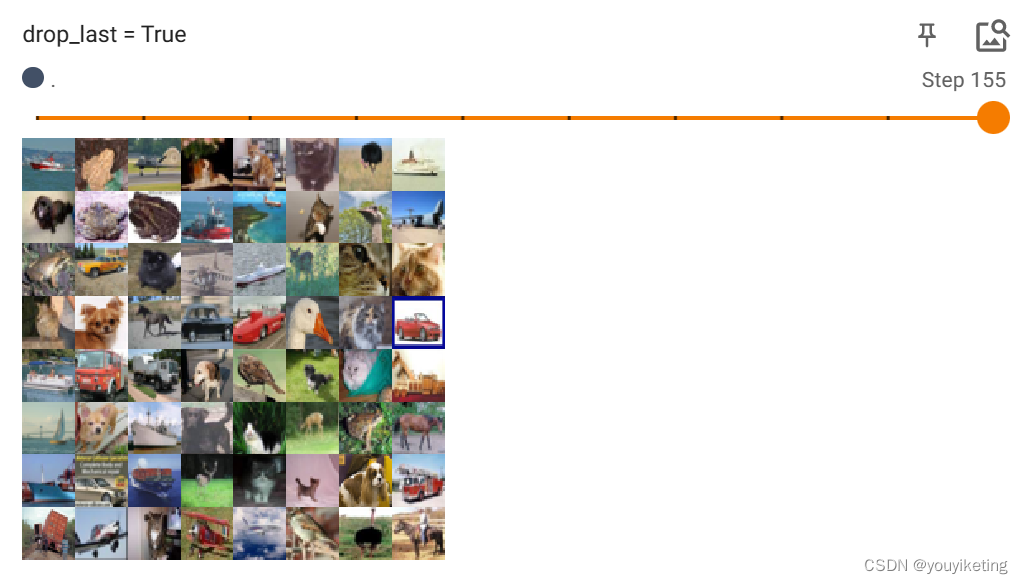
2.3 测试shuffle参数
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False, transform =torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 测试 shuffle
writer = SummaryWriter("dataloader_logs")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("shuffle=True, Epoch:{}".format(epoch), imgs, step)
step = step + 1
writer.close()shuffle=True,每个epoch打乱输入图片的顺序

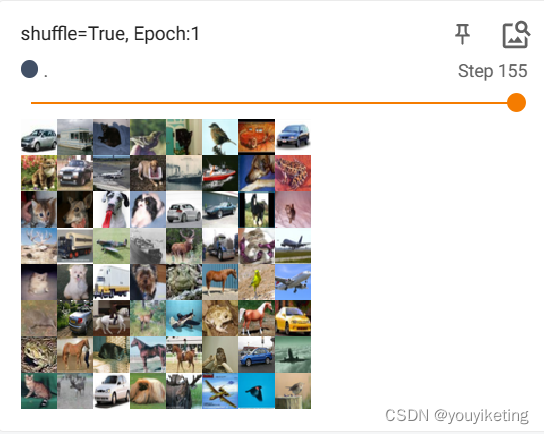
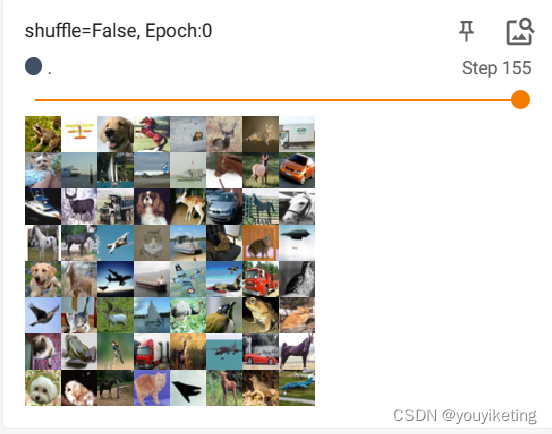
shuffle=False,每个epoch输入图片的顺序一致

参考:
(6条消息) pytorch根据数据集编写对应Dataset的方法(数据集格式一)——分类任务_读博好难啊的博客-CSDN博客_python变成dataset格式![]() https://blog.csdn.net/Norman0105/article/details/122663007P5. PyTorch加载数据初认识_哔哩哔哩_bilibili
https://blog.csdn.net/Norman0105/article/details/122663007P5. PyTorch加载数据初认识_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1hE411t7RN/?p=6&vd_source=a2b7029e58d3c675b2d4ea72e64ea4f5
https://www.bilibili.com/video/BV1hE411t7RN/?p=6&vd_source=a2b7029e58d3c675b2d4ea72e64ea4f5















 9563
9563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









