






0成本!基于腾讯云Cloud Studio,打造属于自己的数字人口播系统,照片+音乐=自动开口,效果炸裂
(本系统运行腾讯云的Linux上的ComfyUI环境,适合零基础小白)
Sonic是由腾讯与浙江大学团队研发的AI数字人生成工具,核心目标是通过音频驱动生成逼真的人物动画。它无需依赖复杂的视觉信号,仅凭声音即可控制虚拟人的面部表情、唇部动作和头部运动,生成流畅自然的视频。
,时长01:42
Sonic框架采用了上下文增强音频学习和运动解耦控制器,不仅提升了音频的长期时间感知,还能独立控制头部与表情运动,解决了长视频生成中的抖动和突变问题。其优势在于视频质量、唇部同步精度、运动多样性和时间连贯性上的出色表现,大幅提升了肖像动画的自然度和连贯性。
,时长01:02
Sonic能够根据不同风格的图像和各种类型的音频输入生成生动的肖像动画视频。无论是稳定长视频的生成,还是风格化非真实人类和多种分辨率比例的案例,Sonic都展现了良好的适应性。稳定长视频生成:1到10分钟的稳定长视频生成,突出时间感知位置偏移融合技术的有效性
Cloud Studio(云端 IDE)是一种基于浏览器的集成式开发环境,为开发者提供了一个稳定的云端工作站。现在可以免费注册体验,高性能空间每个月有10000分钟免费体验,通用空间右50000分钟免费体验。大家 赶快去注册吧。
今天就教大家怎么在腾讯云Cloud Studio上部署Sonic数字人。
一、 注册腾讯云Cloud Studio服务器及部署ComfyUI
1、 注册腾讯云Cloud Studio服务器
1)注册腾讯云
打开 https://cloud.tencent.com/ ,扫码登录,完成注册,认证。个人和企业都可以。
2)开通免费的高性能云空间(每月10000分钟的免费额度)
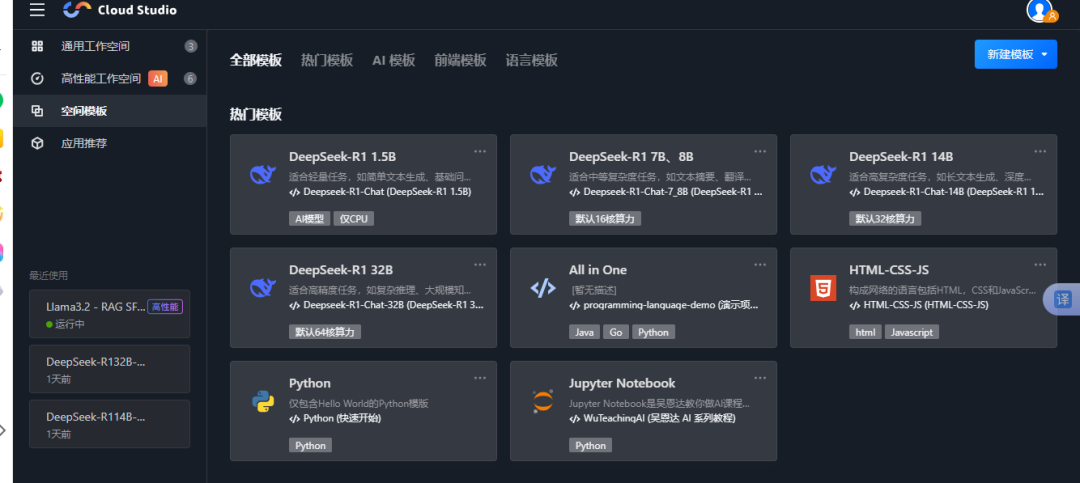
打开https://ide.cloud.tencent.com/ ,点击左上角的菜单,选择“空间模板“, 再点“AI模版“。选择 任意一个模版进行注册,稍等几分钟,高性能云空间就开通了。
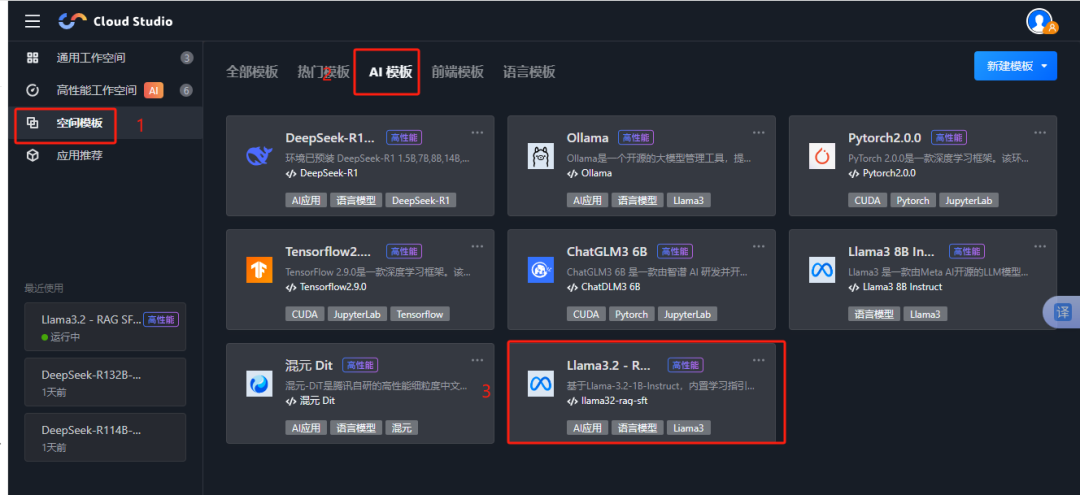
在“高性能工作空间“列表就可以看到这个服务器,状态是 ”运行中“,表示创建成功,已经开机、
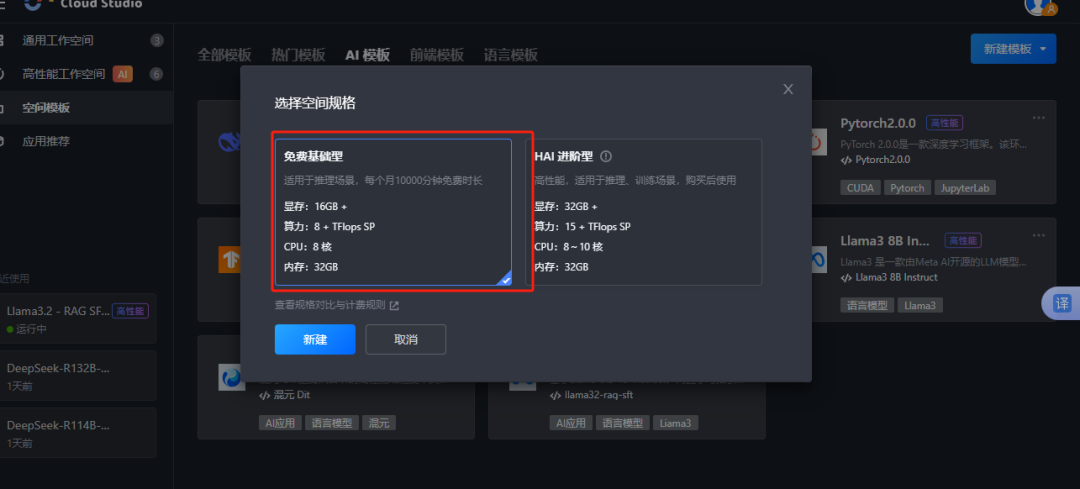
