






1. 背景
Transformer是一个利用注意力机制来提高模型训练速度的模型,可以说是完全基于自注意力机制的一个深度学习模型,因为它适用于并行化计算,和它本身模型的复杂程度导致它在精度和性能上都要高于之前流行的RNN循环神经网络。
你可以简单理解为它是一个黑盒子,当我们在做文本翻译任务是,我输入进去一个中文,经过这个黑盒子之后,输出来翻译过后的英文。
2. 组成和结构
Transformer由两部分组成:Encoder 和 Decoder。
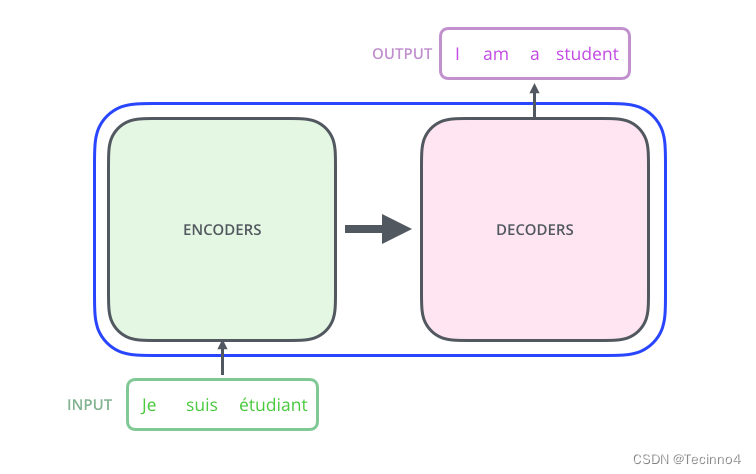
当我输入一个文本的时候,该文本数据会先经过一个叫Encoders的模块,对该文本进行编码,然后将编码后的数据再传入一个叫Decoders的模块进行解码,解码后就得到了翻译后的文本,对应的我们称Encoders为编码器,Decoders为解码器。
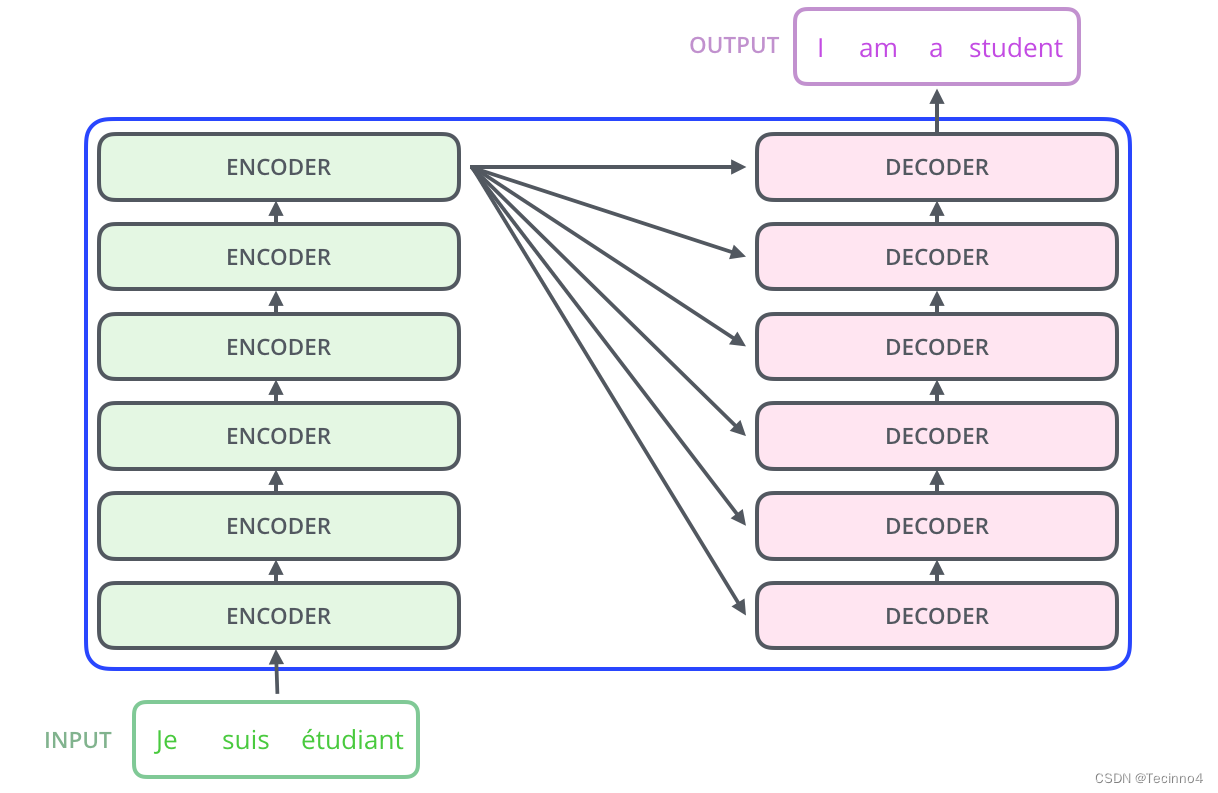
一般情况下,Encoders里边有n个小编码器,同样的,Decoders里边有n个小解码器。
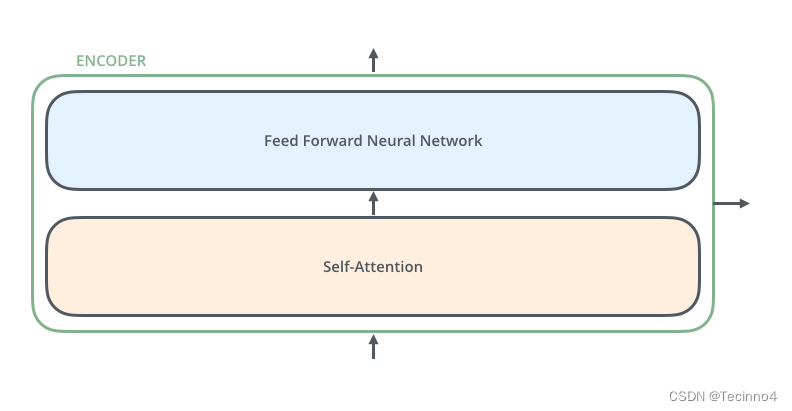
encoder的结构是一个自注意力机制加上一个前馈神经网络。
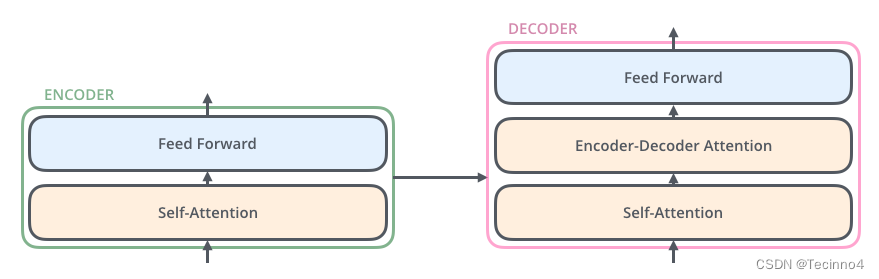
decoder也有encoder的两层,但在它们之间是一个注意力层,它帮助解码器专注于输入句子的相关部分。
self-attention结构:
-
首先,self-attention的输入就是词向量,即整个模型的最初的输入是词向量的形式。那自注意力机制呢,顾名思义就是自己和自己计算一遍注意力,即对每一个输入的词向量,我们需要构建self-attention的输入。在这里,transformer首先将词向量乘上三个矩阵,得到三个新的向量,之所以乘上三个矩阵参数而不是直接用原本的词向量是因为这样增加更多的参数,提高模型效果。对于输入X1(机器),乘上三个矩阵后分别得到Q1,K1,V1,同样的,对于输入X2(学习),也乘上三个不同的矩阵得到Q2,K2,V2。
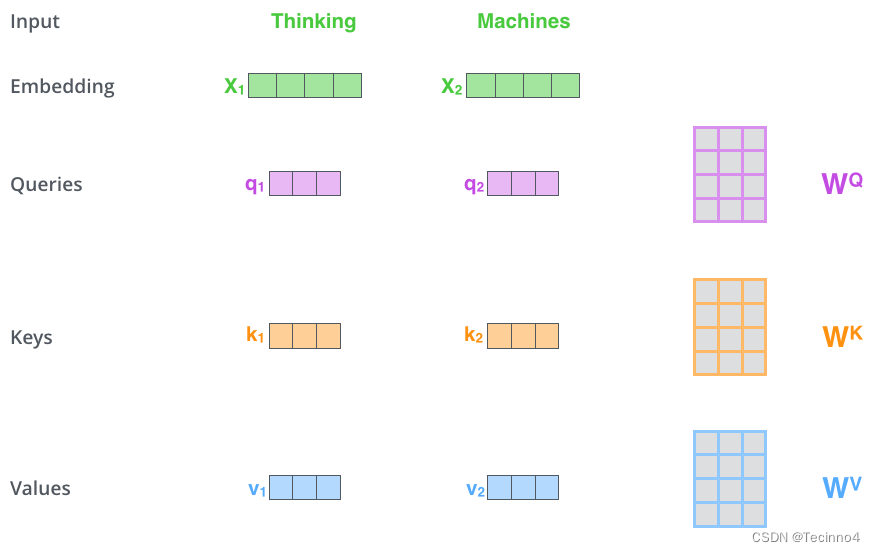
-
那接下来就要计算注意力得分了,这个得分是通过计算Q与各个单词的K向量的点积得到的。我们以X1为例,分别将Q1和K1、K2进行点积运算,假设分别得到得分112和96。
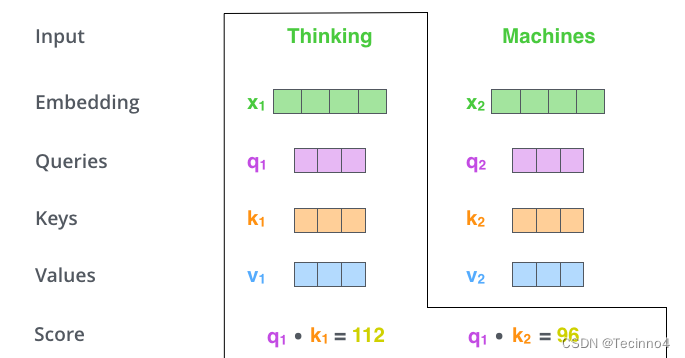
3. 将得分分别除以一个特定数值8(K向量的维度的平方根,通常K向量的维度是64)这能让梯度更加稳定。
