







1. 部署
- 下载开源项目LLaMA-Efficient-Tuning,部署路径/home/ubuntu/workspace/projects/tuning/qwen/tools/Efficient
- 安装accelerate或者deepspeed
- 模型部署,我们模型已经部署好在服务器。
2. 数据生成
- 数据格式,我们用的是指令监督微调sft。
[
{
"instruction": "请根据以下快捷任务生成快捷指令:",
"question": "如果我系上了主驾驶安全带并且车辆挡位是D挡,就自动给我开车窗和加热座椅。",
"answer": "{\"condition\": [\"主驾驶安全带\", \"车辆挡位\"], \"action\": [\"主驾车窗\", \"主驾座椅加热\"], \"task\": \"如果我系上了主驾驶安全带并且车辆挡位是D挡,就自动给我开车窗和加热座椅。\"}",
"history": [],
"id": 0
},
{
"instruction": "请根据以下快捷任务生成快捷指令:",
"question": "当我系好安全带并且车挡在D挡时,帮我把车窗打开并且把座椅加热打开。",
"answer": "{\"condition\": [\"主驾驶安全带\", \"车辆挡位\"], \"action\": [\"主驾车窗\", \"主驾座椅加热\"], \"task\": \"当我系好安全带并且车挡在D挡时,帮我把车窗打开并且把座椅加热打开。\"}",
"history": [],
"id": 1
}
]
- 生成json格式数据,放到data目录下:/home/ubuntu/workspace/projects/tuning/qwen/tools/Efficient/data
- 在/home/ubuntu/workspace/projects/tuning/qwen/tools/Efficient/data/dataset.info里配置好数据路径:
"train_data": {
"file_name": "train_data.json",
"columns": {
"prompt": "instruction",
"query": "question",
"response": "answer",
"history": "history"
},
"stage": "sft"
}
3. lora微调
-
python src/train_web.py启动平台,在浏览器上登录http://10.133.121.2:7860/。
-
在平台上进行配置
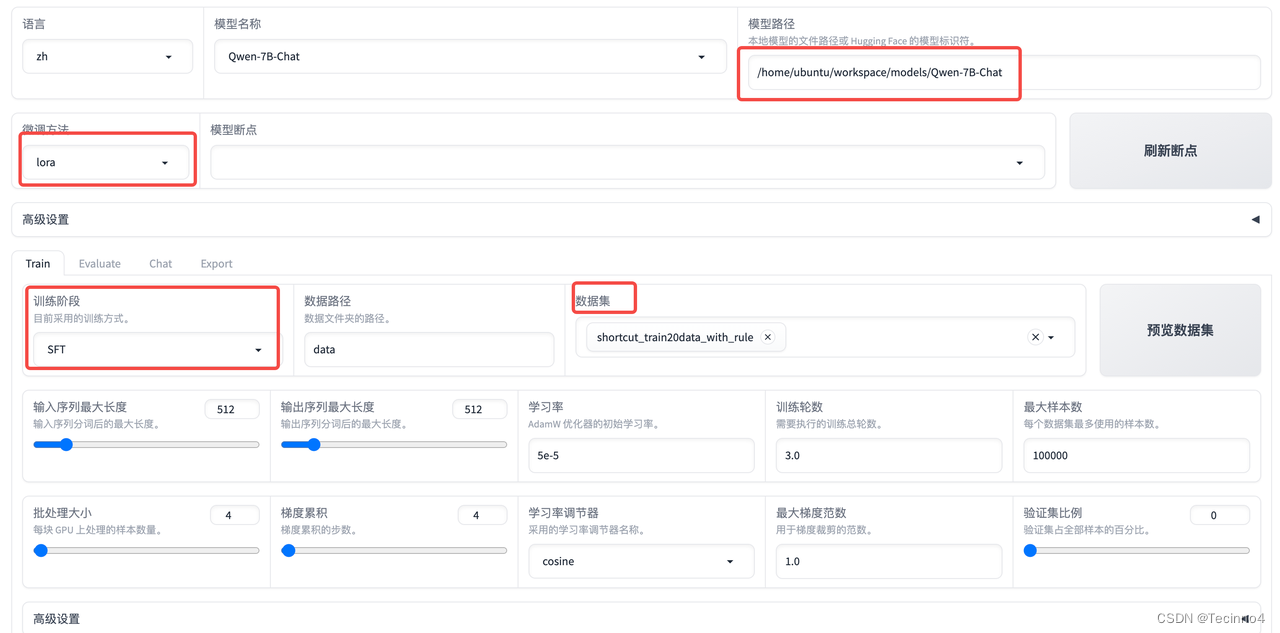
-
调节微调参数,batchsize、epoch、Gradient accumulation、LoRA Dropout等,可以先用默认的试试。
-
开始微调start后,等待结果
-
选择chat,加载之前微调的checkpoint,load model,load结束后就可以开始测试对话了。
-
可以启动api_demo.py进行api部署。
-
评估和导出模型也可以在平台上进行操作。
4. DPO训练
- DPO训练步骤
1. 获取测试结果中NG的case。
2. 将case结果进行调整生成OK的结果。
3. 生成DPO数据,告诉模型两个输出哪个更好(好的例子是根据NG的例子调整的),格式如下:
[
{
"instruction": "",
"input": "",
"output": [
相对好的结果,
相对差的结果
]
}
]
[
{
"instruction": "创建一个将文本转换为乐谱的脚本。",
"input": "",
"output": [
"不幸的是,将文本转换成乐谱并不是一个简单的过程,因为没有固定的规则可以将单词、字母或句子映射到特定的音符、节奏或旋律。将文本转化为有意义的作品需要音乐知识、创造力和诠释。\n\n但是,您可以使用以下一种方法从文本生成音乐:\n\n1. 为文本中的每个字母分配一个音符。可以通过多种方式分配音符,例如根据 ASCII 数字表示或使用预先确定的映射将每个字符或字母表与音高等级(C、D、E、F、G、A 或 B)相匹配系统。\n\n```蟒蛇\n文字=“你好世界”\n注意映射 = {'a': 'C4', 'b': 'D4', 'c': 'E4', 'd': 'F4', 'e': 'G4', 'f': 'A4 ', 'g': 'B4', 'h': 'C5', 'i': 'D5', 'j': 'E5',\n'k':'F5','l':'G5','m':'A5','n':'B5','o':'C6','p':'D6','q ':'E6','r':'F6','s':'G6','t':'A6','u':'B6',\n'v': 'C7', 'w': 'D7', 'x': 'E7', 'y': 'F7', 'z': 'G7'}\n\n音符顺序 = []\n\n对于 text.lower() 中的字母:\n 如果音符映射中的字母:\n note sequence.append(注意映射[字母])\n elif 字母 == \" \":\n 注意 sequence.append(\"R\")\n\n打印(音符顺序)\n```\n\n2. 为这个音符序列分配一个节奏。这可以通过将音符分组为短语或使用各种 NLP 技术从文本的句法结构中确定节拍、速度和短语长度来完成。\n\n```蟒蛇\n节奏映射= {“1”:“4”,“2”:“4”,“3”:“4”,“4”:“4”,“5”:“4”,“6”:“4 \",\"7\": \"4\", \"8\": \"4\", \"9\": \"8\", \"0\": \"8\",\n“”:“2r”}\n节奏序列",
"我能做到。"
]
}
]
- DPO训练指令
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py\