直接双击就可以打开、这个高性能环境已经做了相关的部署,不用从0开始搭建,对小白特别友好。
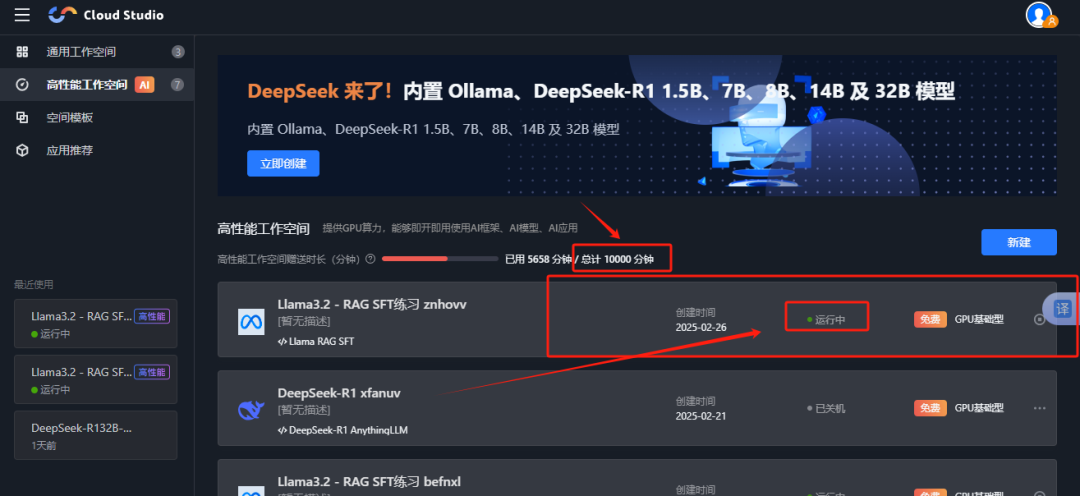
注意: 建议选择 Llama3.2 - RAG SFT服务器,这个服务空间大些。470G。
2、部署ComfyUI
ComfyUI是一个基于节点流程的Stable Diffusion(稳定扩散)操作界面,它将稳定扩散的流程拆分为各个节点,用户可通过自定义节点、拖拽连线实现精准的工作流定制与可靠复现,以完成更复杂的、自由度更高的图像生成工作。
手动部署特别麻烦,新手小白肯定会蒙圈。我这里使用ai来事大佬的ComfyUI的一键安装包aitools,自动完成安装部署。
1)下载安装包
aitool的下载地址:
国际:
https://github.com/aigem/aitools/
国内环境可用:
https://openi.pcl.ac.cn/niubi/aitools.git
https://gitee.com/fuliai/aitools.git
#任意选自一个地址下载下来安装。(在bash的终端状态下)
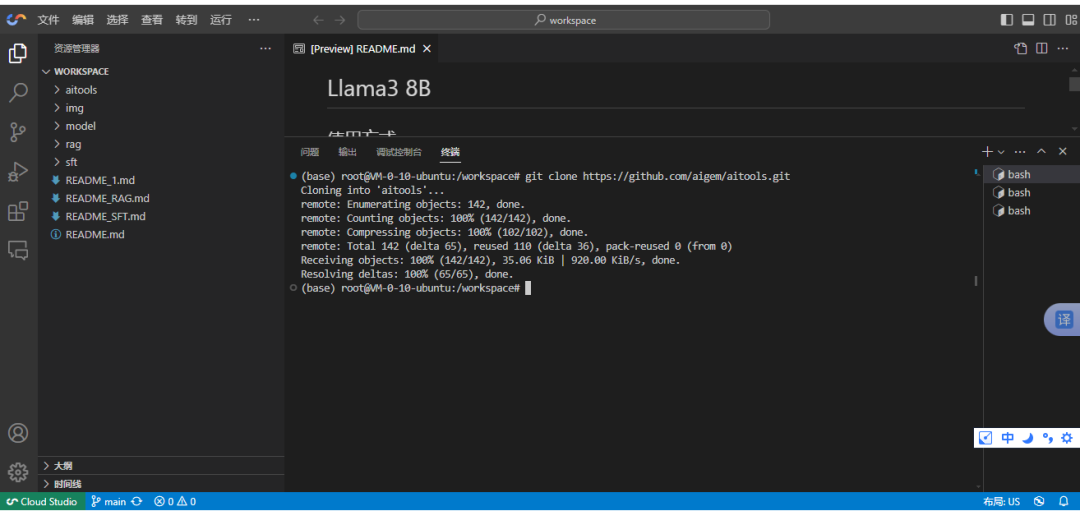
git clone https://github.com/aigem/aitools.git
cd aitools && git pull
#运行安装脚本:
bash aitools.sh
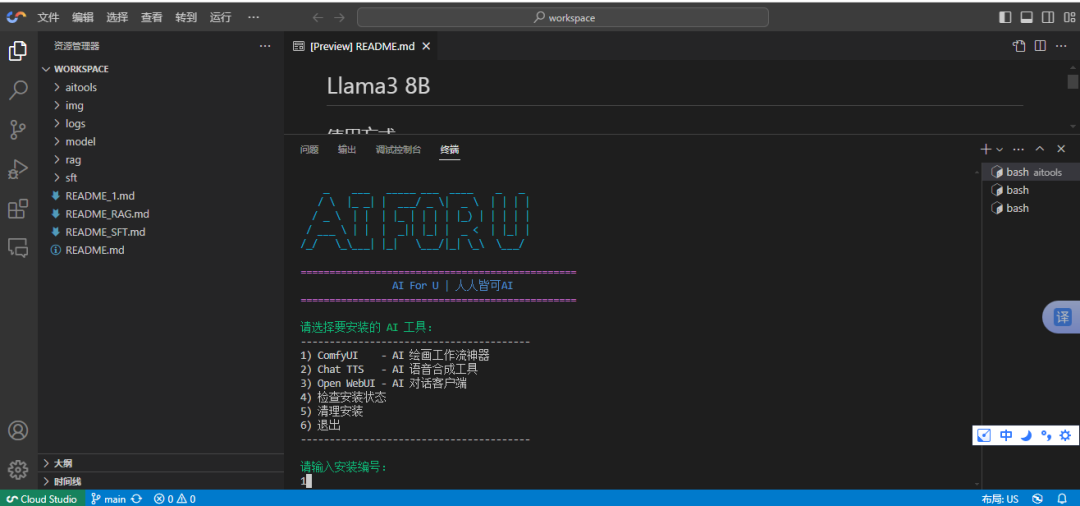
等候安装成功,就可以做接下来的工作。
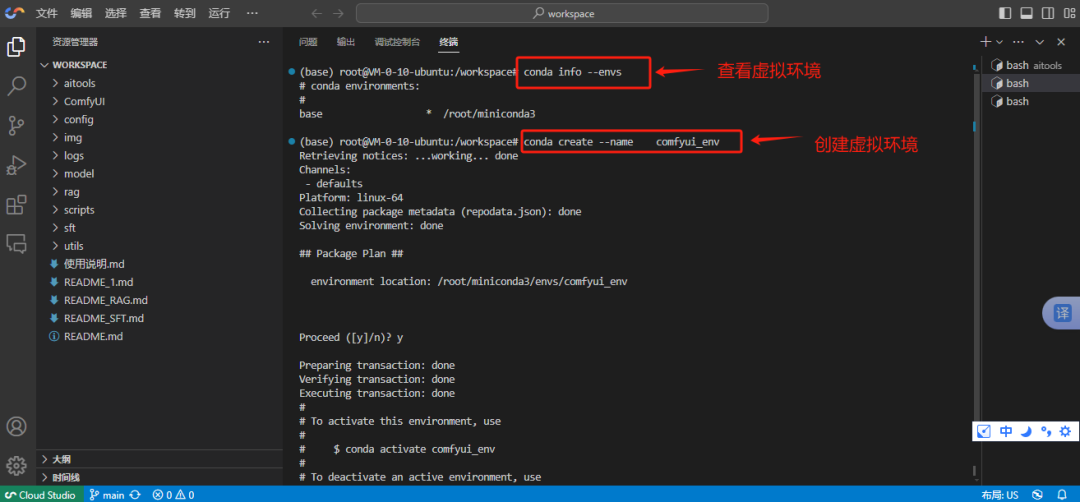
3、创建虚拟环境
#创建一个新的虚拟环境,以后安装节点时候使用,放置系统被搞屁了。
用 conda env list 或 conda info --envs 命令查看当前的虚拟环境。
#创建comfyui_env虚拟环境。 新开一个终端窗口,输入一下命令创建
conda create --name comfyui_env
#激活虚拟环境
conda activate comfyui_env
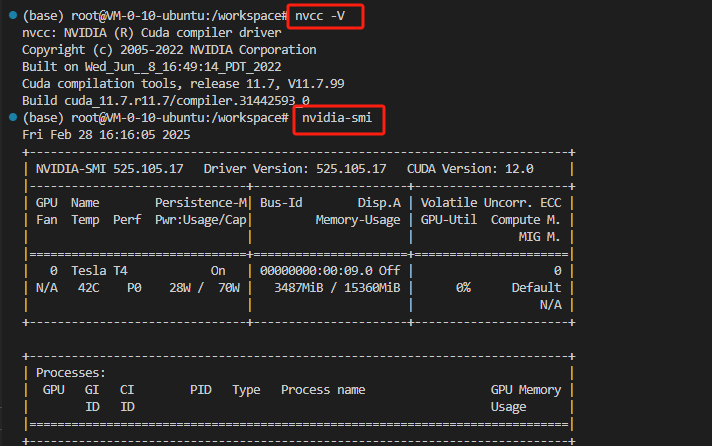
4、查看显卡与cuda相关信息
nvcc -V
nvidia-smi
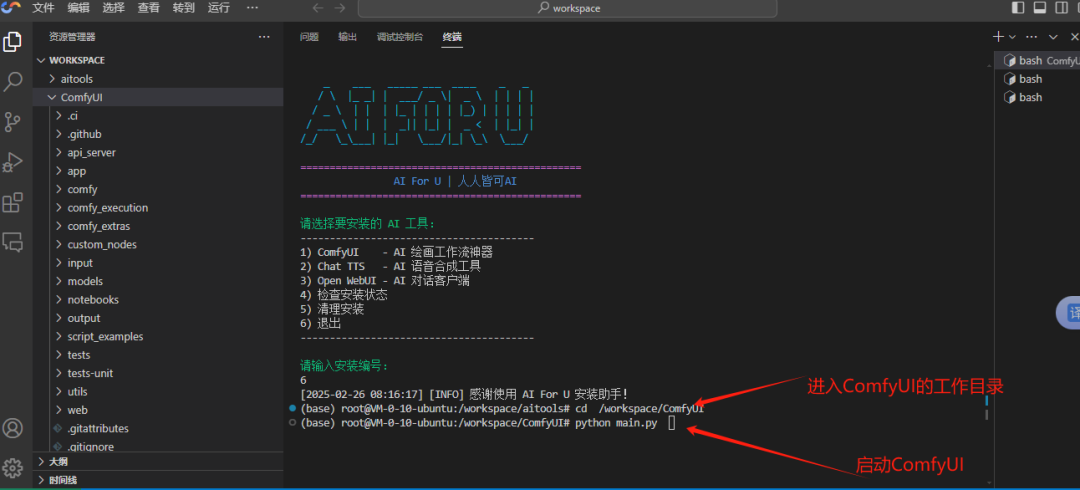