4. 将上述结果进行softmax运算得到,softmax主要将分数标准化,使他们都是正数并且加起来等于1。
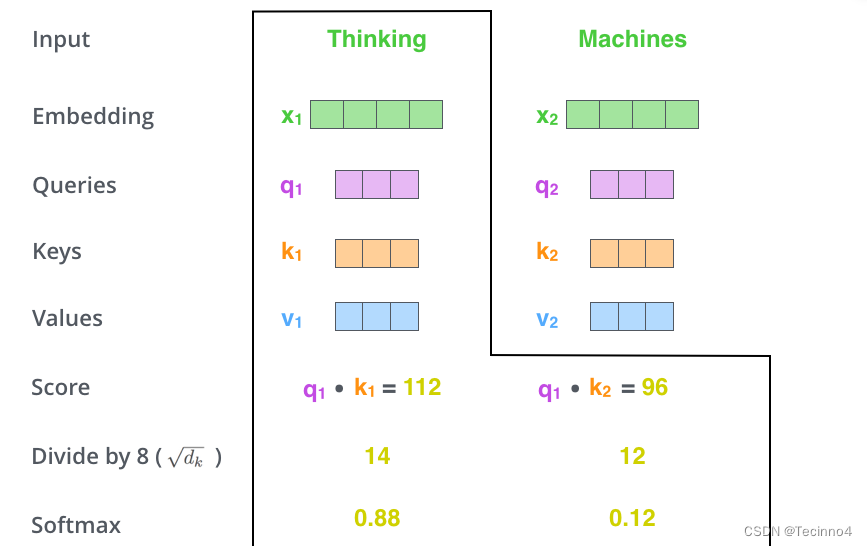
-
将V向量乘上softmax的结果得到Z,这个思想主要是为了保持我们想要关注的单词的值不变,而掩盖掉那些不相关的单词(例如将他们乘上很小的数字)。
-
将带权重的各个V向量加起来,至此,产生在这个位置上(第一个单词)的self-attention层的输出,其余位置的self-attention输出也是同样的计算方式。
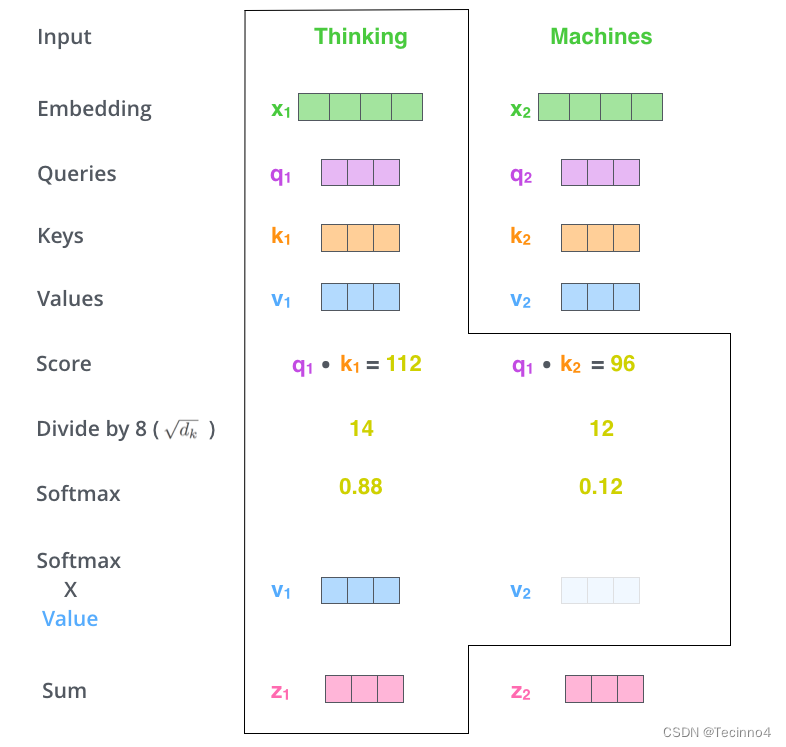
-
将上述的过程总结为一个公式就可以用下图表示:
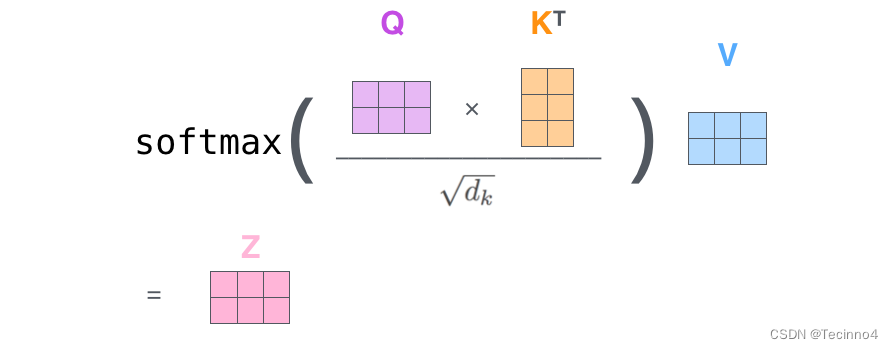
多头注意力:
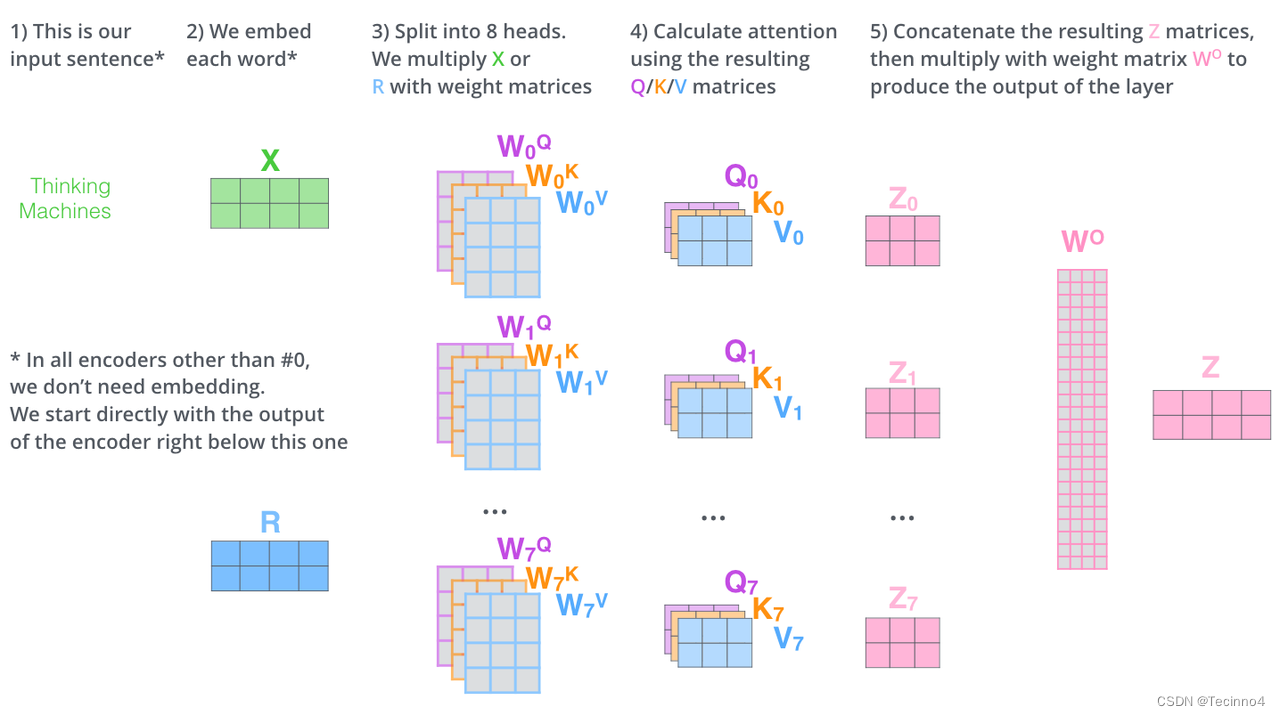
上述说到的encoder是对输入(机器学习)进行编码,使用的是自注意力机制+前馈神经网络的结构,同样的,在decoder中使用的也是同样的结构。也是首先对输出(machine learning)计算自注意力得分,不同的地方在于,进行过自注意力机制后,将self-attention的输出再与Decoders模块的输出计算一遍注意力机制得分,之后,再进入前馈神经网络模块。
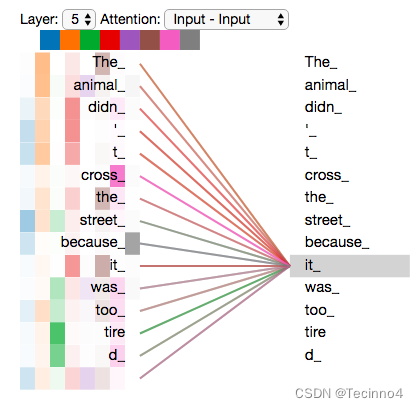
Transformer中确实没有考虑顺序信息,那怎么办呢,我们可以在输入中做手脚,把输入变得有位置信息不就行了,那怎么把词向量输入变成携带位置信息的输入呢?
我们可以给每个词向量加上一个有顺序特征的向量,发现sin和cos函数能够很好的表达这种特征,所以通常位置向量用以下公式来表示:
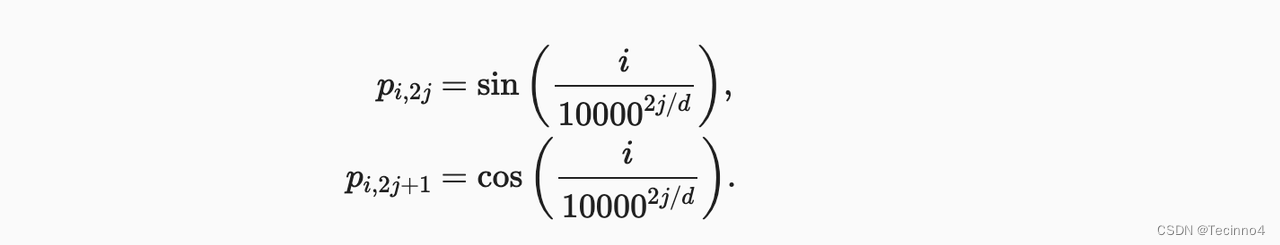
3. 代码实现
![[Image]](https://img-blog.csdnimg.cn/52d1001e66464df4b4175330a0697c10.png)
- 基于位置的前馈网络
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
class PositionWiseFFN(nn.Module):
"""基于位置的前馈网络"""
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,
**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)#全连接层
self.relu = nn.ReLU()#激活函数