--stage dpo \
--model_name_or_path /home/ubuntu/workspace/models/Baichuan-13B-Chat \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template baichuan \
--dataset_dir data \
--dataset shortcut_dpo \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 5.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side right \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target W_pack \
--resume_lora_training False \
--output_dir saves/Baichuan-13B-Chat/lora/baichuan_dpo \
--fp16 True \
--dpo_beta 0.1 \
--plot_loss True
5. 全参微调
- 安装deepspeed,配置deepspeed config
deepspeed2.json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"steps_per_print": 1e5
}
- 微调参数
python src/train_bash.py \
--stage sft \
--model_name_or_path /home/ubuntu/workspace/models/Baichuan-13B-Chat \
--do_train True \
--overwrite_cache True \
--finetuning_type full \
--template baichuan \
--dataset_dir data \
--dataset shortcut_train20data_with_rule \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 6.0 \
--max_samples 100000 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 6 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side right \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target W_pack \
--resume_lora_training False \
--output_dir saves/Baichuan-13B-Chat/full/baichuan_full20 \
--fp16 True \
--overwrite_output_dir True \
--plot_loss True
- deepspeed+微调参数进行多卡全参微调
deepspeed --num_gpus 4 src/train_bash.py --deepspeed /home/ubuntu/workspace/projects/tuning/qwen/data/deepspeed.json \
--stage sft \
--model_name_or_path /home/ubuntu/workspace/models/Qwen-7B-Chat \
--do_train True \
--overwrite_cache True \
--finetuning_type full \
--template chatml \
--dataset_dir data \
--dataset shortcut_train20data_with_rule \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 4.0 \
--max_samples 100000 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 6 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side right \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target c_attn \
--resume_lora_training False \
--output_dir saves/Qwen-7B-Chat/full/qwen_full_train20 \
--fp16 True \
--overwrite_output_dir True \
--plot_loss True
- 训练过程
6. 多卡训练
- accelerate
1. https://huggingface.co/docs/accelerate/basic_tutorials/launch
2. 配置好accelerate config后直接accelerate launch xxx.py - torchrun
1. MIXED_PRECISION=“fp16” torchrun --nproc_per_node=4 xxx.py
2. nproc_per_node是进程节点个数,我是4个GPU就设置4 - deepspeed
deepspeed --num_gpus 4 xxx.py --deepspeed ./deepspeed2.json \














 2839
2839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