5、启动ComfyUI
#进入ComfyUI的安装目录
cd /workspace/ComfyUI
#启动ComfyUI程序
python main.py
出现 To see the GUI go to: http://127.0.0.1:8188 表示ComfyUI启动成功。
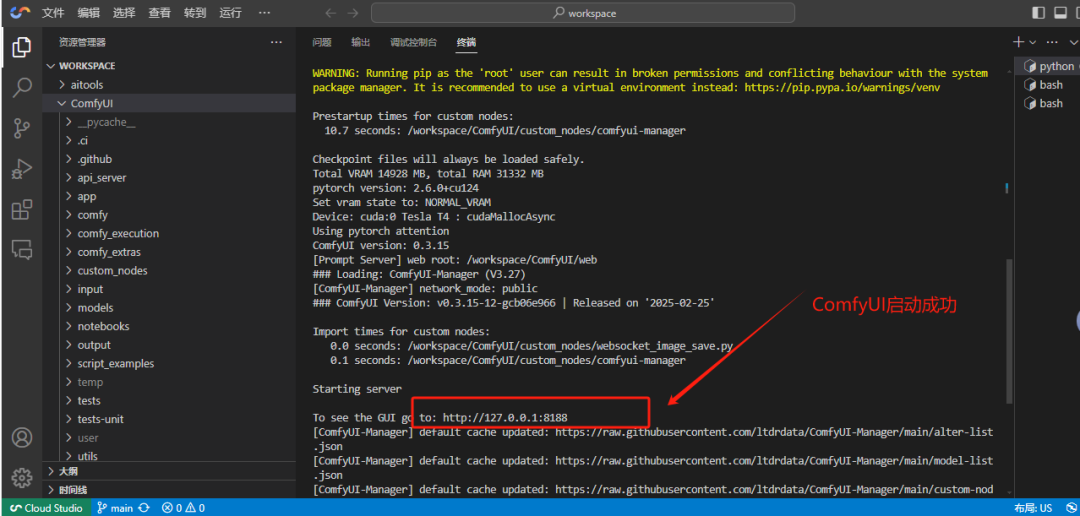
桉 ctrl+C 退出comfyUI。
6、用ngrok内网穿透
访问ngrok 网站https://dashboard.ngrok.com/signup,注册一个账号,通过邮箱激活。选择linux系统。复制配置代码(安装代码不需要了,在comfyUI的一键安装包已经安装了)。
复制配置代码:
ngrok config add-authtoken 2tLmEtp*************************88sMWo4 (做了隐藏替换)
# 请填写你注册的站好的配置代码。
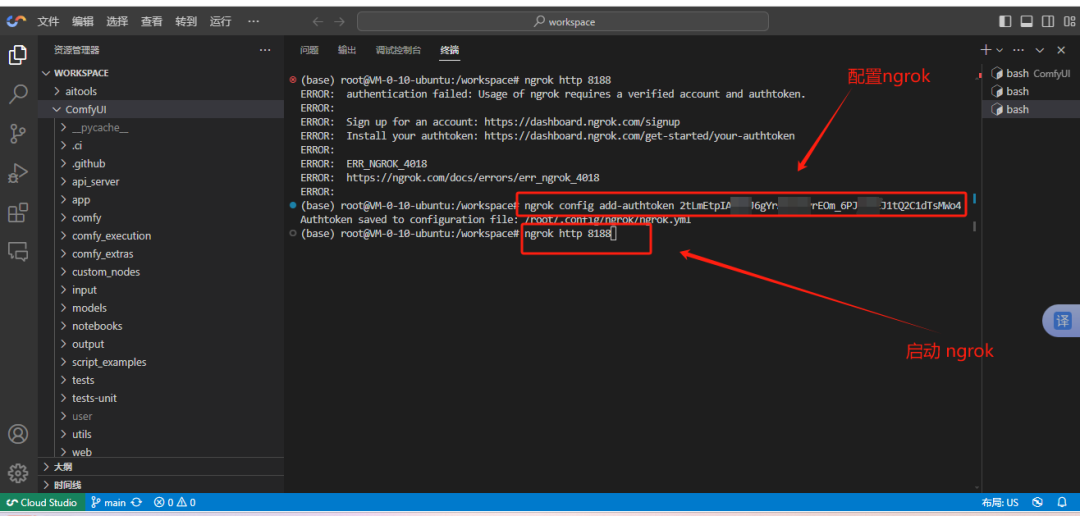
内网穿透:Ngrok http 8188|
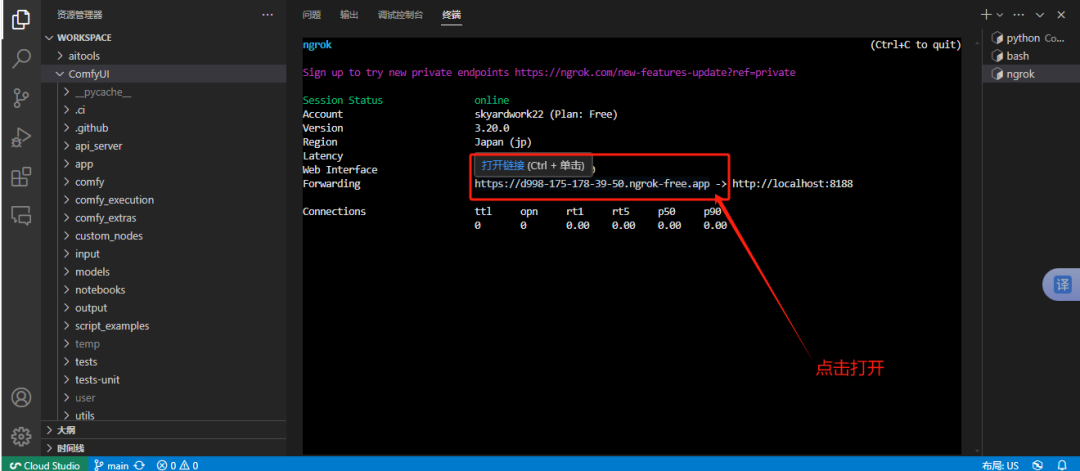
只要能打开comfyUI网站,表明内网穿透成功。
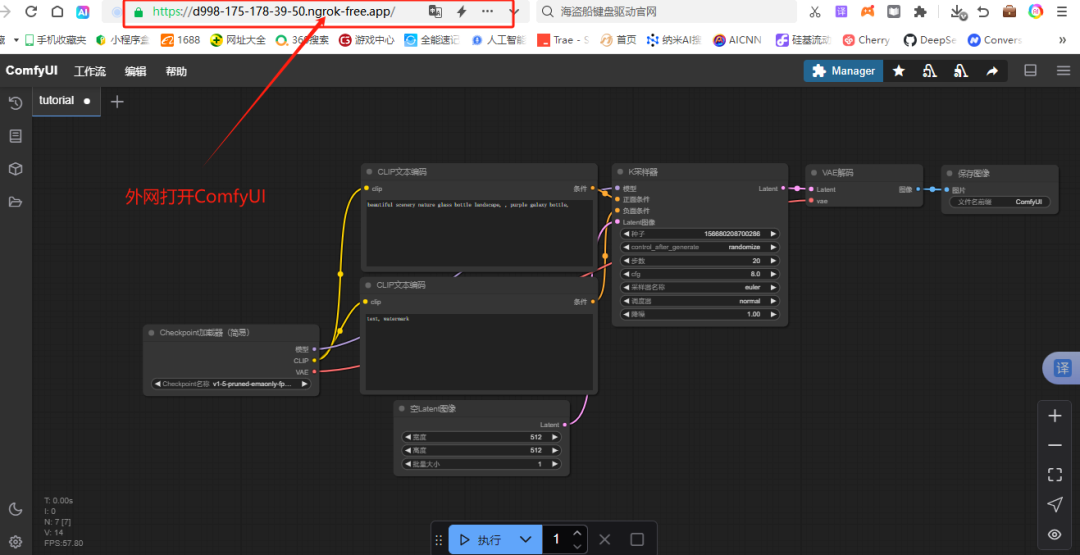
二、 在ComfyUI上部署Sonic数字人
🌟 第一步:安装必要插件节点
切换到 comfyui_env 虚拟环境下。安装相关节点,以防出错或者对系统环境出现破坏性冲突。
conda activate comfyui_env 。
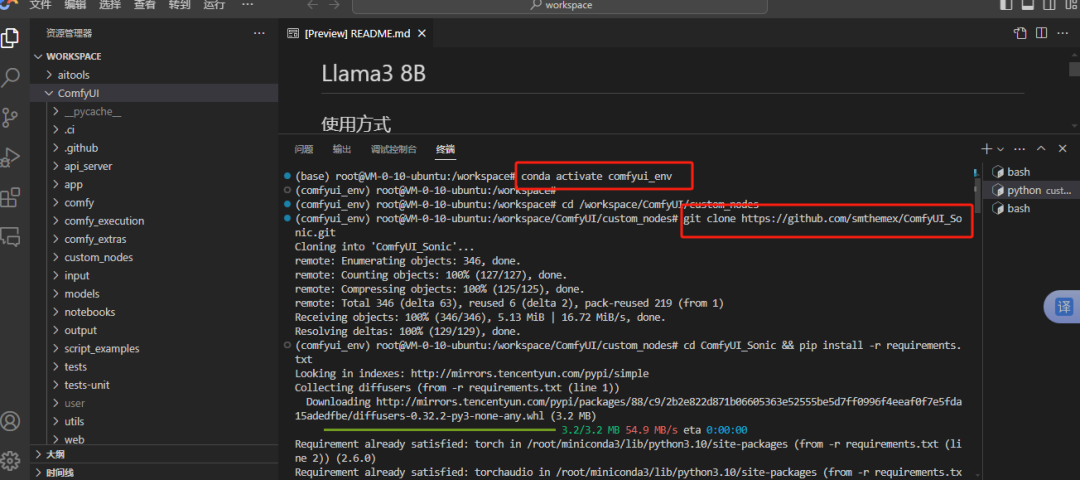
1. 安装Sonic核心节点
# 进入ComfyUI自定义节点目录
cd /workspace/ComfyUI/custom_nodes
# 克隆Sonic节点仓库
git clone https://github.com/smthemex/ComfyUI_Sonic.git
# 安装依赖(需在节点目录内执行)
cd ComfyUI_Sonic && pip install -r requirements.txt
等待安装,返回成功或者失败信息。如果失败,根据失败信息,分析原因,解决问题。直到安装成功、
2. 安装视频处理插件