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)#全连接层
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
ffn = PositionWiseFFN(4, 4, 8)
ffn.eval()#评估模式
ffn(torch.ones((2, 3, 4)))[0]
tensor([[ 0.1720, 0.0399, -0.2363, -0.3180, 0.6054, -0.4444, -0.1393, -0.1631],
[ 0.1720, 0.0399, -0.2363, -0.3180, 0.6054, -0.4444, -0.1393, -0.1631],
[ 0.1720, 0.0399, -0.2363, -0.3180, 0.6054, -0.4444, -0.1393, -0.1631]],
grad_fn=<SelectBackward0>)
-
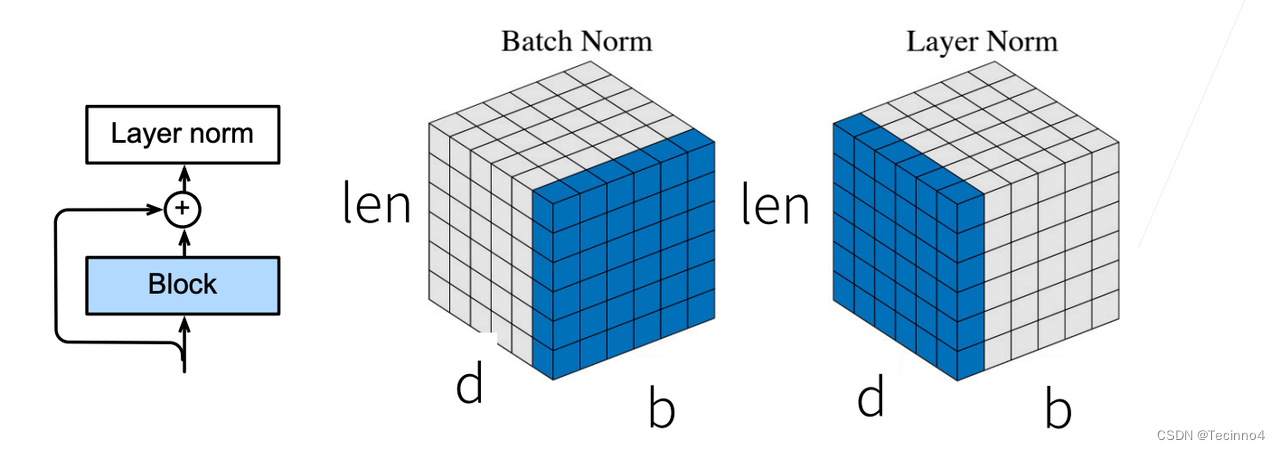
残差连接和层规范化
import torch from torch import nn class AddNorm(nn.Module): """残差连接后进行层规范化""" def __init__(self, normalized_shape, dropout, **kwargs): super(AddNorm, self).__init__(**kwargs) self.dropout = nn.Dropout(dropout) self.ln = nn.LayerNorm(normalized_shape) def forward(self, X, Y): return self.ln(self.dropout(Y) + X) add_norm = AddNorm([3, 4], 0.5) add_norm.eval() add_norm(torch.ones((2, 3, 4)), torch.ones((2, 3, 4))).shape #结果 torch.Size([2, 3, 4])
层归一化对样本里面的每一个元素进行归一化,批量归一化对每个特征里面的元素进行归一化(不适合NLP)。
- 编码器
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
class EncoderBlock(nn.Module):
