







2021SC@SDUSC
三、SSD训练过程:
源码如下
def vgg(cfg, i, batch_norm=False):
'''
该代码参考vgg官网的代码
'''
layers = []
in_channels = i
for v in cfg:
# 正常的 max_pooling
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
# ceil_mode = True, 上采样使得 channel 75-->38
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
# update in_channels
in_channels = v
# max_pooling (3,3,1,1)
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
# 新添加的网络层 1024x3x3
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
# 新添加的网络层 1024x1x1
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
# 结合到整体网络中
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
# 代码测试
if __name__ == "__main__":
base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
'512': [],
}
vgg = nn.Sequential(*vgg(base['300'], 3))
x = torch.randn(1,3,300,300)
print(vgg(x).shape) #(1, 1024, 19, 19)
jaccard overlap 计算示意图(其实就是IOU,叫法不同而已):
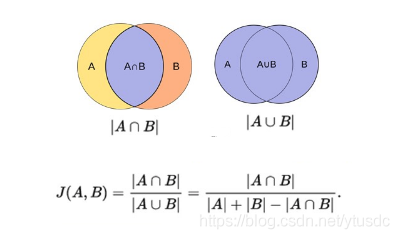
图12 jaccard overlap
然后看一张训练流程图,比较清晰明了:
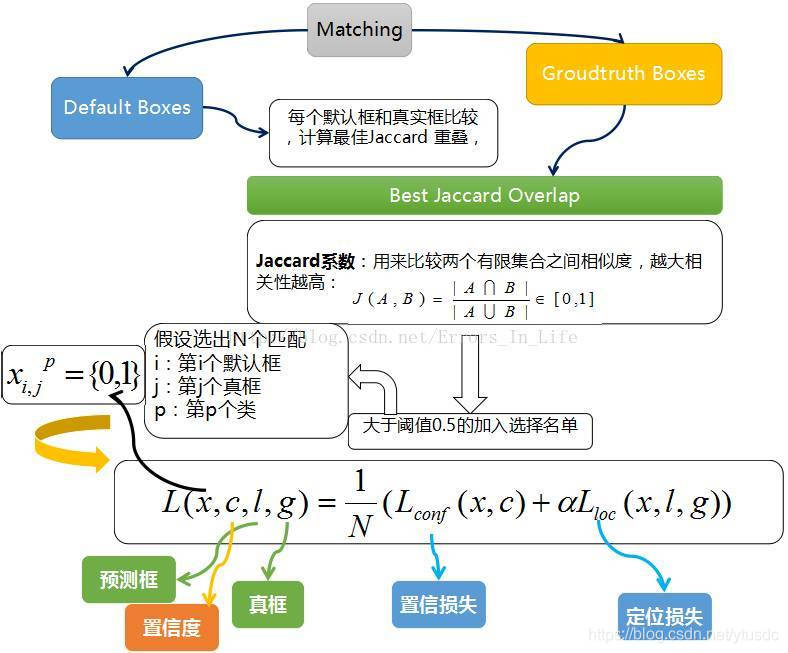
图13
(1)每一个 prior box 经过Jaccard系数计算和真实框的相似度。
(2)阈值只有大于 0.5 的才可以列为候选名单;假设选择出来的是N个匹配度高于百分之五十的框。
(3)我们令 i 表示第 i 个默认框,j 表示第 j 个真实框,p表示第p个类。那么 表示 第 i 个 prior box 匹配到 第 j 个 ground truth box ,并且这个ground truth box的 类别是p,若不匹配的话,则=0 。
(4)总的目标损失函数(objective loss function)为 localization loss(loc) 与 confidence loss(conf) 的加权求和。
损失函数 Loss计算:
总体目标损失函数定位损失(loc)和置信度损失(conf)的加权和:
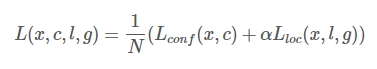
对于SSD,虽然paper中指出采用了所谓的“multibox loss”,但是可以看到与常见的 Object Detection模型的目标函数相同,SSD算法的目标函数分为两部分:计算相应的default box与目标类别的confidence loss以及相应的location loss(位置回归)。其中N是匹配到GT(Ground Truth)的prior box数量,如果N=0,则将损失设为0;而 α 参数用于调整confidence loss和location loss之间的比例,默认 α=1。
SS
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2462
2462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