# 返回自定义节点目录
cd /workspace/ComfyUI/custom_nodes
# 克隆ComfyUI-VideoHelperSuite 节点仓库
git clone https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite.git
# 安装依赖
cd ComfyUI-VideoHelperSuite
pip install -r requirements.txt
等待安装,返回成功或者失败信息。如果失败,根据失败信息,分析原因,解决问题。直到安装成功、
切换到一个新的终端,进入ComfyUI工作目录,启动ComfyUI,看看这两个节点是否能够正常加载。
cd /workspace/ComfyUI/
python main.py
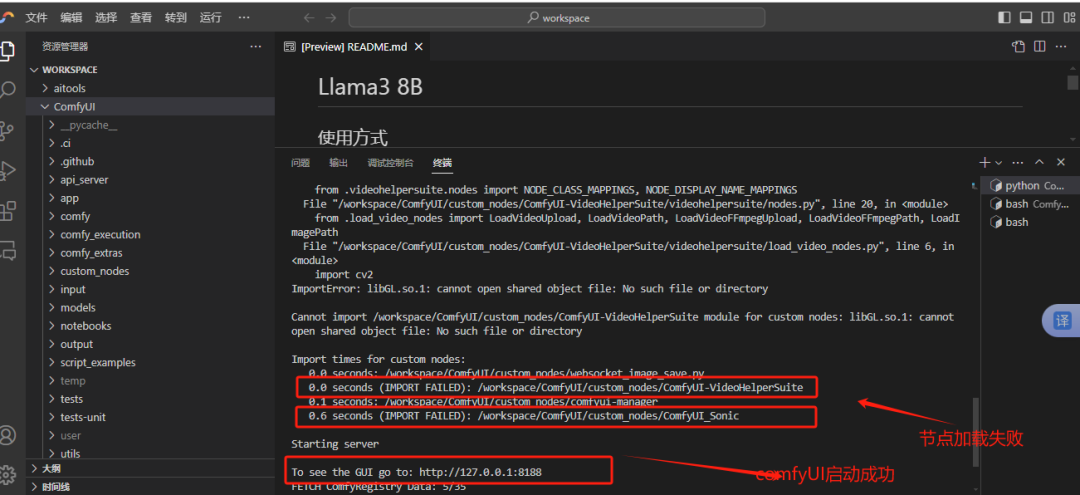
结果,ComfyUI_Sonic 和ComfyUI-VideoHelperSuite都没加载成功。有一些错误日志。复制错误日志到Deepskeek或者kimi里面。他们会给出解决方案,按照提示,一步一步的解决问题。
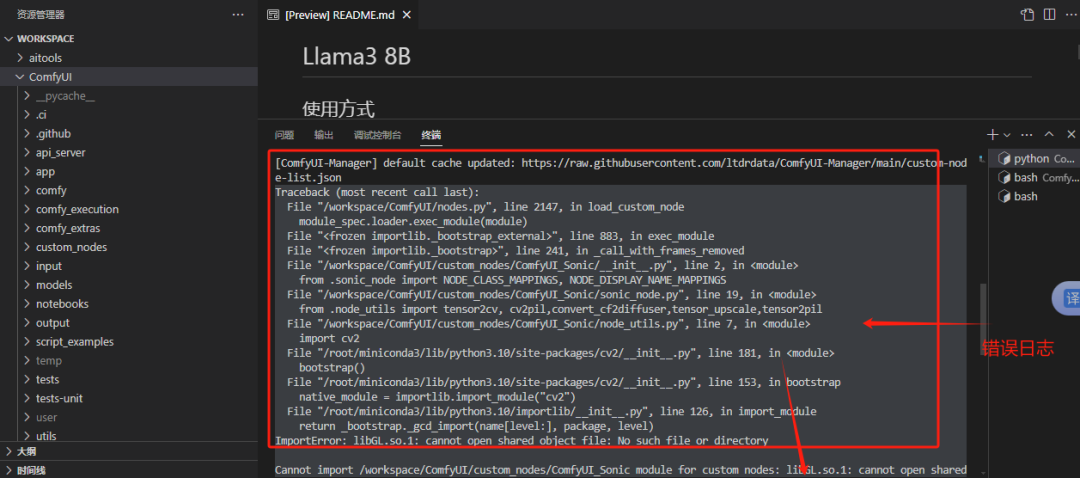
注意:sodu 命令要去掉,执行后面的命令代码。腾讯云Cloud Studio为了安全,不支持 sodu。
所以:sudo apt-get update 改为 apt-get update 。以此类推。
3、安装清理内存节点PurgeVRAM
git clone https://github.com/T8mars/comfyui-purgevram.git
4、安装MediaPlayer节点(ComfyUI-FFmpeg)
git clone https://github.com/MoonHugo/ComfyUI-FFmpeg.git
cd MediaPlayer
pip install -r requirements.txt
安装完成以后,重新启动ComfyUI,检查节点是否加载成功。没有成功,按照上面的操作继续去解决。
第二步:部署模型文件
1. 下载Sonic专用模型(文件不要放错位置)
# 进入 ComfyUI模型目录,
cd /workspace/ComfyUI/models/
# Sonic模型的目录结构
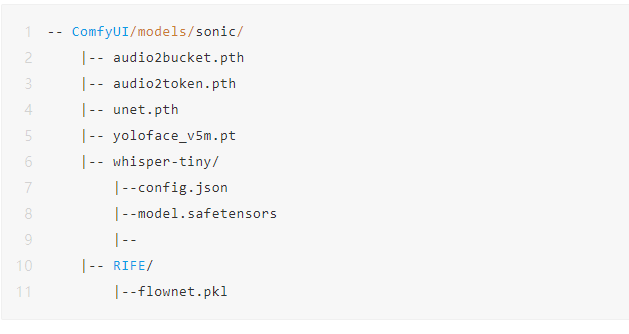