"""Transformer编码器块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = d2l.MultiHeadAttention(num_hiddens, num_heads, dropout,
use_bias)#多头注意力
self.addnorm1 = AddNorm(norm_shape, dropout)#残差连接后进行层规范化
self.ffn = PositionWiseFFN(
ffn_num_input, ffn_num_hiddens, num_hiddens)#基于位置的前馈网络
self.addnorm2 = AddNorm(norm_shape, dropout)#残差连接后进行层规范化
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))
X = torch.ones((2, 100, 24))#生成元素都是1,形状为[2,100,24]的张量。
print(type(X))
valid_lens = torch.tensor([3, 2])#valid_lens表示每个批次中的序列的有效长度,第一个序列的有效长度为3,第二个序列的有效长度为2。
encoder_blk = EncoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5)
encoder_blk.eval()
encoder_blk(X, valid_lens).shape
#结果
<class 'torch.Tensor'>
torch.Size([2, 100, 24])
多头注意力:
![[Image]](https://img-blog.csdnimg.cn/90bba4b0522c45259b76b24726074796.png)
#编码器
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
class TransformerEncoder(d2l.Encoder):
"""Transformer编码器"""
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
EncoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, use_bias))
def forward(self, X, valid_lens, *args):
# 因为位置编码值在-1和1之间,
# 因此嵌入值乘以嵌入维度的平方根进行缩放,
# 然后再与位置编码相加。
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[