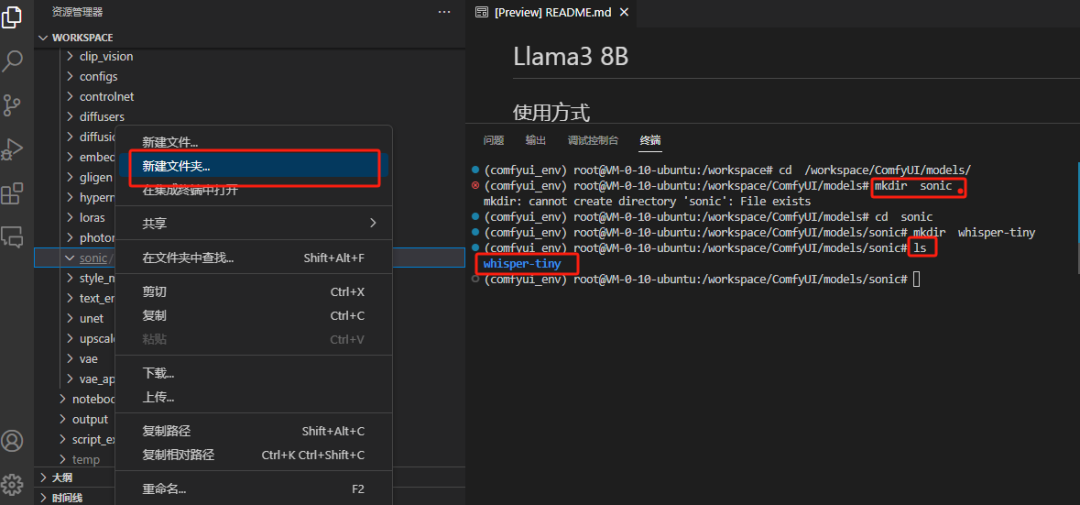
# 创建sonic目录,在sonic目录下,创建whisper-tiny目录,RIFE目录
mkdir sonic
cd sonic
mkdir whisper-tiny
mkdir RIFE
通过ls命令查看是否创建成功。(当然,也可以通过窗口的相应目录进行创建)
1)模型清单:
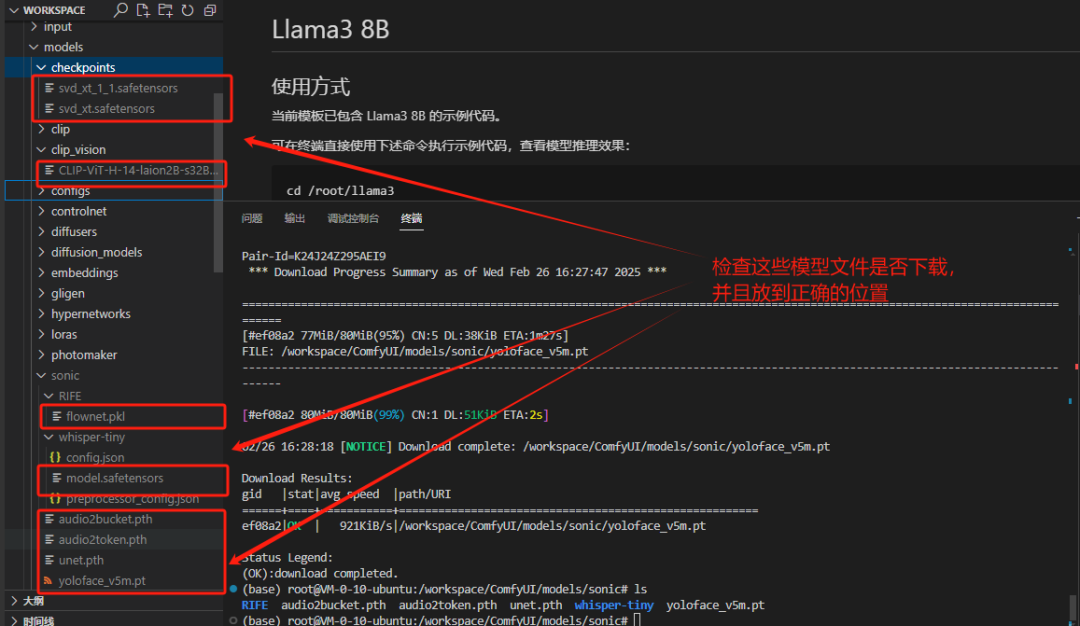
audio2bucket.pth、audio2token.pth、unet.pth、yoloface_v5m.pt 这些模型放入 /workspace/ComfyUI/models/sonic目录、
下载模型(在/workspace/ComfyUI/models/sonic下运行,一个命令运行一次):
wget https://hf-mirror.com/LeonJoe13/Sonic/resolve/main/Sonic/audio2bucket.pth
wget https://hf-mirror.com/LeonJoe13/Sonic/resolve/main/Sonic/audio2token.pth
wget https://hf-mirror.com/LeonJoe13/Sonic/resolve/main/yoloface_v5m.pt
aria2c -x 16 -s 16 -k 1M -o unet.pth https://hf-mirror.com/LeonJoe13/Sonic/resolve/main/Sonic/unet.pth
如果下载很慢,就结束任务,删除没有下载完
成的模型,换成 aria2c下载,例如 yoloface_v5m.pt:
aria2c -x 16 -s 16 -k 1M -o yoloface_v5m.pt https://hf-mirror.com/LeonJoe13/Sonic/resolve/main/yoloface_v5m.pt
aria2c -x 16 -s 16 -k 1M -o v1-5-pruned-emaonly-fp16.safetensors https://huggingface.co/Comfy-Org/stable-diffusion-v1-5-archive/resolve/main/v1-5-pruned-emaonly-fp16.safetensors
aria2c -x 16 -s 16 -k 1M -o v1-5-pruned-emaonly-fp16.safetensors https://hf-mirror.com/Comfy-Org/stable-diffusion-v1-5-archive/resolve/main/v1-5-pruned-emaonly-fp16.safetensors
# unet.pth 模型比较大,使用 aria2c来下载。
2)进入/workspace/ComfyUI/models/sonic/RIFE 目录
下载 flownet.pkl模型
aria2c -x 16 -s 16 -k 1M -o flownet.pkl https://hf-mirror.com/LeonJoe13/Sonic/resolve/main/RIFE/flownet.pkl
3)进入/workspace/ComfyUI/models/sonic/whisper-tiny/目录
下载config.json,preprocessor_config.json和model.safetensors文件
wget https://hf-mirror.com/openai/whisper-tiny/resolve/main/model.safetensors
wget https://hf-mirror.com/openai/whisper-tiny/resolve/main/config.json
wget https://hf-mirror.com/openai/whisper-tiny/resolve/main/preprocessor_config.json
下载完成检查一下位置是否放置正确。
2. 下载SVD动态模型
键入 /workspace/ComfyUI/models/checkpoints/ 目录。
下载模型文件:svd_xt.safetensors 或 svd_xt_1_1.safetensors
aria2c -x 16 -s 16 -k 1M -o svd_xt_1_1.safetensors https://www.modelscope.cn/models/cjc1887415157/stable-video-diffusion-img2vid-xt-1-1/resolve/master/svd_xt_1_1.safetensors