i] = blk.attention.attention.attention_weights
return X
encoder = TransformerEncoder(
200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5)
encoder.eval()
#valid_lens表示每个批次中的序列的有效长度,第一个序列的有效长度为3,第二个序列的有效长度为2。
encoder(torch.ones((2, 100), dtype=torch.long), valid_lens).shape
#结果
torch.Size([2, 100, 24])
Transformer编码器输出的形状是(批量大小,时间步数目,num_hiddens/token维度)。
-
解码器
#解码器 class DecoderBlock(nn.Module): """解码器中第i个块""" def __init__(self, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, i, **kwargs): super(DecoderBlock, self).__init__(**kwargs) self.i = i self.attention1 = d2l.MultiHeadAttention(num_hiddens, num_heads, dropout) self.addnorm1 = AddNorm(norm_shape, dropout) self.attention2 = d2l.MultiHeadAttention(num_hiddens, num_heads, dropout) self.addnorm2 = AddNorm(norm_shape, dropout) self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens) self.addnorm3 = AddNorm(norm_shape, dropout) def forward(self, X, state): enc_outputs, enc_valid_lens = state[0], state[1] # 训练阶段,输出序列的所有词元都在同一时间处理, # 因此state[2][self.i]初始化为None。 # 预测阶段,输出序列是通过词元一个接着一个解码的, # 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示 if state[2][self.i] is None: key_values = X else: key_values = torch.cat((state[2][self.i], X), axis=1) state[2][self.i] = key_values if self.training: batch_size, num_steps, _ = X.shape # dec_valid_lens的开头:(batch_size,num_steps), # 其中每一行是[1,2,...,num_steps] dec_valid_lens = torch.arange( 1, num_steps + 1, device=X.device).repeat(batch_size, 1) else: dec_valid_lens = None # 自注意力 X2 = self.attention1(X, key_values, key_values, dec_valid_lens) Y = self.addnorm1(X, X2) # 编码器-解码器注意力。 # enc_outputs的开头:(batch_size,num_steps,num_hiddens) Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens) Z = self.addnorm2(Y, Y2) return self.addnorm3(Z, self.ffn(Z)), state decoder_blk = DecoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5, 0) decoder_blk.eval() X = torch.ones((2, 100, 24)) state = [encoder_blk(X, valid_lens), valid_lens, [None]] decoder_blk(X, state)[0].shape #结果 torch.Size([2, 100, 24])
现在我们构建了由num_layers个DecoderBlock实例组成的完整的Transformer解码器。最后,通过一个全连接层计算所有vocab_size个可能的输出词元的预测值。解码器的自注意力权重和编码器解码器注意力权重都被存储下来,方便日后可视化的需要。
class TransformerDecoder(d2l.AttentionDecoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
DecoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, i))