aria2c -x 16 -s 16 -k 1M -o svd_xt.safetensors "https://www.modelscope.cn/models/AI-ModelScope/stable-video-diffusion-img2vid-xt/resolve/master/svd_xt.safetensors"
3. 下载CLIP视觉模型
进入/workspace/ComfyUI/models/目录
下载模型文件:CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors
用 魔搭(modelscope)下载CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors 模型。
# 安装modelscope 模块
pip install modelscope
# 下载CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors 模型到/workspace/ComfyUI/models/clip_vision/目录
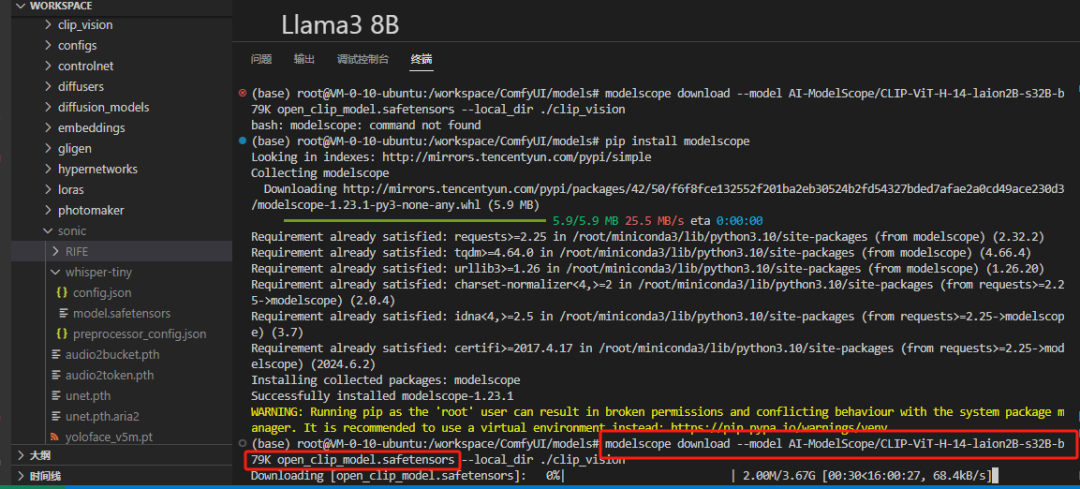
modelscope download --model AI-ModelScope/CLIP-ViT-H-14-laion2B-s32B-b79K open_clip_model.safetensors --local_dir ./clip_vision
下载完成,记得改名。把 open_clip_model.safetensors 改名为 CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors 。
可以多个终端同时下载哦。
4、如果不会安装节点,请下载我的整合包
夸克网盘「ComfyUI-sonic」
https://pan.quark.cn/s/d08701401c6e 提取码:F18M
安装好ComfyUI知乎, 把整合节点里面 custom_nodes.zip文件下载,上传到服务器。通过unzip custom_nodes.zip解压到 /workspace/ComfyUI/中,确保所有文件都是放在custom_nodes目录下面、再启动ComfyUI,看看所有节点是否正常启动,没有启动的节点,进入该目录,用pip install -r requirements.txt安装一下,然后再启动查看。