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
return [enc_outputs, enc_valid_lens, [None] * self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range (2)]
for i, blk in enumerate(self.blks):
X, state = blk(X, state)
# 解码器自注意力权重
self._attention_weights[0][
i] = blk.attention1.attention.attention_weights
# “编码器-解码器”自注意力权重
self._attention_weights[1][
i] = blk.attention2.attention.attention_weights
return self.dense(X), state
@property
def attention_weights(self):
return self._attention_weights
- 训练
#训练
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = TransformerEncoder(
len(src_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
decoder = TransformerDecoder(
len(tgt_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
loss 0.028, 5773.9 tokens/sec on cpu
![[Image]](https://img-blog.csdnimg.cn/e479335dde70473d84e78132b3665bfd.png)
- 测试
#测试
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est mouillé ., bleu 0.658
i'm home . => je suis chez moi ., bleu 1.000
- 注意力权重
#显示注意力权重分布
d2l.show_heatmaps(
enc_attention_weights.cpu(), xlabel='Key positions',
ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],
figsize=(7, 3.5))
![[Image]](https://img-blog.csdnimg.cn/2c390787114d4eb0bb955df7895702c9.png)
-
拓展研究
-
自我反省
1. 当提问者对llm提出质疑,在这一轮对话中,llm可以正确的修正回答,但是在结束对话后,这些修正后的结果并没有被llm记住。
2. 为了让llm不断改善输出,应该收集所有llm回答不好的对话,并且让llm对这段对话进行调整,给出正确的答案。
3. 如何识别这些对话呢,比较笨的方法就是在对话结束一段时间后,让llm对这段内容进行分析,判断是否为有问题的,这一步需要一些数据进行训练,保证llm不会判断出错。拿到这些有问题他的对话后,再让llm对对话进行修正(可能需要微调),给出一正确的回答。 -
强化记忆
1. 人类去回想一段记忆时,如果记忆不清晰,会重新翻阅资料去强化记忆。但是大模型无法认知自己回答的问题是否完整,所以无法自发的去强化记忆。
2. 所以可以使用固定流程,每次有人提问,llm就根据这次提问查找到相关的数据,提取这些数据,再次训练,这样可以保证用户关注的领域有更大的准确率。 -
动态记忆
1. 传统的训练和评估都是分开的,评估的时候冻结所有参数并且去掉噪音,不能进行训练;训练的时候会不断调整参数,持续很长一段时间,这个时候模型是不能进行测试和使用的。
2. 但是人类的记忆和回忆是可以同时进行的,或者说是切换特别快。
3. 这种记忆和回忆快速穿插的好处,就是可以持续的记住一小部分知识,然后一步步堆叠起来完成一个大型任务。假如llm有这种能力,那么提问者可以先让llm记住一部分知识,然后在下个对话中让他借助上次记住的知识完成一个新的任务,特别是复杂任务,可以借助这种能力在多轮对话中进行拆解,从而完成复杂任务。
4. 如何实现动态记忆呢,参考lora的底秩自适应技术,可以增加一些动态layer:adapt_layer,adapt_layer与llm里面特定的layer进行残差链接,并且在llm评估模式下,adapt_layer同样可以更新权重。lora的权重如下:
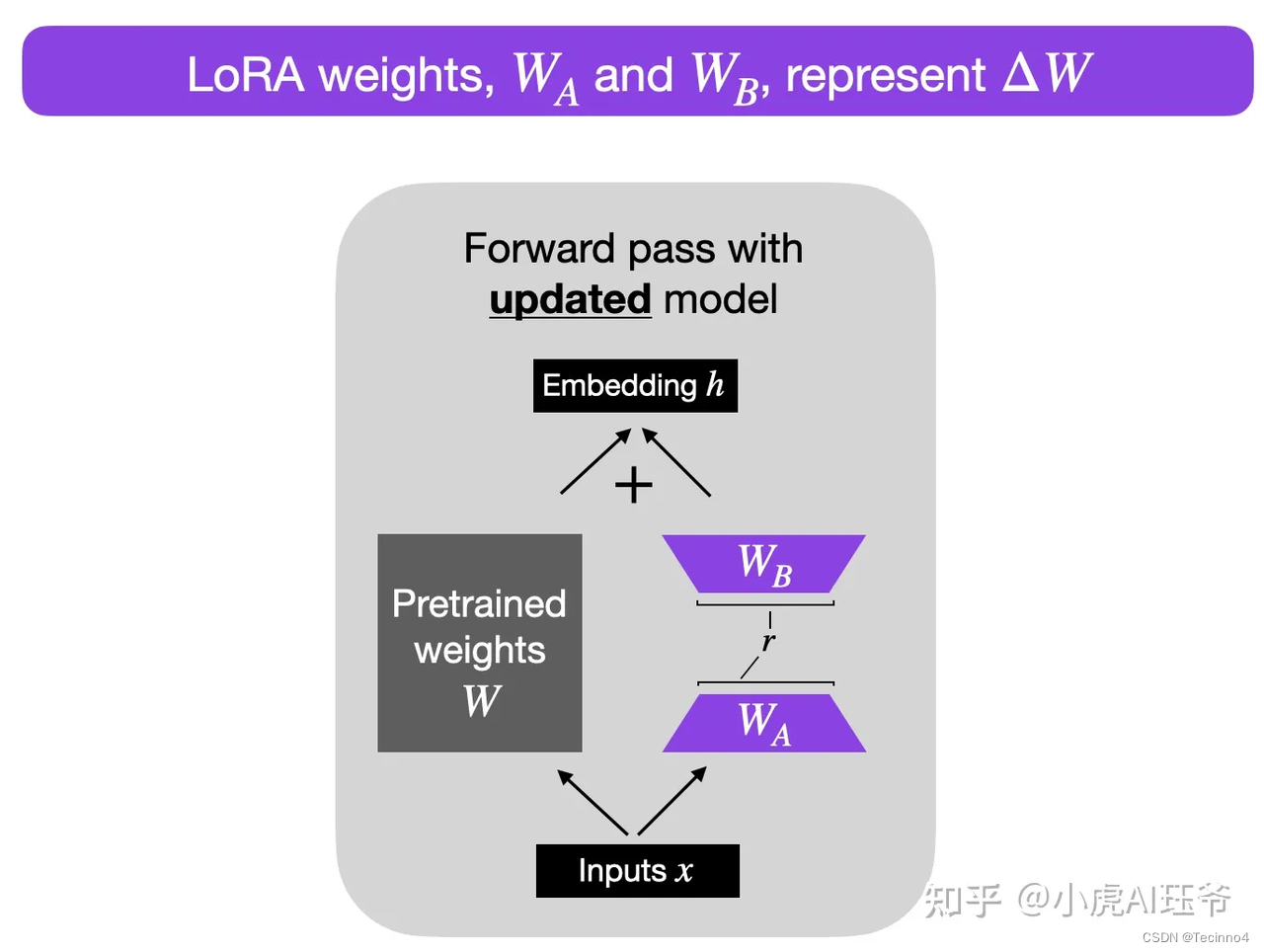
- 那数据的格式应该是怎么样的呢,首先不是所有的数据都需要记忆,要让llm记住,就必须有特定的prompt,例如:‘请一直记住我说的这些内容’。
- 那训练的模式应该是pretrain还是fine-tuning















 640
640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