⚙️ 第三步:配置工作流
1. 获取工作流
夸克网盘「ComfyUI-sonic」https://pan.quark.cn/s/d08701401c6e 提取码:F18M
下载工作流文件.json文件和测试素材文件夹,存在本地电脑。
2. 导入工作流
运行ComfyUI,通过ngrok穿透,打开ComfyUI网站界面。点击菜单--工作流--打开。选择本地下载的 工作流sonic新版-new222.json。
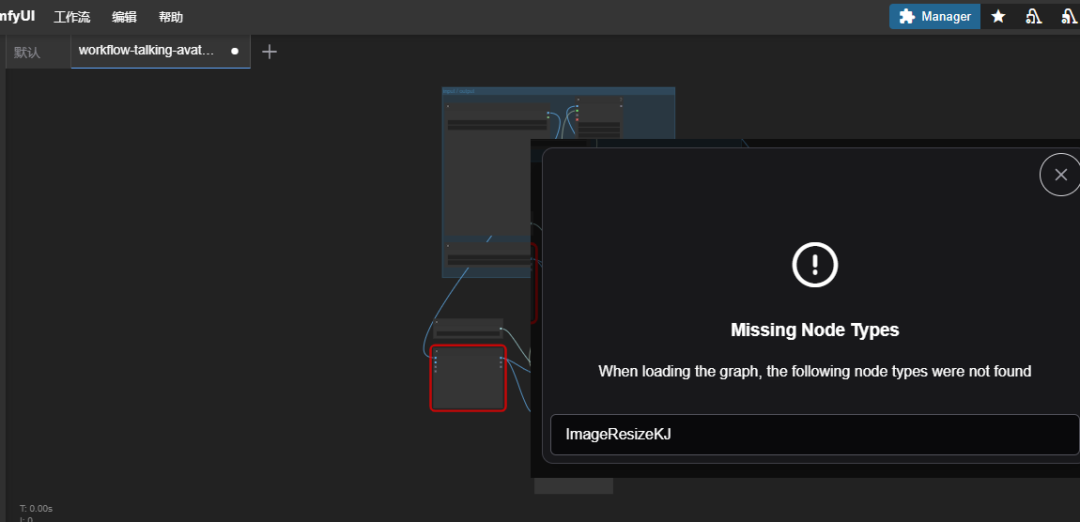
如果出现右缺失节点,系统会提示,打开mananger,安装缺失节点即可。
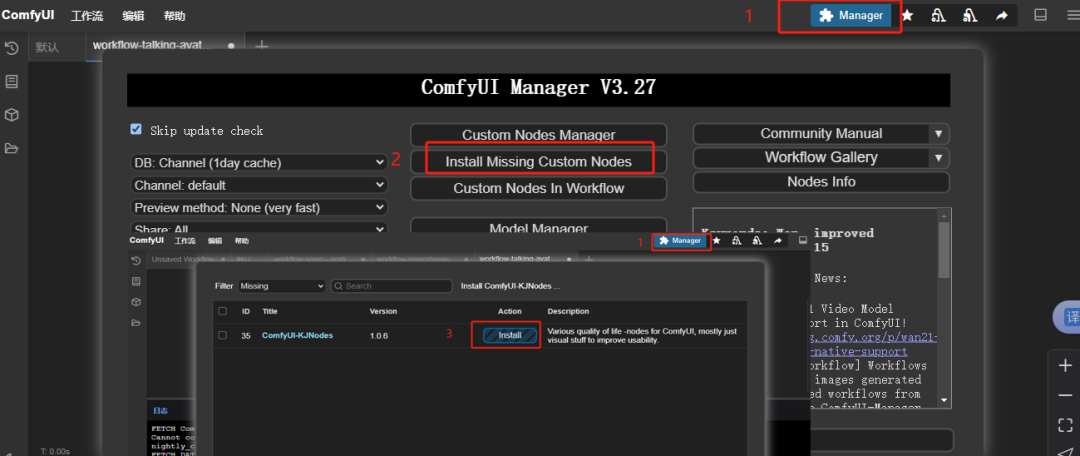
3. 关键参数设置
模型选择:检查SVD模型名称,sonic模型,CLIP视觉模型 是否放对目录。
🚀 第四步:生成数字人视频
点工作流上的upload上传音频文件:将准备好的.wav或.mp3文件上传至工作流,然后选中
点工作流上的upload上传图片文件:将准备好的.jpg或.png文件上传至 工作流,然后选中
选择检查相应的模型,图片大小
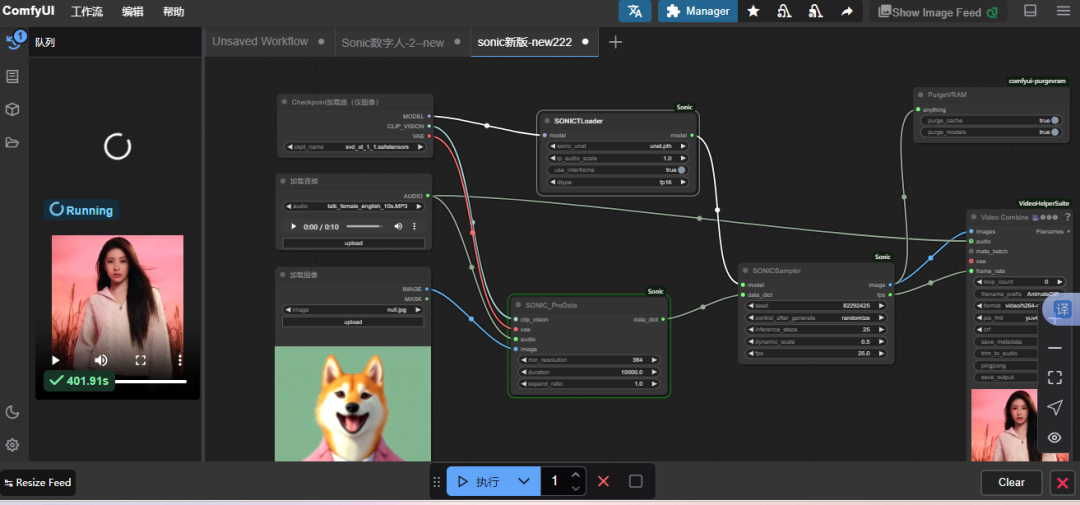
点击“ 执行”按钮运行流程
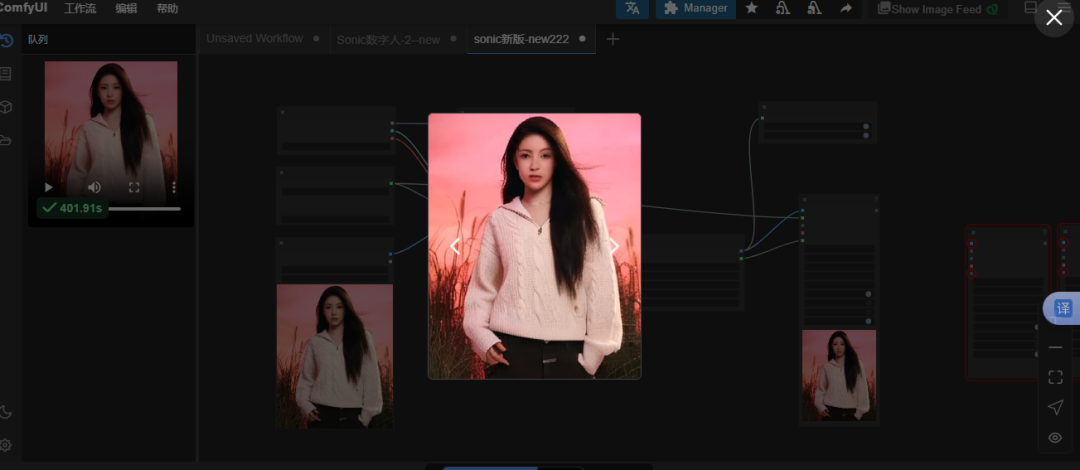
查看结果:在outputs目录查找生成的视频文件(可能需要等待5-30分钟)
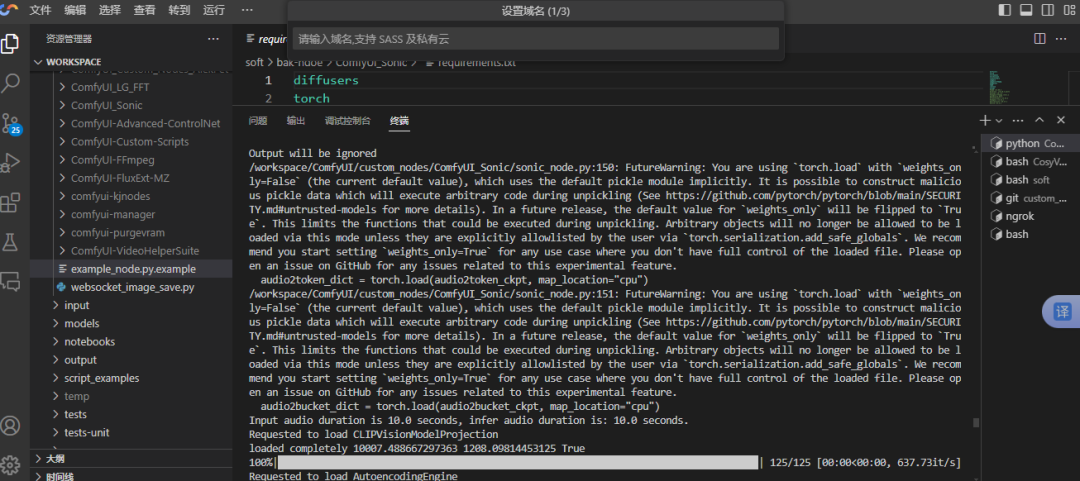
服务器终端运行日志和进度:
效果
,时长00:09
动物嘴不会动,大家再试试。
,时长00:09
第五步:❓ 常见问题排查
节点不显示:重启ComfyUI服务 → 刷新浏览器
模型加载失败:检查文件名是否含空格/特殊字符,路径是否严格匹配
显存不足:在SVD模型参数中降低frames数量或分辨率。也可以改小图片尺寸,默认是512. 可以降低到384或者更小,再运行。
✅ 完成以上步骤后,你的AI数字人即可根据音频生成口型同步的虚拟形象视频!

















 588
588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









